Transformer DPUs
Transformer DPUs
Transformers contain the core processing logics to transform the input data to the output data in desired data structure, schema and format. Extractors and loaders covered in the previous sections, only deal with data input and output most of the time.
They can accept one or more input data from extractors or transformers and produce one or more output data for transformers or loaders.
 Transformation is a rather abstract concept. Any operation applied to data can be considered a transformation and wrapped into a transformer DPU, which does not necessarily modify the data.
Transformation is a rather abstract concept. Any operation applied to data can be considered a transformation and wrapped into a transformer DPU, which does not necessarily modify the data.
It can be compressing and decompressing data, subsetting data, enriching data with external services, mapping data to a different model, and more. Data can be processed by one transformer supporting all required functionalities, or by several transformers in a chain to achieve a complicated goal.
PoolParty UnifiedViews provides DPUs to work with files, structured, semi-structured and unstructured data.
Please refer to the respective topics for detailed descriptions:
Excel to CSV
Excel to CSV
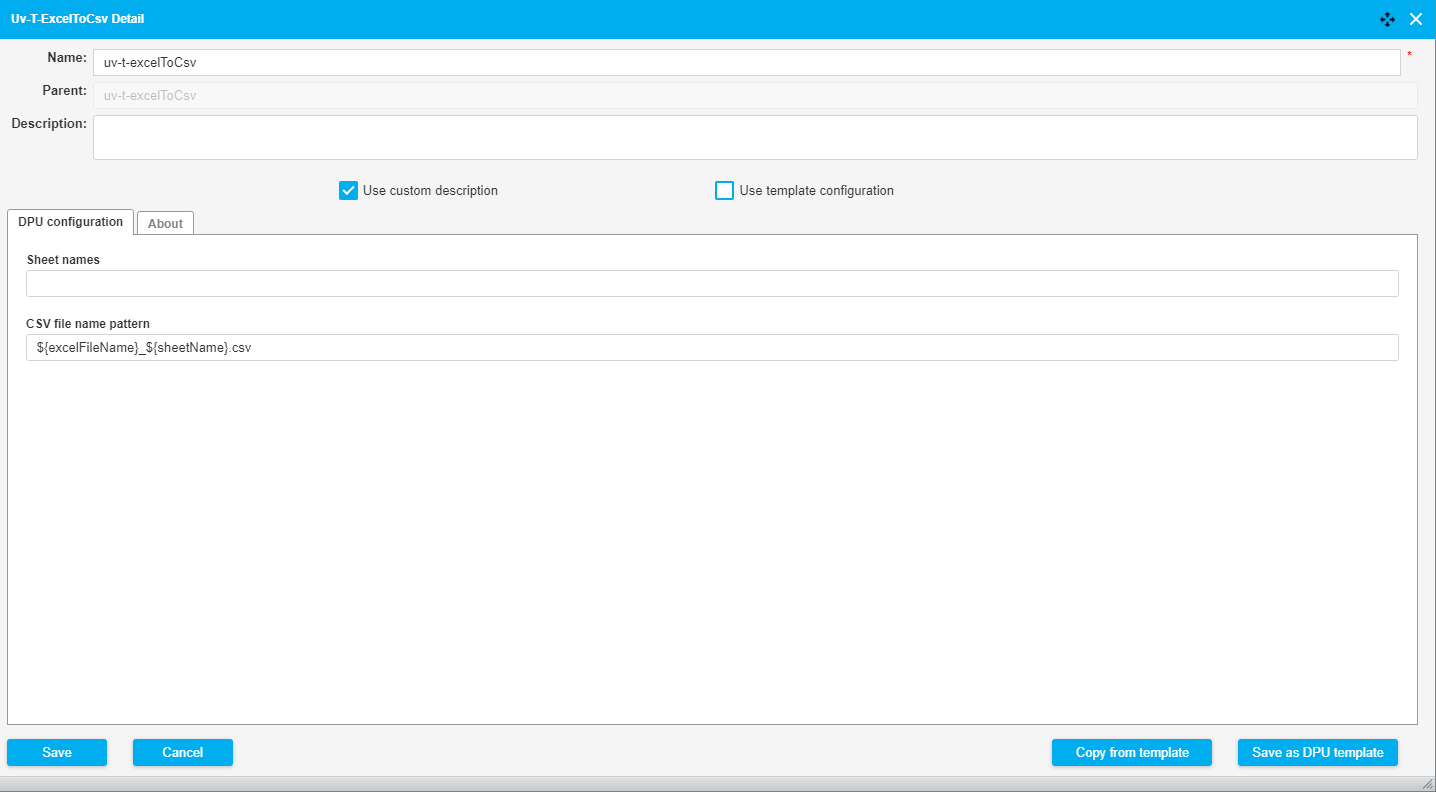
This DPU transforms Excel files (.XLS, .XLSX) into a CSV file. It is possible to indicate which sheet(s) should be extracted and transformed. Each sheet is extracted to a separate CSV file.
Name | Description | Example |
|---|---|---|
Sheet names | Sheet names separated by colon that will be transformed to CSV file. Sheet names are case insensitive. If no sheet names are specified, all sheets are transformed to CSV. | Table1:Table2:Table3 |
CSV file name pattern | Pattern used to create the name of the generated CSV file. You may use ${excelFileName} for the name of the initial Excel file (without extension) and ${sheetName} for outputting name of the processed sheet. If you are processing more input files/sheets, use ${excelFileName}/${sheetName} placeholders, so that each produced CSV file has a different name. | ${excelFileName}_${sheetName}.csv |
Name | Type | DataUnit | Description | Required |
|---|---|---|---|---|
input | input | FilesDataUnit | Input files |  |
output | output | FilesDataUnit | Produced CSV files | |
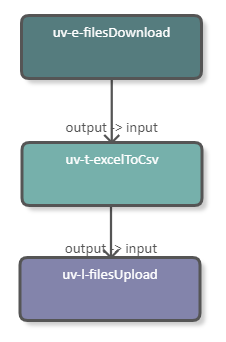
The following image shows a pipeline which downloads an Excel file from a server, converts it to CSV, and uploads it to another server. The excelToCSV DPU receives the downloaded Excel file as input and produces a CSV file as output. The configuration of the DPU can be seen in the image below.
 |
 |
Rename Files
Rename Files
This DPU renames files based on a pattern defined in the configuration.
Name | Description | Example |
|---|---|---|
Pattern | Regular expression used to match a string to replace in file name. This value is used as a replace part (second argument) in SPARQL REPLACE. | \\s |
Value to substitute | Value to substitute, it can refer to groups that have been matched by the 'Pattern' parameter. This value is used as a substitute part (third argument) in SPARQL REPLACE. | - |
Use advanced mode | If checked, the indicated value to substitute is considered an expression instead of a string. This enables the use of SPARQL functions, but the result must be in the form of a string. | struuid() |
Inputs and Outputs
Name | Type | Data Unit | Description | Required |
|---|---|---|---|---|
inFilesData | input | FilesDataUnit | File name to be modified | |
outFilesData | output | FilesDataUnit | File name after modification | |
Action | Pattern | Value to substitute |
|---|---|---|
Add a suffix ".gml" | ^(.+)$ | $1.gml |
Rename file to "abc" | ^.+$ | abc |
Substitute white spaces | \\s | _ |
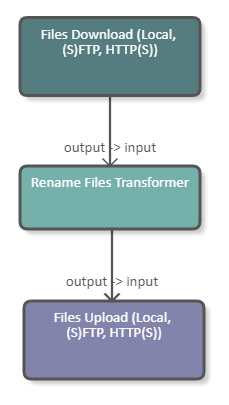
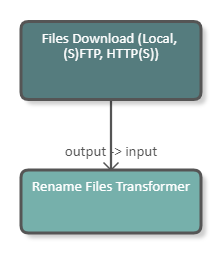
The following image shows a pipeline which downloads a file from a server, renames it, and uploads it again. The Rename Files DPU takes the downloaded file as input and produces the renamed file as output. The configuration of the DPU is shown in the image below.
 |
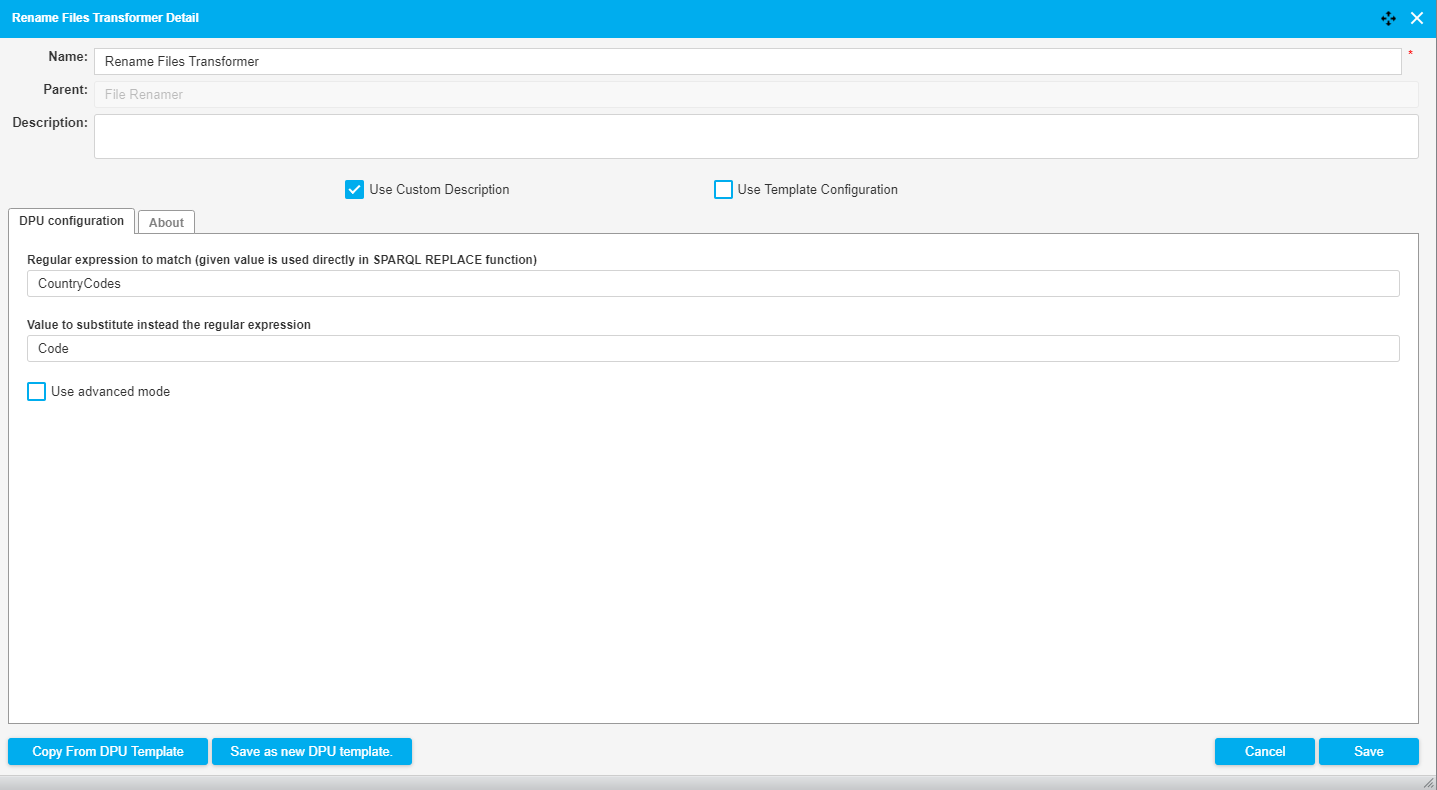 |
The following image shows a fragment of a pipeline which downloads a file, unzips it and then uses the Rename Files DPU to replace white spaces in the file names with "_". The configuration of the DPU is shown in the image below.
