Zip Extraction Service
Zip Extraction Service
The Web Service methods available in this section allow you to manage .zip files of project documents, upload and download as well as defining the exact content of the respective .zip file.
Details find in these pages:
Web Service Method: Extract Metadata from Inside Zip File
Web Service Method: Extract Metadata from Inside Zip File
Description |
|---|
[file] Extracts and returns a list of documents with meaningful metadata like concepts and terms from documents which are packed inside a given archive file (*.zip) upload. |
URL: /extractor/api/extract/zip
Supported Methods |
|---|
POST |
multipart/form-data
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document |
file | MultipartFile | true | File to be extracted (word, excel, powerpoint, pdf, open documents) - Mimetype of file must be 'multipart/form-data' |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = false |
findPersonNames | boolean | false | Person name extraction, default = false |
language | String | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Location extraction, default = false |
metadata | String | false | Metadata of the document (concatenated fields with delimiter: '.') |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Furthermore it supports http://www.w3.org/1999/02/22-rdf-syntax-ns#type. Set to |
regexFilename | String | false | File name for regex patterns |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
tfidfScoring | boolean | false | Use TFIDF scoring |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
Attribute | Type | Comment |
|---|---|---|
property | String | Property |
value | String | Value |
This method returns execution results in JSON format.
Click here to expand Response Arrays and Attributes...
Results of a file based text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
aggregatedResponse | FileExtractionResponse | Aggregated result |
defaultExtractions | Array of FileExtractionResponse | List of extracted file results |
message | String | Additional message |
numberOfExtractedDocuments | int | Number of extracted documents |
Results of a file based text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
document | ExtractionResponse | Extraction result |
metadata | ExtractionResponse | Metadata extraction result |
text | String | File text content |
title | String | File title |
Results of an text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
categories | Array of Category | Categories of the document |
classificationResults | Array of DocumentClassification | Document classification results |
concepts | Array of ThesaurusConcept | Matched concepts |
detectedLanguage | String | Detected Language of the document |
extractedTerms | Array of ExtractedTerm | Extracted freeTerms |
locations | Array of Location | Matched locations |
personNames | Array of String | Person name matches |
regexMatches | Array of RegexMatches | Regex token matches |
sentiments | Array of Sentiment | Matched sentiments |
shadowConcepts | Array of ThesaurusConcept | Shadow Concepts |
text | String | Text as extracted from url or file |
title | String | Title as extracted from url or file |
Categorization result
Attribute | Type | Comment |
|---|---|---|
categoryConceptResults | Array of ConceptCategory | Categorized concepts |
prefLabel | String | Preferred label |
score | double | Score |
uri | String | Uri |
Categorized concept
Attribute | Type | Comment |
|---|---|---|
prefLabel | String | Preferred label |
score | double | Score |
uri | String | Uri |
A DocumentClassification object.
Attribute | Type | Comment |
|---|---|---|
predictedLabel | String | predictedLabel |
probabilities | Array of Prediction | Probabilities |
uri | String | URI of the classifier |
Concept from a PoolParty thesaurus project
Attribute | Type | Comment |
|---|---|---|
altLabels | Array of String | Alternative labels |
broaderConcepts | Array of String | URIs of all direct broader concepts |
conceptSchemes | Array of ThesaurusConceptScheme | The concept schemes this concept resides |
corporaScore | double | Relevance score - e.g. when extracted from a text |
customAttributes | Array of CustomAttribute | Custom attributes |
customRelations | Array of CustomRelation | Custom relations |
customSchemeTypes | Array of CustomSchemeType | URIs of the custom types assigned to the concept |
frequencyInDocument | int | Frequency of the concept in the text |
frequencyInDocuments | int | Frequency of the concept in the text |
hiddenLabels | Array of String | Hidden labels |
id | String | Concept id |
language | String | Language of the prefLabel, altLabels and hiddenLabels of this localized view of the concept |
matchingLabels | Array of MatchingLabel | Matching labels |
prefLabel | String | Preferred label |
project | String | UUID of the containing PoolParty project |
relatedConcepts | Array of String | URIs of all related concepts |
