Grab Documents From HTML Pages
Grab Documents From HTML Pages
This section contains a short guide on how to use the Crawl Website function for your corpus.
You can provide URLs to create documents to be uploaded to your document corpus.
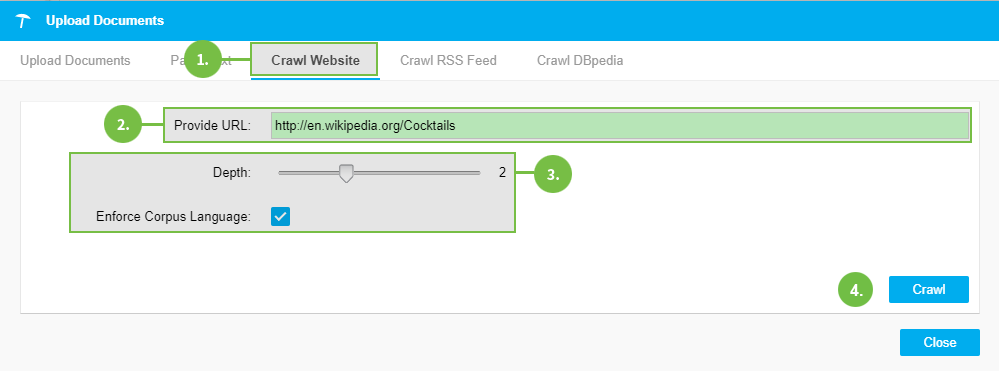
Select the Crawl Website tab in the Upload Documents dialogue.
Type or copy and paste the URL PoolParty should crawl into the Provide URL field.
The next two options are optional and provide these functions:
Depth: set the depth for the crawling process. A depth of '2' means, that the pages linked from the provided URLs are followed to the second level of linking. (Default: 1)
Enforce Corpus Language: activating this check box means, PoolParty will only crawl pages where the language identified by the built-in language detection matches the corpus language you defined during its creation (Default: Enabled)
Click Crawl to start the upload process.
The content from the provided website and the linked pages is grabbed and stored as files to your corpus. When the upload is finished, a message about the upload's status will be displayed.
 |
You can view all documents uploaded to your corpus in the Corpus Documents tab.
Note
Unlimited file upload is only available for PoolParty Enterprise server and PoolParty Semantic Integrator. For all other license types the upload is limited to 100 files or an overall size of 10 MB.