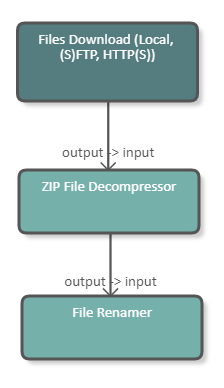 |
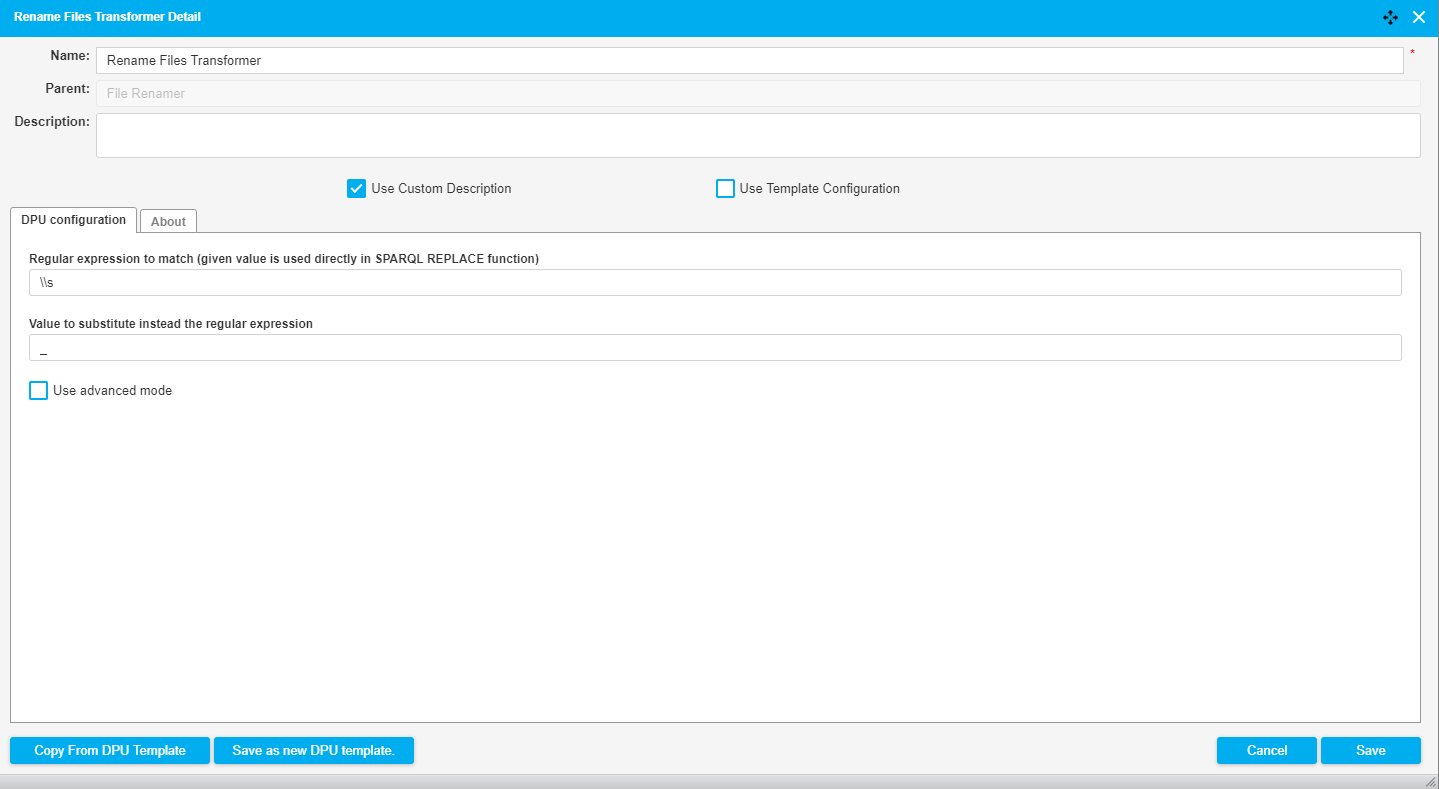 |
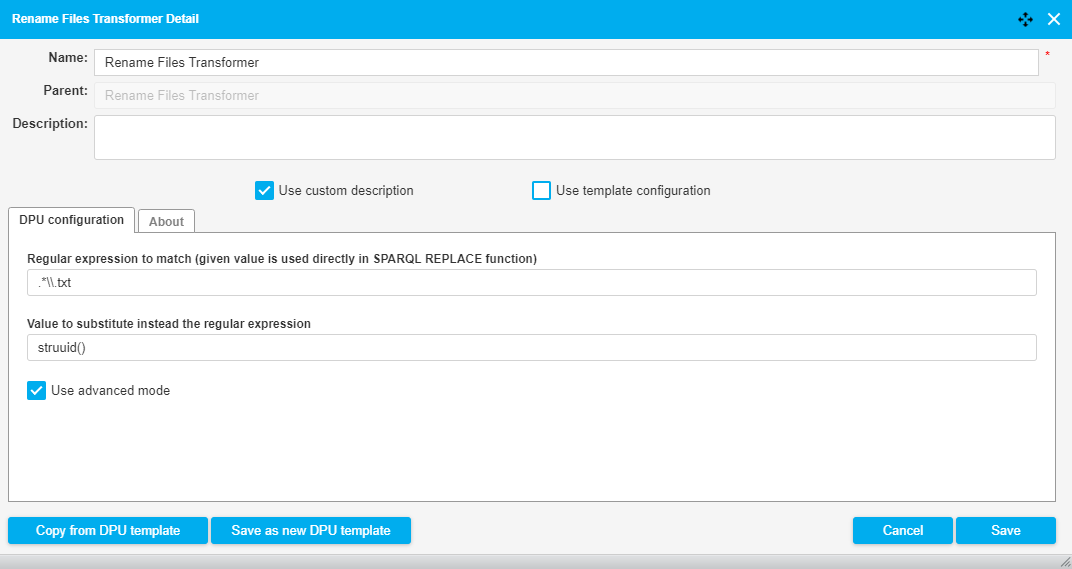
The following image shows a fragment of a pipeline which downloads a file and uses the Rename Files DPU with the advanced mode to replace the file name with a UUID. The relevant input and output parameters of this DPU are:
Input filename: file.txt
Regex: .*\\.txt
Replacement: struuid()
Output filename: 4528d703-f330-4f51-a993-e09a9e74ec12
The configuration of the DPU is shown in the image below.
 |
 |
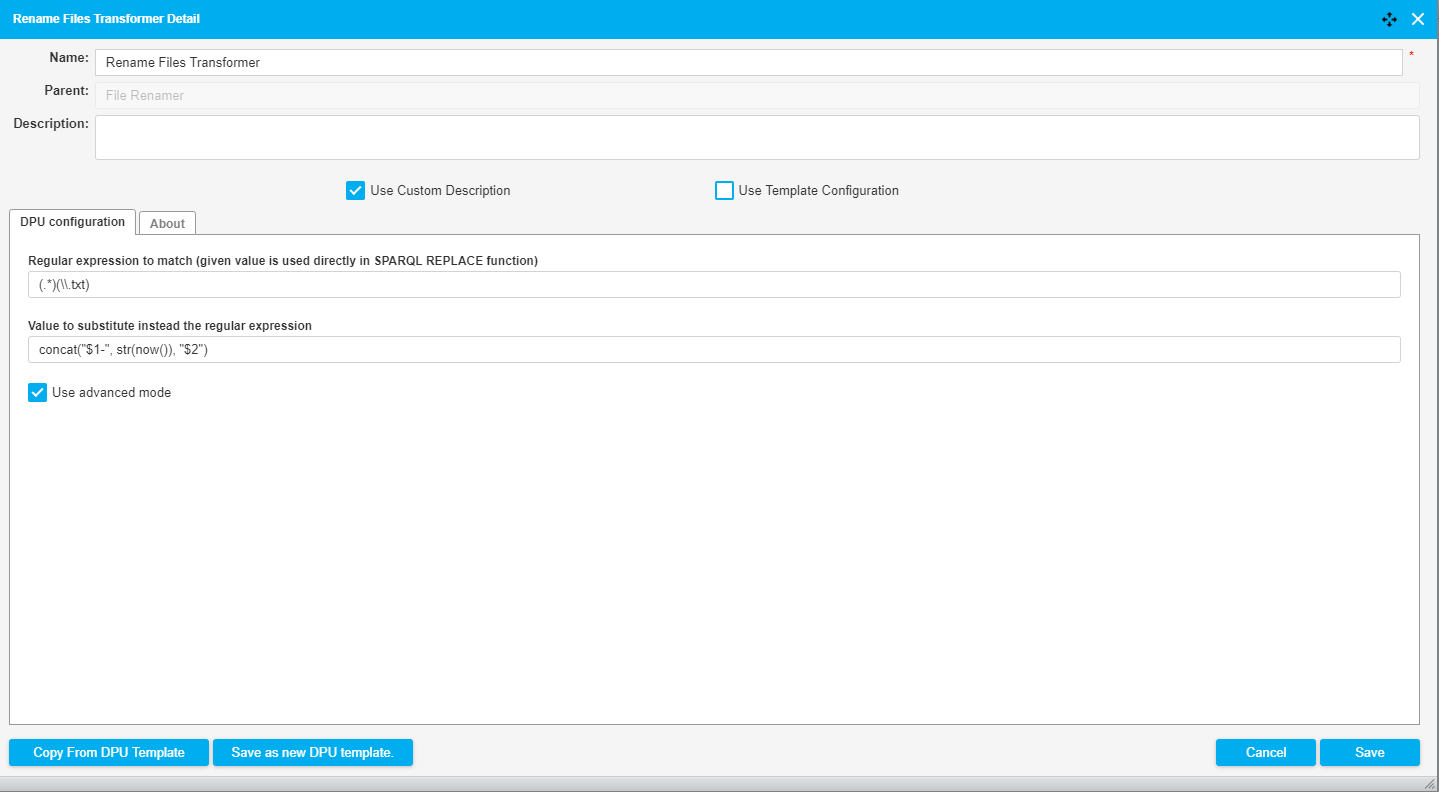
The following image shows a fragment of a pipeline which downloads a file and uses the Rename Files DPU with the advanced mode to add a timestamp to the file name. The relevant input and output parameters of this DPU are:
Input filename: file.txt
Regex: (.*)(\\.txt)
Replacement: concat("$1-", str(now()), "$2")
Output filename: file-2018-11-19T09:43:02.590+01:00.txt
|
 |
Files to RDF
Files to RDF
This DPU extracts RDF data from input files of any RDF file format and produces RDF graphs as the output.