score | double | Normalized relevance score - e.g. when extracted from a text |
shadowConceptTerms | Array of ExtractedTerm | |
transitiveBroaderConcepts | Array of String | URIs of all transitive broader concepts |
transitiveBroaderTopConcepts | Array of String | URIs of all top concepts that this concept is connected to via a transitive broader-chain |
uri | String | Uniform resource identifier |
wordForms | Array of String | Lemmatized word forms |
ConceptScheme from a PoolParty thesaurus project - acts as a container for concepts
Attribute | Type | Comment |
|---|---|---|
title | String | The localized title of this concept scheme |
uri | String | Uniform resource identifier |
Custom attribute
Attribute | Type | Comment |
|---|---|---|
literal | Literal | Literal |
property | String | Property |
Custom Relation
Attribute | Type | Comment |
|---|---|---|
object | String | Object |
property | String | Property |
(PoolParty) concept scheme - acts as a container for concepts
Attribute | Type | Comment |
|---|---|---|
title | String | The name of this custom scheme type |
uri | String | Uniform resource identifier |
Phrase extracted from a text that does not match any Concepts
Attribute | Type | Comment |
|---|---|---|
corporaScore | double | Corpora score |
frequencyInDocument | int | Frequency within the document where it was extracted |
frequencyInDocuments | int | Frequency within the documents where it was extracted |
score | double | Relevance score |
textValue | String | The term phrase |
A geographical location extracted from a text
Attribute | Type | Comment |
|---|---|---|
countryCode | String | ISO 3166-1 alpha-2 country code |
latitude | float | Latitude |
longitude | float | Longitude |
matchedLabel | String | The location label that was found in the text |
name | String | Common name of the location |
score | Double | Relevance score |
type | LocationType | Location type - either city or country City | Country |
uri | String | Uniform resource identifier of the location |
Regex match
Attribute | Type | Comment |
|---|---|---|
regexMatches | Array of String | Tokens from the input text that match the regex pattern |
regexPattern | String | The original pattern used to match |
Sentiment result
Attribute | Type | Comment |
|---|---|---|
negativeTerms | Array of String | List of negative terms |
positiveTerms | Array of String | List of positive terms |
score | float | Score |
sentiment | String | Sentiment |
Web Service Method: Extract Metadata from Inside Zip File Asynchronously
Web Service Method: Extract Metadata from Inside Zip File Asynchronously
Description |
|---|
[file] Extracts asynchronously and returns a list of documents with meaningful metadata like concepts and terms from documents which are packed inside a given archive file (*.zip) upload. |
URL: /extractor/api/extract/zip/async
Supported Methods |
|---|
POST |
multipart/form-data
HTTP Parameter
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document |
file | MultipartFile | true | File to be extracted (word, excel, powerpoint, pdf, open documents) - Mimetype of file must be 'multipart/form-data' |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = false |
findPersonNames | boolean | false | Person name extraction, default = false |
language | String | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Location extraction, default = false |
metadata | String | false | Metadata of the document (concatenated fields with delimiter: '.') |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Furthermore it supports http://www.w3.org/1999/02/22-rdf-syntax-ns#type. Set to |
regexFilename | String | false | File name for regex patterns |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
tfidfScoring | boolean | false | Use TFIDF scoring |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
This method returns execution results in JSON format.
common base response defining the minimum result structure and semantics.
Attribute | Type | Comment |
|---|---|---|
message | String | short descriptive message of the operation result, or an error description |
result | Object | the actual response content body, defined by the resultType. |
resultType | String | MIME type of the result if successful, or Exception type if an error occurred |
status | int | HTTP status code of the requested operation |
success | boolean | true if the operation was successful (i.e. returning a status of 2xx) |
taskId | String |
Asynchronous Concept Extraction From a Zip Container
Asynchronous Concept Extraction From a Zip Container
With these services an asynchronous extraction processing of zip files is possible. This approach allows a client to receive the extraction response independent from requesting the service.
The client orders the processing of the provided file, receiving a taskId from the system to identify the processing task in later calls.
After receiving the file, the zip file is inserted into a processing pipeline.
