Co-occurrences in PoolParty - Usage and Function
Co-occurrences in PoolParty - Usage and Function
This section contains a short overview of what the co-occurrences calculation in PoolParty does and how you can use its results to advantage.
Co-occurrences calculation in PoolParty is a basic function as regards the refinement of a thesaurus or the enrichment of it. It is also at the base of a few other features and calculations PoolParty offers to make sure that you get the best possible results from your knowledge graphs.
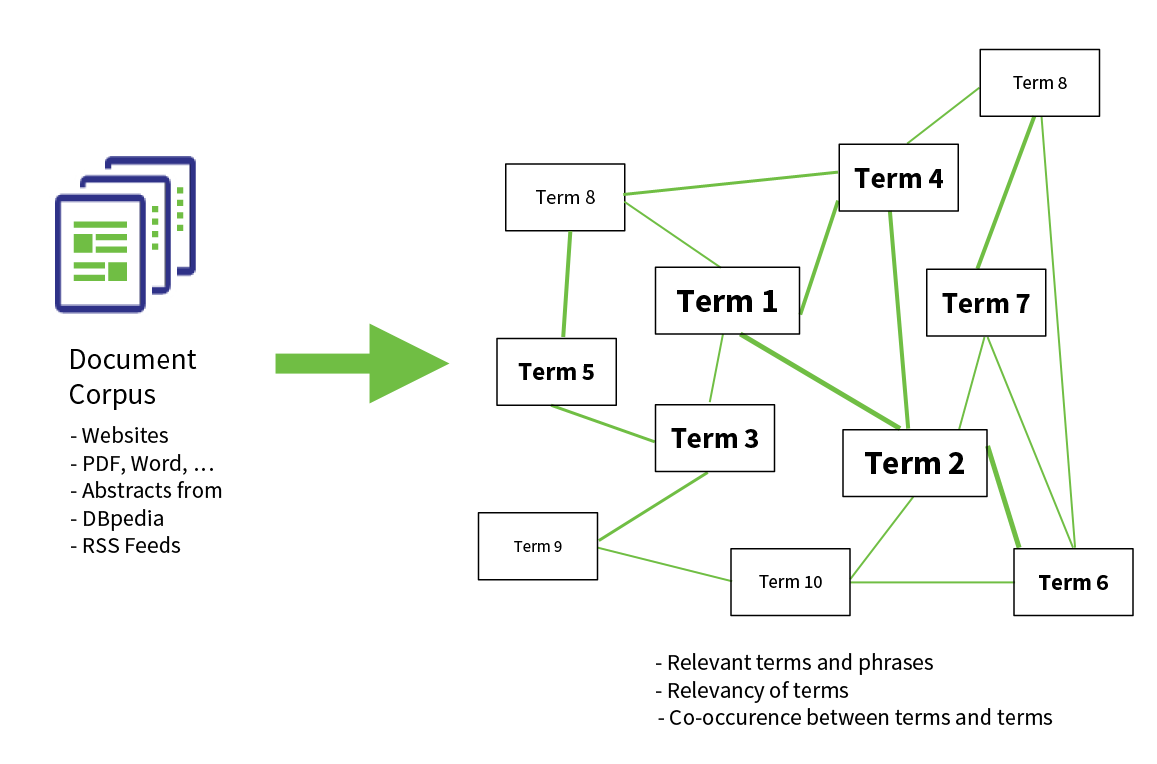
The concept of co-occurrences covers the idea that terms and concepts in texts can occur frequently in close proximity to other terms. Thus the co-occurrence calculation is based on the idea that the frequency of certain terms occurring in such texts close to thesaurus concepts is a hint that they in turn might be considered useful for refining data, especially your thesauri. This means each time a corpus of texts or the linked data of a PoolParty project is being analyzed, the co-occurrences calculation will help you to determine the validity and usefulness of either thesaurus or corpus or corpora. The results of such a calculation provide scores you can use to determine terms and concepts for further re-use.
Disambiguation: an example of co-occurrences being used to help disambiguate is the term 'Jaguar', since it depends on the context, if a car brand was referred to, or the animal.
Concept and Term Co-occurrences: another example is that a phrase like 'Machu Pichu' itself may be contained in an unknown document and at the same time is no concept in your thesaurus. But since this phrase is frequently found in close proximity to other thesaurus concepts in corpus documents, which deal with the Inca arts and culture, a deduction is possible: documents that do not contain a concept of that thesaurus, but where the phrase 'Machu Pichu' is found, can be classified among the ones dealing with Inca arts and culture as well.
The following functions and features can help you to actively make use of this feature, when refining your thesaurus or evaluating your text corpora:
The Term Suggestions calculated from the corpus you can find and use in the concept's Details View in the Corpus Management.
The Word Sense Induction feature, that disambiguates potentially ambiguous terms is also based on co-occurrence calculation.
The so-called Shadow Concepts can be used to find out about the concepts and terms in your thesaurus in relation to your corpus.
The Test Extraction Dialogue Box of PoolParty's API lets you use the scores of shadow concepts, concepts and free terms.
Schematic Representation of the Co-occurrences Principle:
 |