By default, the RDF format of the input files is estimated automatically based on the extensions of the input file names. The user can also manually specify the RDF format of the input files in the configuration to make sure the correct RDF format is applied.
Based on the selected policy for creation of the output RDF graphs, the output RDF data unit contains either
one output RDF graph for each processed input file (by default) OR
one single output RDF graph for all processed input files.
In the case of one output graph for each processed input file, the symbolic names for output RDF graphs are created based on the symbolic names of input files. When only one single output graph is generated, the symbolic name of the single output RDF graph may be specified in the configuration.
This DPU supports RDF Validation extension.
Name | Description | Example |
|---|---|---|
RDF format of the input files | RDF format of the data in the input files. AUTO = automatic selection of the RDF format of the input files (default) | |
What to do if the RDF extraction from certain file fails | Stop execution (default) OR Skip that file and continue | |
Policy for creation of the output RDF graphs | One output RDF graph for each processed input file (default) OR Single output RDF graph for all processed input files | |
Symbolic name of the single output RDF graph | The desired symbolic name of the single output RDF graph may be specified here. This is only applicable when the policy for the creation of output RDF graphs is set to 'Single output RDF graph'. | graph3 |
Use file entry name as virtual graph | When checked, the DPU also automatically generates Virtual Graph metadata, which are set to be equal to the symbolic name of the file (it is expected that symbolic name is e.g. HTTP URL). |
Name | Type | DataUnit | Description | Required |
|---|---|---|---|---|
filesInput | input | FilesDataUnit | Input file containing RDF data | |
rdfOutput | output | RDFDataUnit | Extracted RDF data | |
The following RDF formats are available in this DPU:
N-Triples
RDF/XML
Turtle
N3
RDF/JSON
TriG
N-Quads
BinaryRDF
TriX
JSON-LD
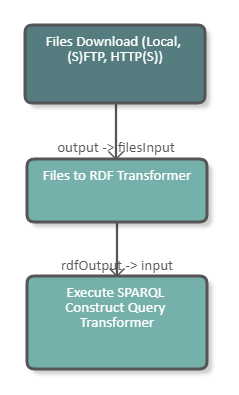
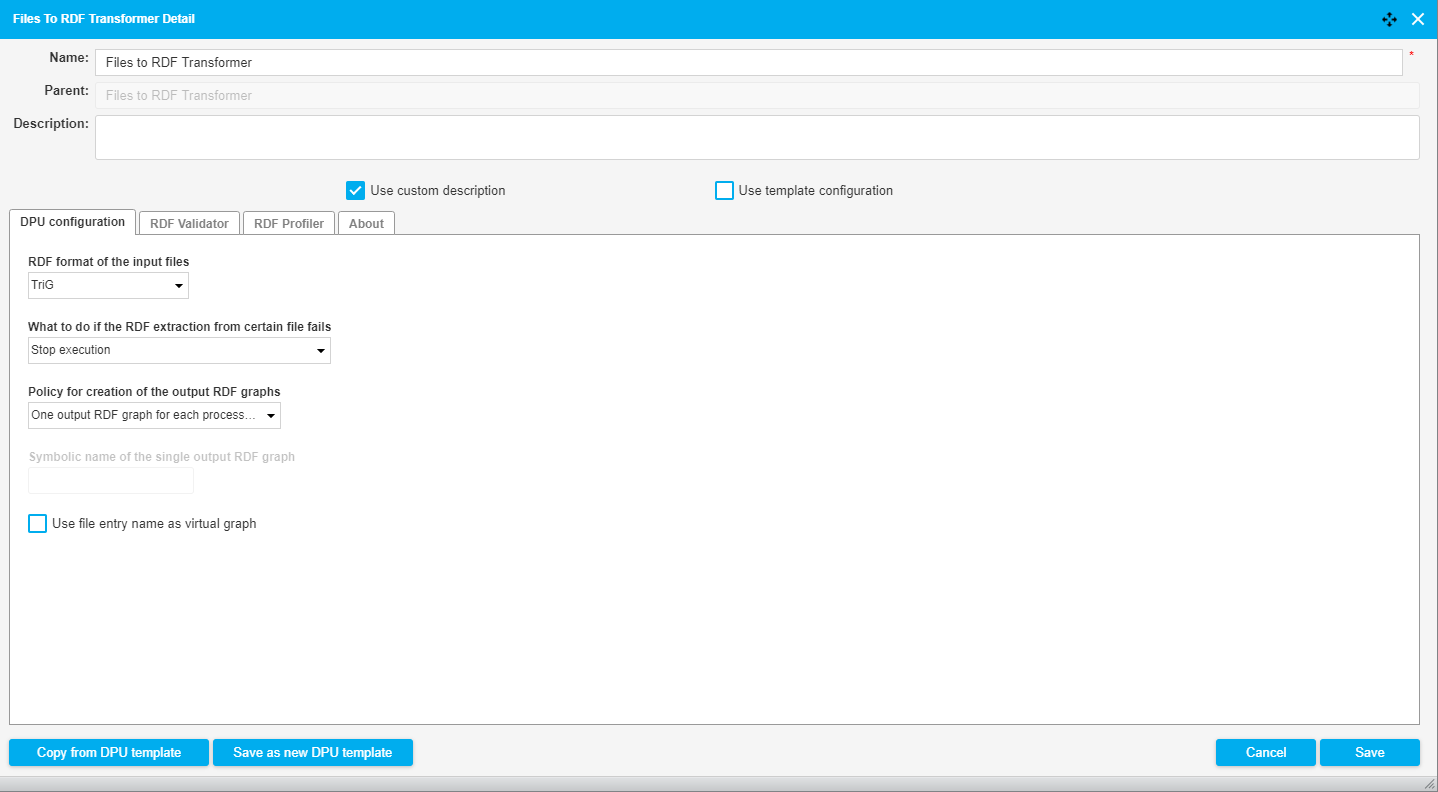
The following image shows a fragment of a pipeline which downloads a TriG file, converts the file to RDF and then uses the output as basis for a SPARQL Construct query. The image below shows the configuration of the DPU.
 |
 |
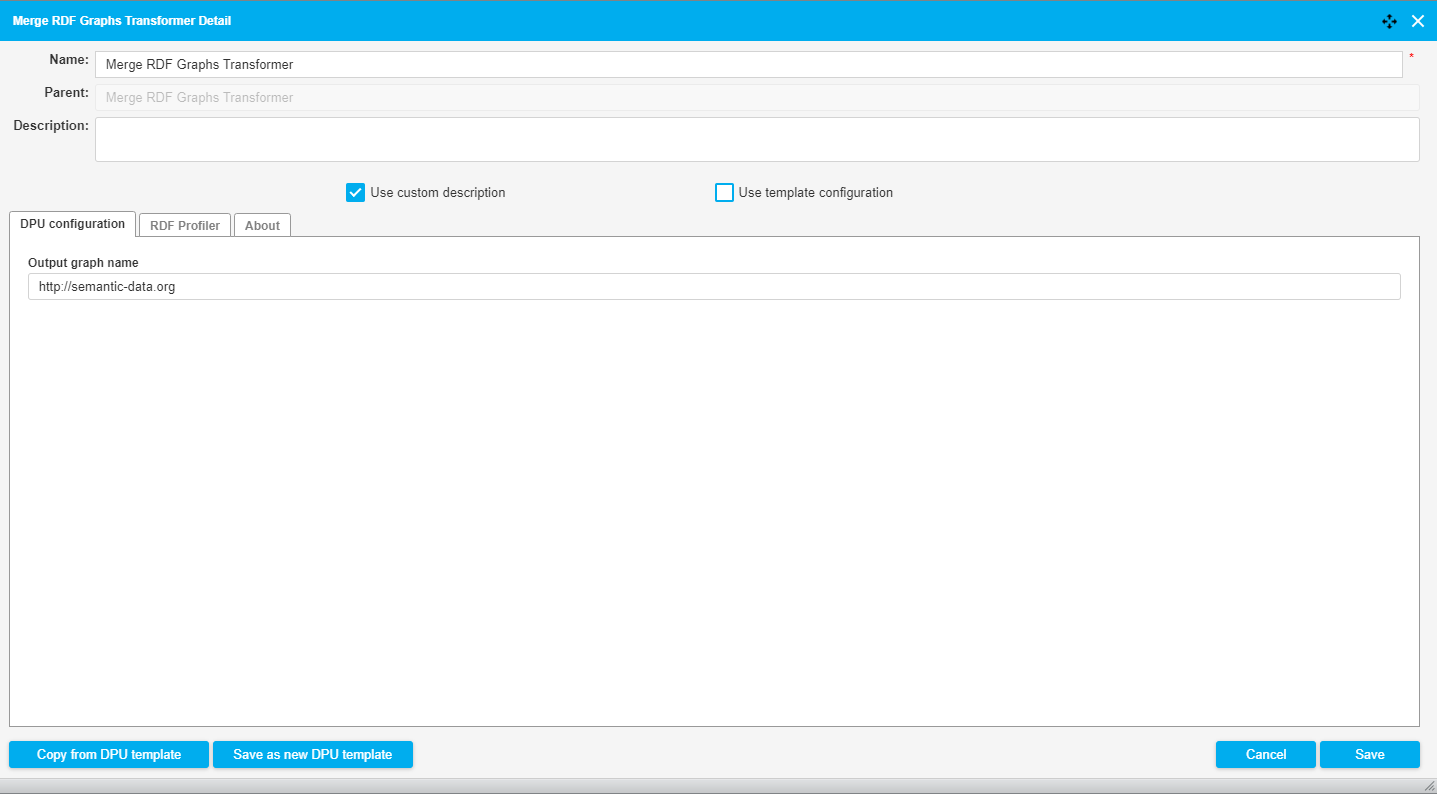
Graph Merger
Graph Merger
This DPU merges RDF input graphs into a single new RDF output graph. This means that all triples from the input graphs are put into a single new output graph.