Finally, the extraction result can be collected using the taskId as soon as the processing is finished.
Similar to Concept Extraction From a Zip Container there are two basic processing options for zip containers:
1) extraction results for each document individually
Mimetype of request must be 'multipart/form-data'
POST /extractor/api/extract/zip/async + zip file
2) extraction results aggregated for the whole zip container
Mimetype of request must be 'multipart/form-data'
POST /extractor/api/extract/zip/aggregated/async + zip file
GET /extractor/api/extract/zip/taskstatus?taskId
Returns the current status of the specified task in the extraction pipeline.
After the zip file passed the processing pipeline the result can be retrieved by providing the taskId. Depending on the processing option, defined during pipeline start, the results can be retrieved by using one of these services:
Returns a asynchronous called extraction identified by the task id
GET /extractor/api/extract/zip/task?taskId
Returns a asynchronous called aggregation extraction identified by the task id
GET /extractor/api/extract/zip/task/aggregated?taskId
Example showing usage of the async Extraction service
Step 1: insert zip file into pipeline & receive taskId as immediate response
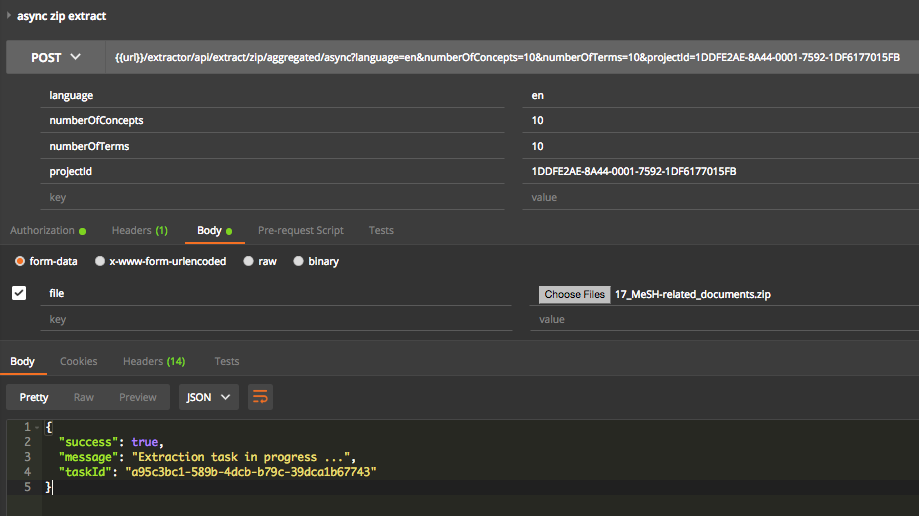
Step 2: check status of specified task
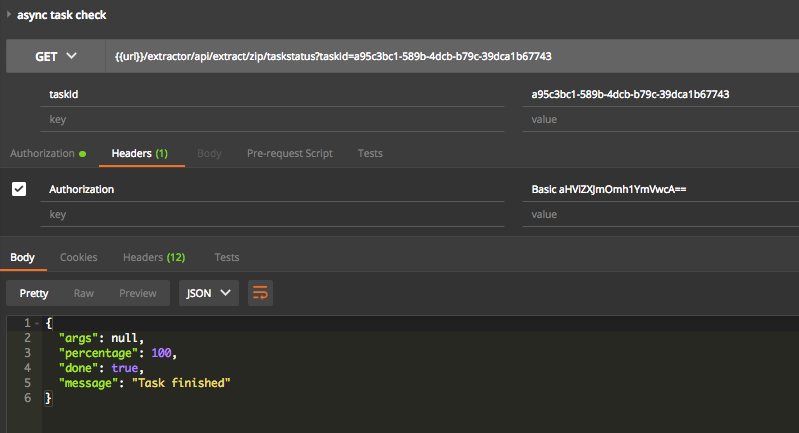
Step 3: retrieve extraction result of specific task after completion of the process
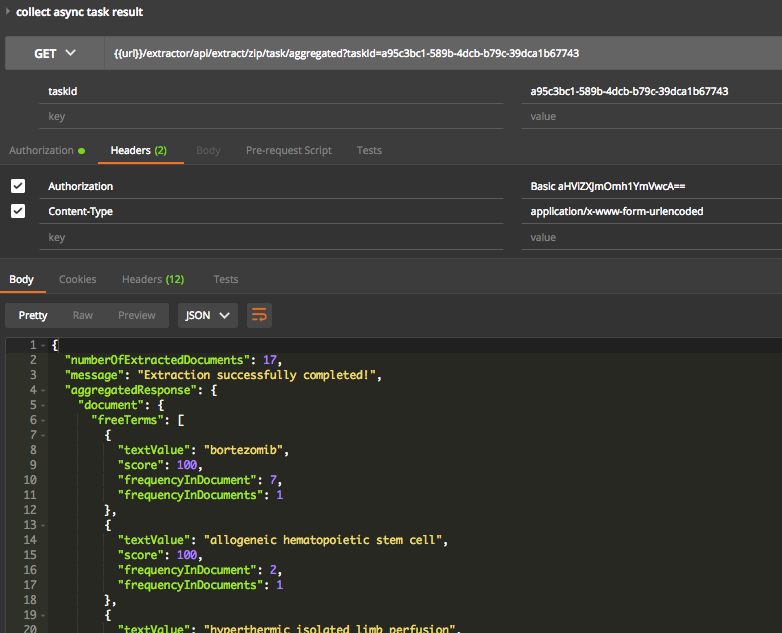
Web Service Method: Extract Metadata from Zip File - Aggregated
Web Service Method: Extract Metadata from Zip File - Aggregated
Description |
|---|
[file] Extracts and returns a single aggregated document with meaningful metadata like concepts and terms from documents which are packed inside a given archive file (*.zip) upload. |
URL: /extractor/api/extract/zip/aggregated
Supported Methods |
|---|
POST |
multipart/form-data
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document |
file | MultipartFile | true | File to be extracted (word, excel, powerpoint, pdf, open documents) - Mimetype of file must be 'multipart/form-data' |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = false |
findPersonNames | boolean | false | Person name extraction, default = false |
language | String | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Location extraction, default = false |
