Interaction of PoolParty Components in the Recommendation Process
Interaction of PoolParty Components in the Recommendation Process
Let us now focus on two aspects of the recommendation process - the indexing of the recommender content and the retrieval of recommendations.
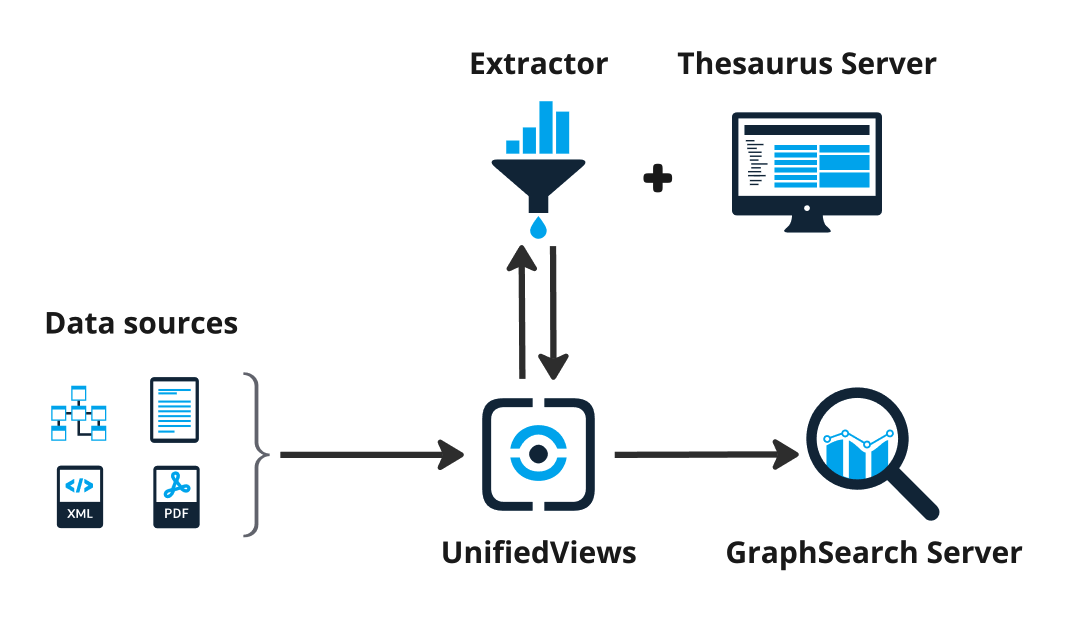
This figure schematically illustrates how the content is indexed and also showing component dependencies. The content for the recommender is tagged using concepts contained in the knowledge graph which is then embedded in the search index. When using the PoolParty Suite indexing is orchestrated by UnifiedViews with content being annotated by the PoolParty Extractor, whereas the knowledge model managed by the Thesaurus Server, and the PoolParty GraphSearch server containing the search index.
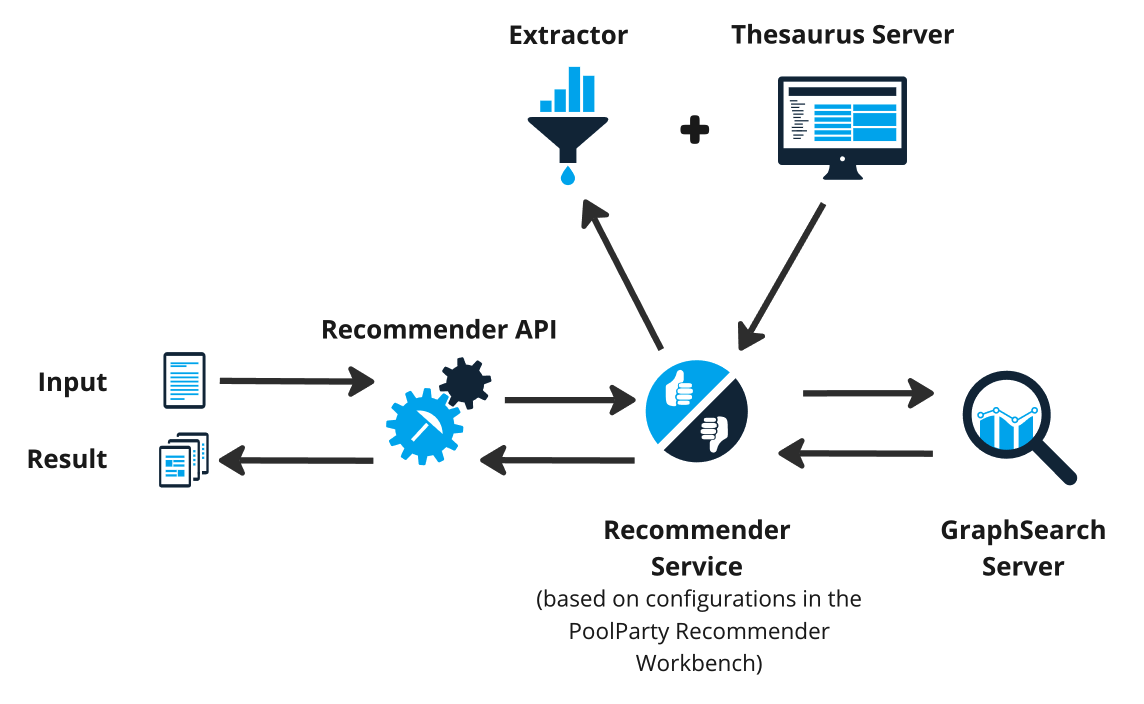
Above you can see a schematic representation of a recommendation retrieval workflow. Inputs (texts) are sent to the API of the recommender service. The PoolParty Extractor then takes over and annotates the input text whereas a semantic footprint is generated in the Thesaurus server. Afterwards the enrichment process involving the Thesaurus server takes place resulting in enrichment of the previously created concepts. The enriched input forms the query to the search index which is then executed on the GraphSearch server. The PoolParty Semantic Recommender synergistically combines the advantages of concept-based search with the full-text search functionality of Elasticsearch. Elasticsearch index is required for the last call, the recommendation. The recommendation results are generated based on the results of this query and returned to the API.