Name | Description | Example |
|---|---|---|
Output graph name | Name (URI) of the graph on output. This name is used in other DPUs, e.g. when loading the RDF graph to an external triple store as a destination graph name. | http://schema.org/ |
Name | Type | Data Unit | Description | Required |
|---|---|---|---|---|
input | input | RDFDataUnit | Input graphs which are to be merged | |
output | output | RDFDataUnit | RDF graph which contains all triples from the input graphs |  |
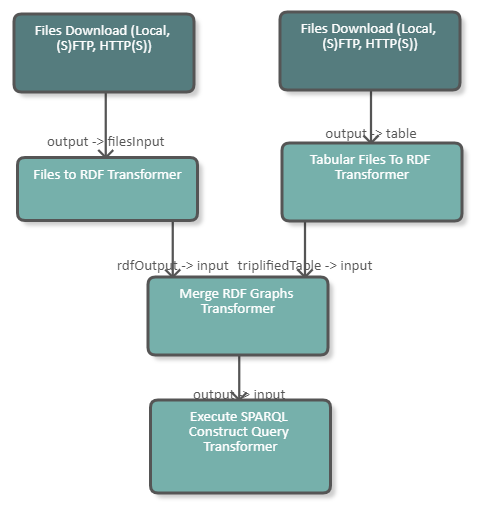
The following image shows a fragment of a pipeline which
downloads an Excel file and converts it to RDF;
makes a HTTP Request to a triple store and gets RDF data.
It then proceeds to merge both input graphs to one single output graph. This graph is then processed in a SPARQL Construct query. The configuration of the GraphMerger DPU is shown in the image below.
 |
 |
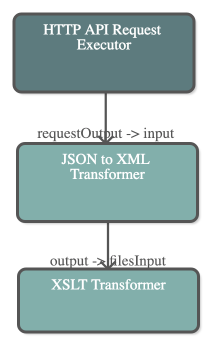
JSON to XML
JSON to XML
Converts JSON data (e.g. responses to REST services) to XML, so that it can be further processed, e.g., by XSLT.
Name | Description |
|---|---|
URL Prefix | Param which automatically replaces the defined URL with a whitespace |
Name | Type | DataUnit | Description | Required |
|---|---|---|---|---|
input | i | FilesDataUnit | Input JSON files | |
output | o | FilesDataUnit | Produced XML data | |
The following image shows a pipeline which performs an API request to PoolParty, transforms the JSON response to XML, and converts this XML into RDF/XML.
 |
The configuration of the DPU can be seen in the image below.
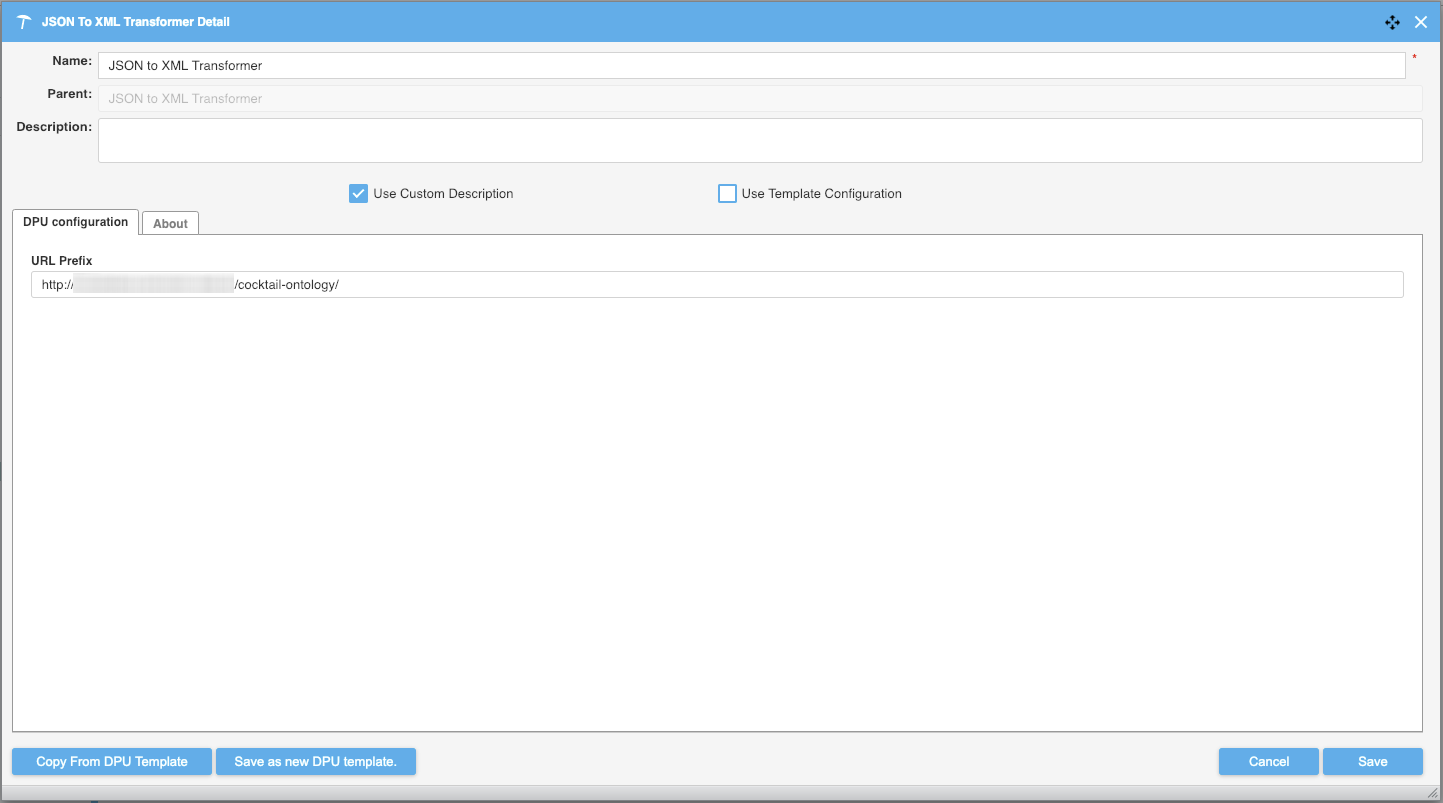
The URL Prefix allows you to automatically replace a part of text/URL with a whitespace. This is useful when you work with custom attributes URLs as when these are converted to XML format the first slash from http:/ will then break in the text causing an output of unwanted XML data.
e.g.
JSON Response
{
"uri": "http://vocabulary.server.org/cocktails/0bbdca98-077b-48d1-99d6-47eca59c442c",
"prefLabel": "Aviation",
"http://vocabulary.server.org semantic-web.at/cocktail-ontology/image": [
"https://upload.wikimedia.org/wikipedia/commons/4/4f/Aviation_Cocktail.jpg"
]
}Unwanted XML Output
<root> <http:>https://upload.wikimedia.org/wikipedia/commons/4/4f/Aviation_Cocktail.jpg</http:> </root>
This is unwanted and is difficult to further transform due to the nature of needing to encode character breaks to handle this cause.
With the usage of the URL Prefix field we are able to have a better generated XML tag.
e.g.
Wanted XML Output
<root> <image>https://upload.wikimedia.org/wikipedia/commons/4/4f/Aviation_Cocktail.jpg</image> </root>
Execute SPARQL Construct Query
Execute SPARQL Construct Query
This DPU transforms input using the SPARQL Construct query provided. The result of the SPARQL Construct - the created triples - is stored to the output.
Note: Internally, the query is translated to SPARQL Update query before it is executed.
It supports RDF Validation extension.
Name | Description | Example |
|---|---|---|
Per-graph execution | If checked query is executed per-graph | true |
SPARQL construct query | SPARQL construct query | CONSTRUCT {?s ?p ?o} WHERE {?s ?p ?o} |
Name | Type | Data Unit | Description | Mandatory |
|---|---|---|---|---|
input | input | RDFDataUnit | RDF input | |
output | output | RDFDataUnit | transformed RDF output | |
The following image shows a fragment of a pipeline which downloads an Excel file from the server and transforms it into RDF. With a SPARQL Construct we add a skos:prefLabel and convert the URI generated by the Tabular Transformer into a UUID. The DPU configuration is illustrated in the image below.
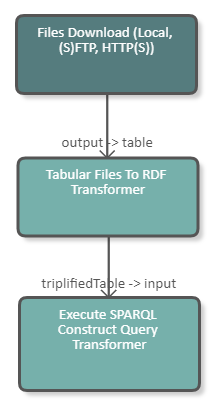 |
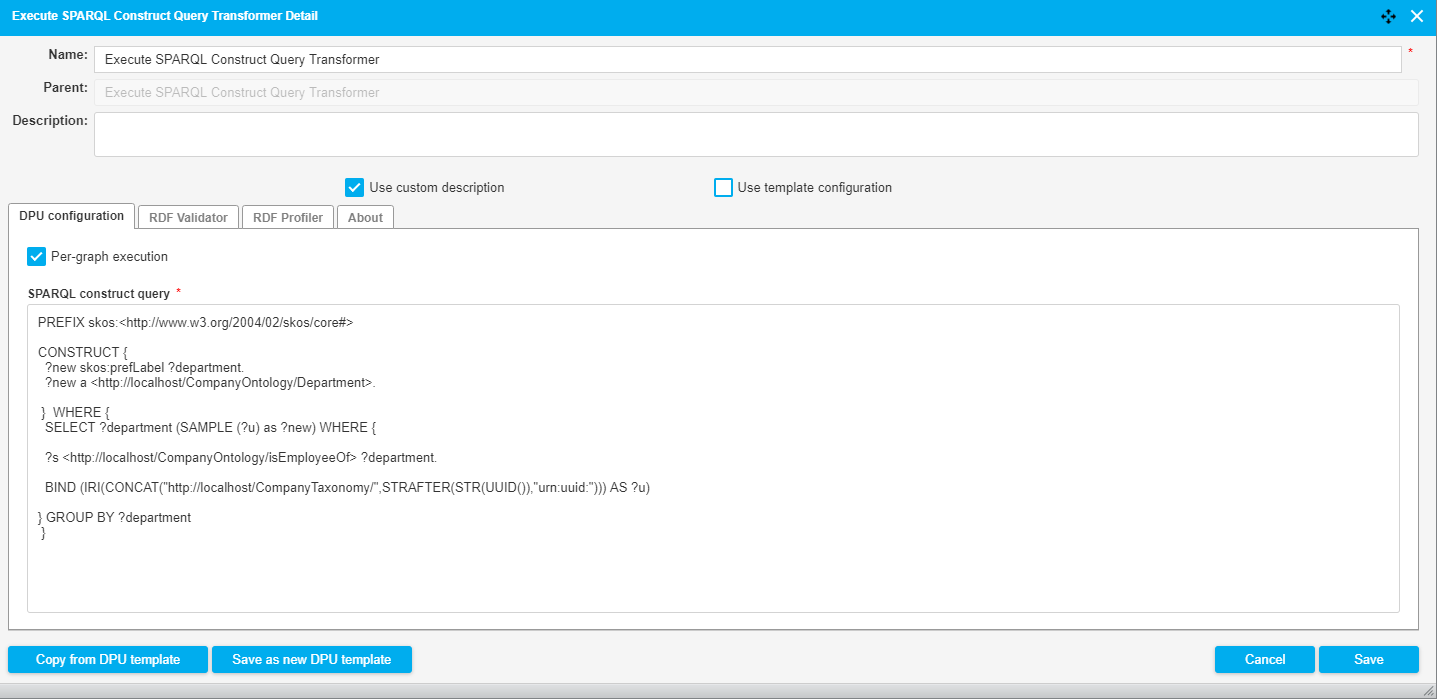 |
The following image shows a fragment of a pipeline which downloads an Excel file from the tmp folder of the UnifiedViews server. The data of the Excel file is subsequently converted to RDF and serves as input for the SPARQL Construct Query. The purpose of this query is to construct the configuration file of the second Files Download DPU. The query creates triples containing the download URI and the file name of the files that are to be downloaded. With this configuration file the Files Download DPU downloads the indicated files. After the files are downloaded they are uploaded to the tmp folder of the UnifiedViews server using the Files Upload DPU. The DPU configuration is illustrated in the image below.