metadata | String | false | Metadata of the document (concatenated fields with delimiter: '.') |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Furthermore it supports http://www.w3.org/1999/02/22-rdf-syntax-ns#type. Set to |
regexFilename | String | false | File name for regex patterns |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
tfidfScoring | boolean | false | Use TFIDF scoring |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
Custom property
Attribute | Type | Comment |
|---|---|---|
property | String | Property |
value | String | Value |
This method returns execution results in JSON format.
Click here to expand Response Arrays and Attributes...
Results of an file based text extraction request. Properties with no entries are not present.
Attribute | Type | Comment |
|---|---|---|
aggregatedResponse | FileExtractionResponse | Aggregated result |
defaultExtractions | Array of FileExtractionResponse | List of extracted file results |
message | String | Additional message |
numberOfExtractedDocuments | int | Number of extracted documents |
Results of an file based text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
document | ExtractionResponse | Extraction result |
metadata | ExtractionResponse | Metadata extraction result |
text | String | File text content |
title | String | File title |
Results of an text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
categories | Array of Category | Categories of the document |
classificationResults | Array of DocumentClassification | Document classification results |
concepts | Array of ThesaurusConcept | Matched concepts |
detectedLanguage | String | Detected Language of the document |
extractedTerms | Array of ExtractedTerm | Extracted freeTerms |
locations | Array of Location | Matched locations |
personNames | Array of String | Person name matches |
regexMatches | Array of RegexMatches | Regex token matches |
sentiments | Array of Sentiment | Matched sentiments |
shadowConcepts | Array of ThesaurusConcept | Shadow Concepts |
text | String | Text as extracted from url or file |
title | String | Title as extracted from url or file |
Categorization result
Attribute | Type | Comment |
|---|---|---|
categoryConceptResults | Array of ConceptCategory | Categorized concepts |
prefLabel | String | Preferred label |
score | double | Score |
uri | String | Uri |
Categorized concept
Attribute | Type | Comment |
|---|---|---|
prefLabel | String | Preferred label |
score | double | Score |
uri | String | Uri |
DocumentClassification
A DocumentClassification object.