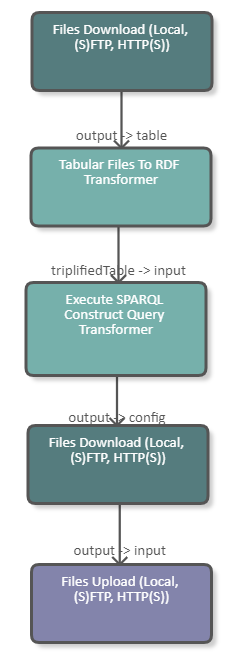 |
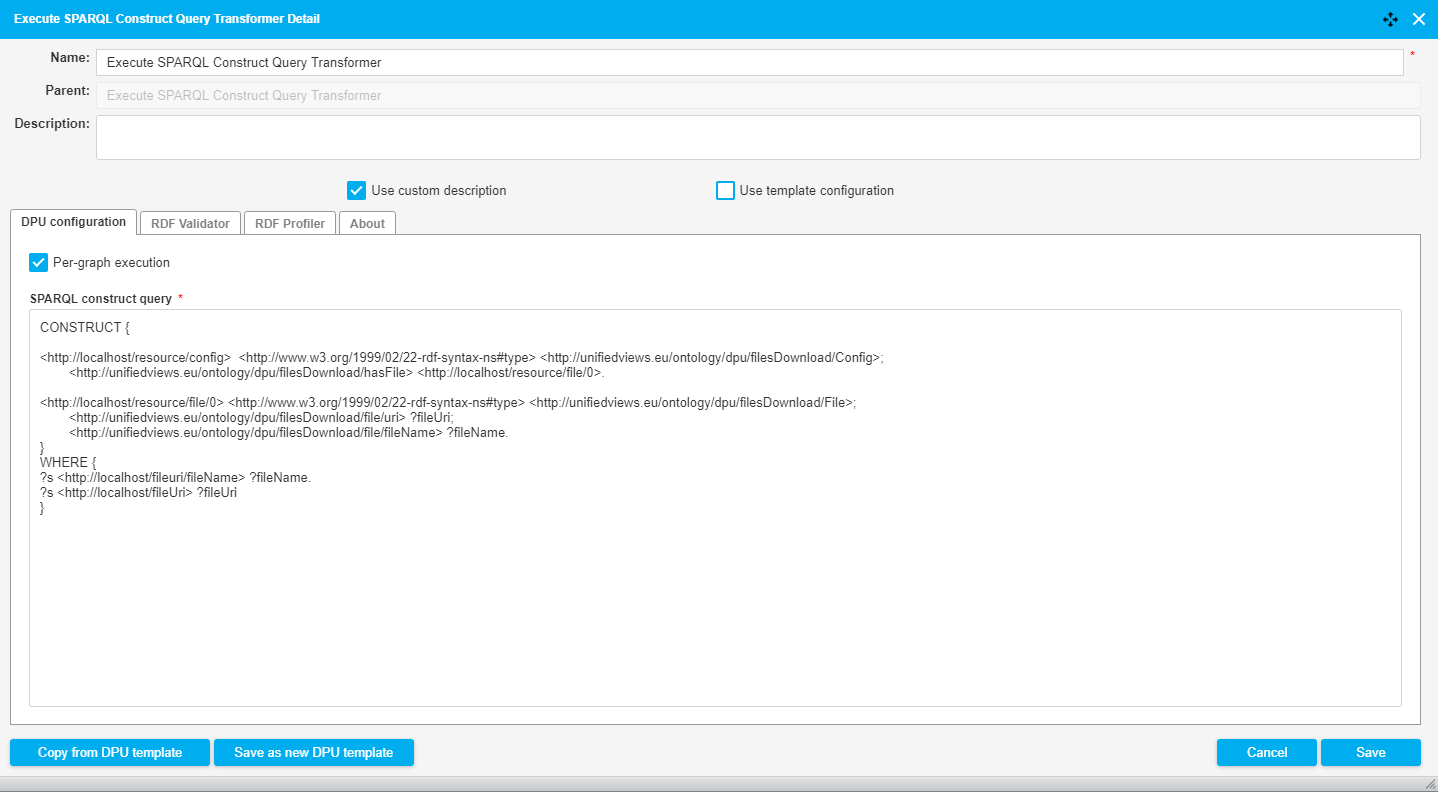 |
SPARQL Select
SPARQL Select
Transforms SPARQL SELECT query results to CSV. It does not validate query.
Name | Description | Example |
|---|---|---|
Target path* | path and target CSV file name | /tmp/out.csv |
SPARQL query | text area dedicated for SPARQL SELECT query | SELECT ?s ?p ?o WHERE { ?s ?p ?o } |
Name | Type | DataUnit | Description | Required |
|---|---|---|---|---|
input | i | RDFDataUnit | RDF graph | |
output | o | FilesDataUnit | CSV file containing SPARQL SELECT query result | |
The following image shows a pipeline which loads all data from a SPARQL Endpoint, selects a subset of the data using the SPARQL Select Query, transforms the CSV response to relational data and loads that into a relational database
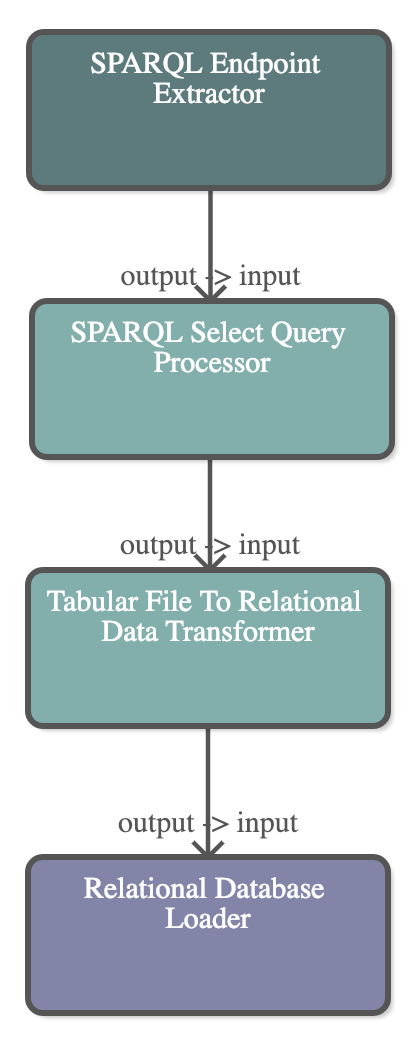 |
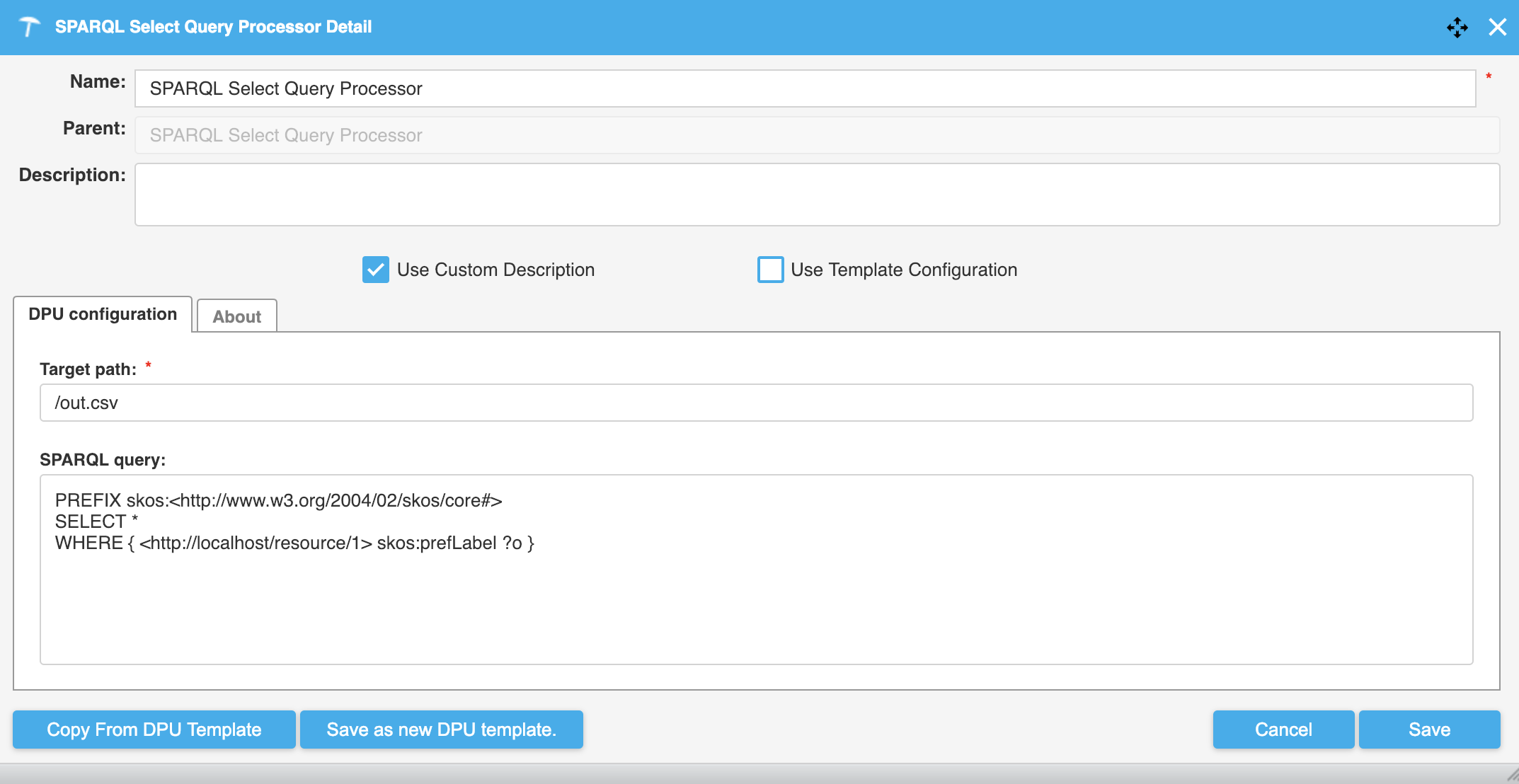 |
SPARQL Update
SPARQL Update
This DPU transforms input RDF using a single SPARQL Update query.
It supports RDF Validation extension.
It does not support quads - it is always executed either on top of all input graphs, or, if per-graph execution is checked, successively on each graph.
Name | Description | Example |
|---|---|---|
Per-graph execution | If checked query is executed per-graph - the query is executed separately on each input graph | |
SPARQL update query | SPARQL update query |
Name | Type | DataUnit | Description | Required |
|---|---|---|---|---|
input | i | RDFDataUnit | RDF input | |
output | o | RDFDataUnit | RDF output (transformed) | |
In this pipeline below we are extracting data via a SPARQL Endpoint, then we split the pipeline into two processes to Update and Construct data using the SPARQL Update and SPARQL Construct DPUs. WIth the SPARQL Update Query we
 |
Tabular File To RDF
Tabular File To RDF
This DPU converts tabular data into RDF data. As an input it takes CSV, DBF and XLS files.
It supports RDF Validation Extension.
Name | Description | Example |
|---|---|---|
Resource URI base | This value is used as base URI for automatic column property generation and also to create absolute URI if relative URI is provided in 'Property URI' column. | http://localhost/ |
Key column | Name of the column that will be appended to 'Resource URI base' and used as subject for rows. | Employee |
Encoding | Character encoding of input files. Possible values: UTF-8, UTF-16, ISO-8859-1, windows-1250 | UTF-8 |
Rows limit | Max. count of processed lines | 1,000 |
Class for a row entity | This value is used as a class for each row entity. If no value is specified, the default "Row" class is used. | http://unifiedviews.eu/ontology/t-tabular/Row |
Full column mapping | A default mapping is generated for every column | true |
Ignore blank cells | Blank cells are ignored and no output will be generated for them. | false |
Use static row counter | When multiple files are processed those files share the same row counter. The process can be viewed as if files are appended before parsing. | false |
Advanced key column | 'Key column' is interpreted as template. An example of a template is http://localhost/{type}/content/{id}, where "type" and "id" are names of the columns in the input CSV file. | false |
Generate row column | If checked, a triple containing the row number is generated for each row. The triple looks like this: <URI> <http://linked.opendata.cz/ontology/odcs/tabular/row> <Row Number>. | true |
Generate subject for table | A subject for each table that points to all rows in given table is created. The predicate used is "http://linked.opendata.cz/ontology/odcs/tabular/hasRow". With the predicate "http://linked.opendata.cz/ontology/odcs/tabular/symbolicName" the symbolic name of the source table is also attached. | false |
Auto type as string | All auto types are considered to be strings. This can be useful with full column mapping to enforce the same type over all the columns and get rid of warning messages. | false |
Generate table/row class | If checked, a class for the entire table is generated. The triple looks like this: <File URI> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type><http://unifiedviews.eu/ontology/t-tabular/Table>. Note: This additional triple is only generated when "Generate subject for table" is also checked. | false |
Generate labels | If checked, a label for each column URI is generated. The corresponding value of the header row is used as label. If the file does not contain a header data from the first row is used.It does not generate labels for advanced mapping. | false |
Remove trailing spaces | Trailing spaces in cells are removed. | false |
Ignore missing columns | If a named column is missing only info level log is used instead of error level log. | false |
There are three different types of mapping available:
Simple mapping
Advanced mapping with templates
XLS mapping
The simple mapping tab allows to define how the columns should be mapped to the resulting predicates, including also information about the datatypes. The Advanced mapping tab is equivalent to the Simple mapping tab, but it allows to specify templates for values of the predicates. A sample template is http://localhost/{type}/content/{id}, where "type" and "id" are names of the columns in the input file. The XLS mapping can be used for the static mapping of cells to named cells. Named cells are accessible as extension in every row.
Name | Description | Example |
|---|---|---|
Quote char | If no quote char is indicated, no quote chars are used. In this case values must not contain separator characters. | " |
Delimiter char | Character used to specify the boundary between separate values. | , |
Skip n first lines | Number of indicated rows are skipped when processing the file. | 10 |
Has header | If the file has no header the columns are accesible as col0, col1, .... | true |
Name | Description | Example |
|---|---|---|
Sheet name | Specify the name of the sheet that is to be processed. | Table1 |
Skip n first lines | Number of indicated rows are skipped when processing the file. | 10 |
Has header | If the file has no header the columns are accesible as col0, col1, .... | true |
Strip header for nulls | Trailing null values in the header are removed. This can be useful if the header is bigger than data so that no exepton for "diff number of cells in header" is thrown. | false |
Use advanced parser for double | In XLS integer, double and date are all represented in the same way. This option enables advanced detection of integers and dates based on value and formatting. | false |
Name | Type | Data Unit | Description | Required |
|---|---|---|---|---|
table | input | FilesDataUnit | Input files containing tabular data | |
triplifiedTable | output | FilesDataUnit | RDF data | |
The following image shows a fragment of a pipeline which downloads a CSV file from the tmp folder of the UnifiedViews server. The data of the file is subsequently converted to RDF and loaded into a Virtuoso triple store. The DPU configuration is illustrated in the image below.
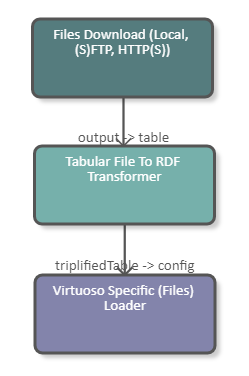 |
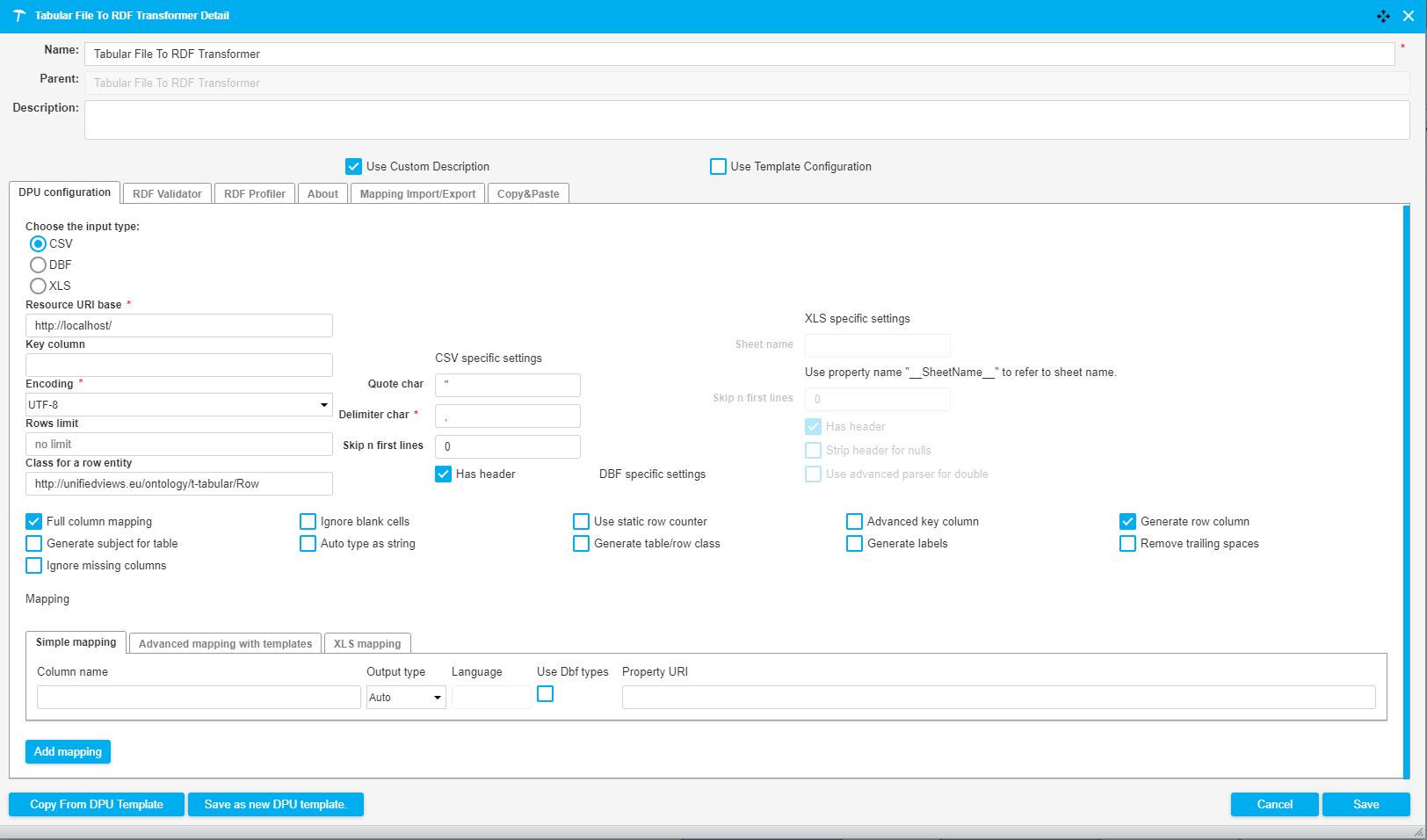 |
The following image shows a fragment of a pipeline which downloads an Excel file (.xls) from the tmp folder of the UnifiedViews server. The data of the Excel file is subsequently converted to RDF and serves as input for a SPARQL Construct Query. The purpose of this query is to construct the configuration file of the second Files Download DPU. After the files are downloaded they are uploaded to the tmp folder of the UnifiedViews server using the Files Upload DPU. The DPU configuration is illustrated in the image below.
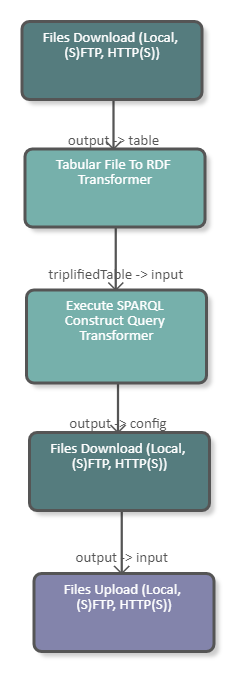 |
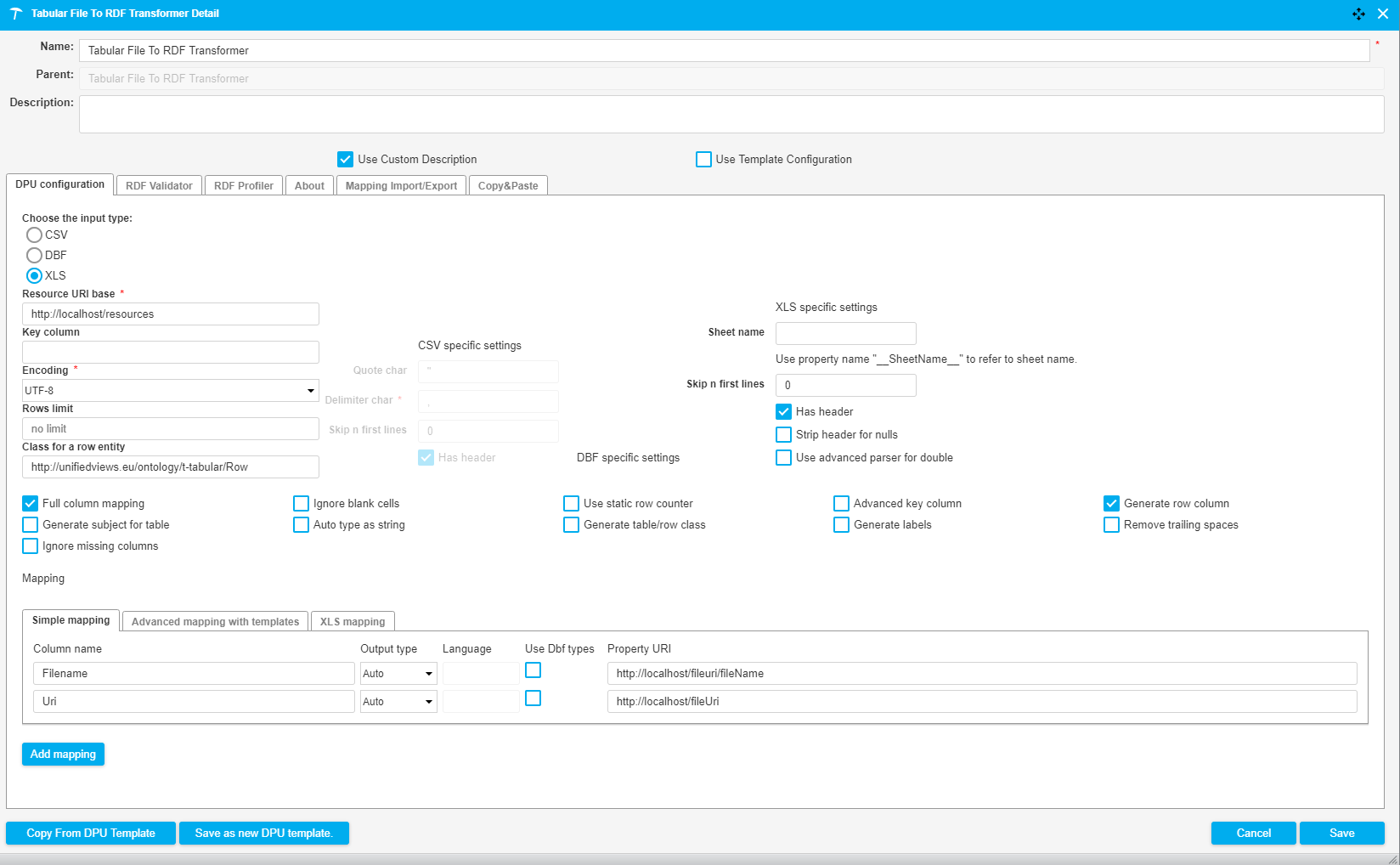 |
The query used in this pipeline creates triples containing the download URI and the file name of the files that are to be downloaded. The query reads as follows:
CONSTRUCT {
<http://localhost/resource/config> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://unifiedviews.eu/ontology/dpu/filesDownload/Config>;
<http://unifiedviews.eu/ontology/dpu/filesDownload/hasFile> <http://localhost/resource/file/0>.
<http://localhost/resource/file/0> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://unifiedviews.eu/ontology/dpu/filesDownload/File>;
<http://unifiedviews.eu/ontology/dpu/filesDownload/file/uri> ?fileUri;
<http://unifiedviews.eu/ontology/dpu/filesDownload/file/fileName> ?fileName.
}
WHERE {
?s <http://localhost/fileuri/fileName> ?fileName.
?s <http://localhost/fileUri> ?fileUri
}The following image shows a fragment of a pipeline which downloads a CSV file from the server and transforms it into RDF. With a SPARQL Construct we convert the URI generated by the Tabular File To RDF Transformer into a UUID. The DPU configuration is illustrated in the image below.
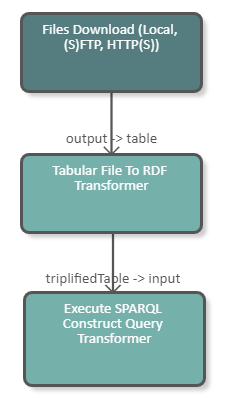 |
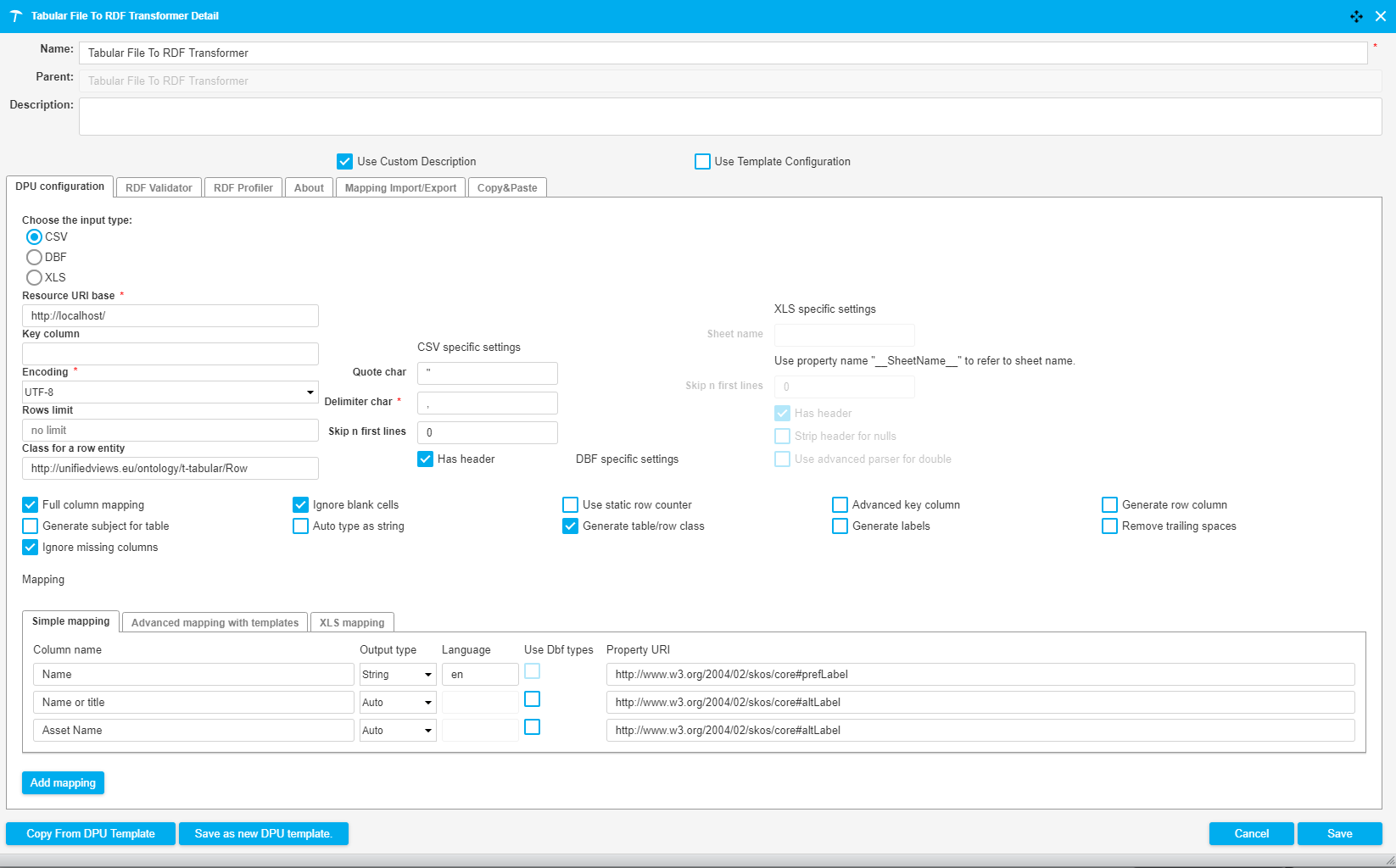 |
XML to JSON
XML to JSON
This DPU transforms XML documents to equivalent JSON documents. The input and output is of type file.
Name | Description |
|---|---|
JSON Pretty Print | Generates JSON documents, outputted in human readable format instead of compact machine readable format |
Cast to JSON primitives automatically | Data types of XML elements are automatically detected and casted into corresponding JSON primitive types |
XML element path | The path of XML elements that should be parsed as a JSON array |
Name | Type | DataUnit | Description | Required |
|---|---|---|---|---|
filesInput | i | FilesDataUnit | XML documents to be transformed | |
filesOutput | i | FilesDataUnit | JSON documents produced from transformation | |
A sequence of XML elements with same element name can be considered as an array. However, there is no array structure in XML similar to JSON array, which means it is not prossible to decide if an element is actually an array with one object when there is only one element. Therefore, StAXON introduces some annotations to explicitly declare the XML elements that should be transformed into JSON arrays. Those annotations can be defined based on a XPath-like syntax path ::= '/'? <localName> ('/' <localName>)*.
For example:
<alice>
<bob>edgar</bob>
</alice> are transformed to:
{
"alice":{
"bob":"edgar"
}
}By default with an annotation such as /alice/bob the result will become:
{
"alice":{
"bob":[
"edgar"
]
}
}The core transformation engine of this plugin attributes to StAXON - JSON via StAX from Odysseus Software . For more information related to XML to JSON transformation, please visit StAXON WiKi.
Particularly, the following chapters are relevant to this plugin:
StAXON WiKi - Converting XML to JSON StAXON WiKi - Mapping Convention StAXON WiKi - Mastering Arrays
XSLT
XSLT
This DPU performs XSL transformation over input files, using a single static template. The outcome of the transformation will be in file format.
This DPU supports random UUID generation using randomUUID() function in namespace uuid-functions.
Example usage:
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet xmlns:uuid="uuid-functions" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0"> <xsl:template match="/"> <xsl:value-of select="uuid:randomUUID()"/> </xsl:template> </xsl:stylesheet>
Name | Description | Example |
|---|---|---|
Skip file on error | If selected and the transformation fails, then the file is skipped and the execution continues. | False |
File extension | If provided then the file extension in virtual path is set to the given value. If no virtual path is set then an error message is logged and no virtual path is set. | .xml |
Number of extra threads | How many additional workers should be created. One worker thread is always created even if the value is set to zero. Remember that a higher number of workers may speed up transformation but will also result in greater memory consumption. This option should work better with files that takes longer to transform. | 2 |
XSLT template | The template used during the transformation. |
Name | Type | DataUnit | Description | Required |
|---|---|---|---|---|
files | i | FilesDataUnit | File/s to be transformed | |
files | o | FilesDataUnit | Transformed file of given type | |
config | i | RdfDataUnit | Dynamic DPU configuration, see Advanced configuration |
It is also possible to dynamically configure the DPU over its input config using RDF data.
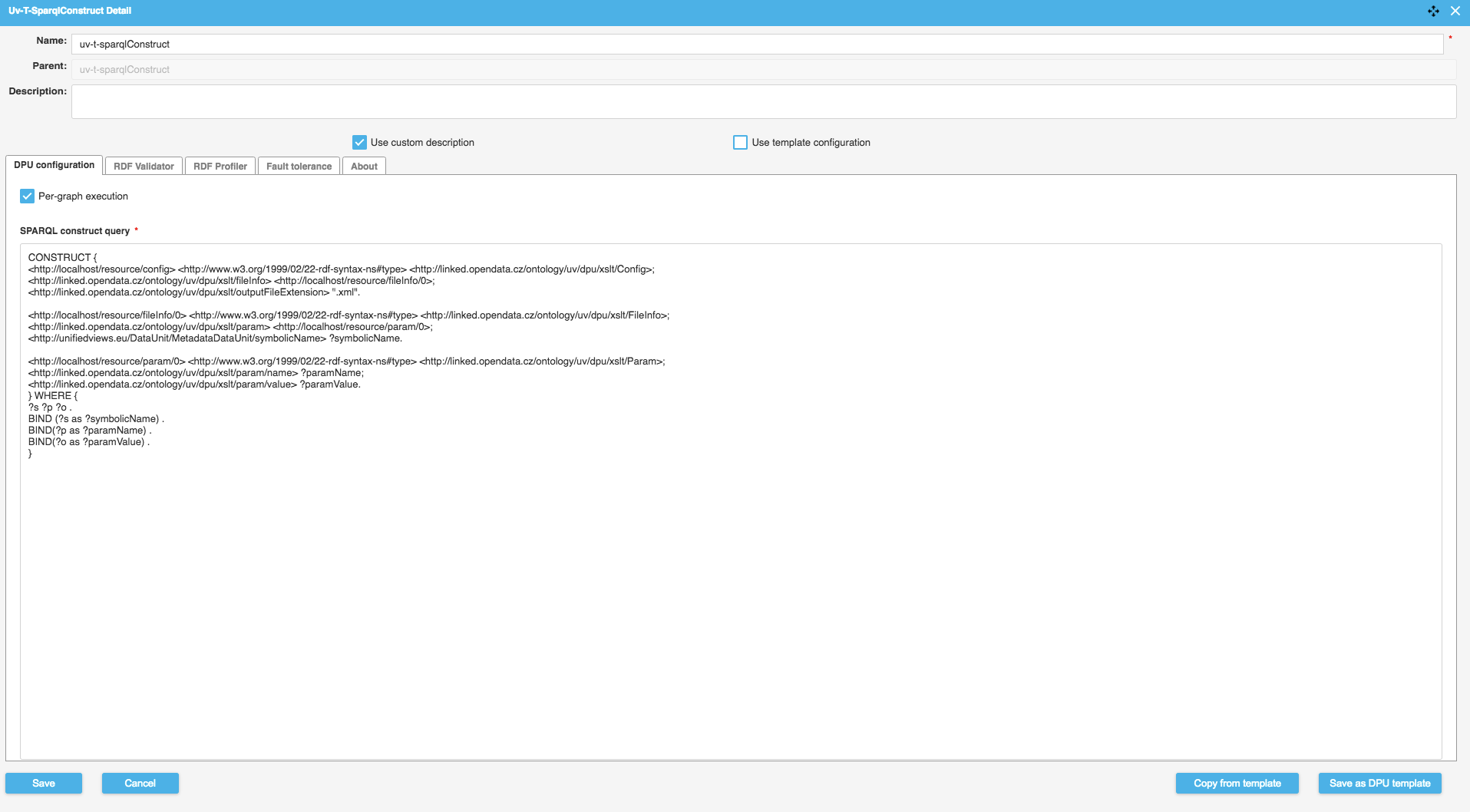
Configuration sample:
<http://localhost/resource/config> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://linked.opendata.cz/ontology/uv/dpu/xslt/Config>; <http://linked.opendata.cz/ontology/uv/dpu/xslt/fileInfo> <http://localhost/resource/fileInfo/0>; <http://linked.opendata.cz/ontology/uv/dpu/xslt/outputFileExtension> “.ttl”. <http://localhost/resource/fileInfo/0> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://linked.opendata.cz/ontology/uv/dpu/xslt/FileInfo>; <http://linked.opendata.cz/ontology/uv/dpu/xslt/param> <http://localhost/resource/param/0>; <http://unifiedviews.eu/DataUnit/MetadataDataUnit/symbolicName> “smlouva.ttl”. <http://localhost/resource/param/0> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://linked.opendata.cz/ontology/uv/dpu/xslt/Param>; <http://linked.opendata.cz/ontology/uv/dpu/xslt/param/name> “paramName”; <http://linked.opendata.cz/ontology/uv/dpu/xslt/param/value> “paramValue”.
The following image shows a fragment of a pipeline which first downloads an XML file, uses XSLT to transform the file into RDF/XML file, followed by transforming this outputted file into RDF Data. The configuration for the XSLT can be seen below.
 |
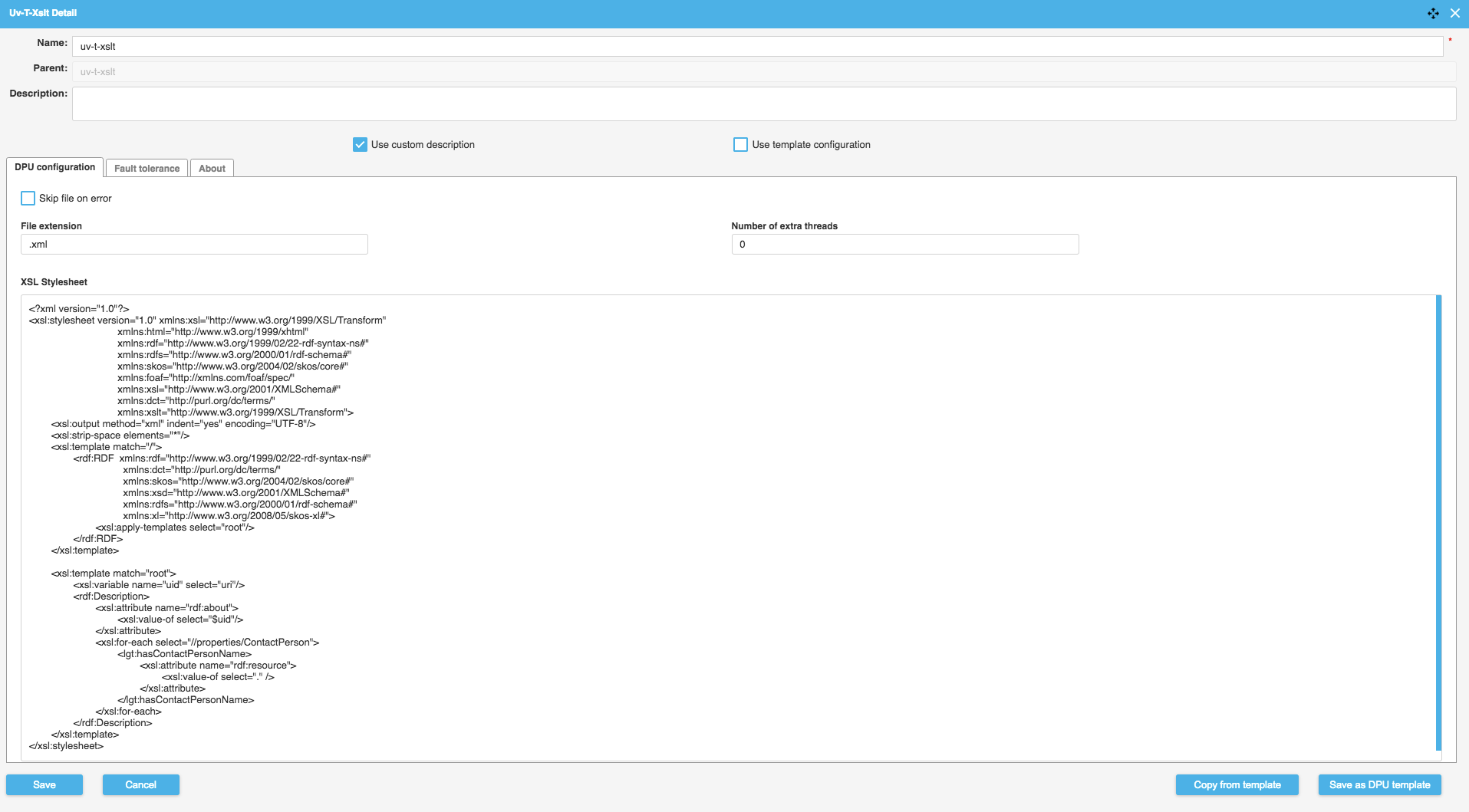 |
Using the above sample config I can construct the input for our next example. Allowing me to use RDF config as my input in place of my file, demonstrated below.