Attribute | Type | Comment |
|---|---|---|
predictedLabel | String | predictedLabel |
probabilities | Array of Prediction | Probabilities |
uri | String | URI of the classifier |
ThesaurusConcept
Concept from a PoolParty thesaurus project
Attribute | Type | Comment |
|---|---|---|
altLabels | Array of String | Alternative labels |
broaderConcepts | Array of String | URIs of all direct broader concepts |
conceptSchemes | Array of ThesaurusConceptScheme | The concept schemes this concept resides |
corporaScore | double | Relevance score - e.g. when extracted from a text |
customAttributes | Array of CustomAttribute | Custom attributes |
customRelations | Array of CustomRelation | Custom relations |
customSchemeTypes | Array of CustomSchemeType | URIs of the custom types assigned to the concept |
frequencyInDocument | int | Frequency of the concept in the text |
frequencyInDocuments | int | Frequency of the concept in the text |
hiddenLabels | Array of String | Hidden labels |
id | String | Concept id |
language | String | Language of the prefLabel, altLabels and hiddenLabels of this localized view of the concept |
matchingLabels | Array of MatchingLabel | Matching labels |
prefLabel | String | Preferred label |
project | String | UUID of the containing PoolParty project |
relatedConcepts | Array of String | URIs of all related concepts |
score | double | Normalized relevance score - e.g. when extracted from a text |
shadowConceptTerms | Array of ExtractedTerm | |
transitiveBroaderConcepts | Array of String | URIs of all transitive broader concepts |
transitiveBroaderTopConcepts | Array of String | URIs of all top concepts that this concept is connected to via a transitive broader-chain |
uri | String | Uniform resource identifier |
wordForms | Array of String | Lemmatized word forms |
ConceptScheme from a PoolParty thesaurus project - acts as a container for concepts
Attribute | Type | Comment |
|---|---|---|
title | String | The localized title of this concept scheme |
uri | String | Uniform resource identifier |
Custom attribute
Attribute | Type | Comment |
|---|---|---|
literal | Literal | Literal |
property | String | Property |
Custom Relation
Attribute | Type | Comment |
|---|---|---|
object | String | Object |
property | String | Property |
(PoolParty) concept scheme - acts as a container for concepts
Attribute | Type | Comment |
|---|---|---|
title | String | The name of this custom scheme type |
uri | String | Uniform resource identifier |
Phrase extracted from a text that does not match any Concepts
Attribute | Type | Comment |
|---|---|---|
corporaScore | double | Corpora score |
frequencyInDocument | int | Frequency within the document where it was extracted |
frequencyInDocuments | int | Frequency within the documents where it was extracted |
score | double | Relevance score |
textValue | String | The term phrase |
A geographical location extracted from a text
Attribute | Type | Comment |
|---|---|---|
countryCode | String | ISO 3166-1 alpha-2 country code |
latitude | float | Latitude |
longitude | float | Longitude |
matchedLabel | String | The location label that was found in the text |
name | String | Common name of the location |
score | Double | Relevance score |
type | LocationType | Location type - either city or country City | Country |
uri | String | Uniform resource identifier of the location |
Regex match
Attribute | Type | Comment |
|---|---|---|
regexMatches | Array of String | Tokens from the input text that match the regex pattern |
regexPattern | String | The original pattern used to match |
Sentiment result
Attribute | Type | Comment |
|---|---|---|
negativeTerms | Array of String | List of negative terms |
positiveTerms | Array of String | List of positive terms |
score | float | Score |
sentiment | String | Sentiment |
Concept Extraction From a Zip Container
Concept Extraction From a Zip Container
These services can be used to extract concepts and terms from content that is delivered in a zip container. This service is an extension to the main Concept Extraction Service, using a file.
Basically there are two ways of processing content in zip containers available:
Retrieve extraction results per document within the given zip container individually.
Retrieve extraction results aggregated for the whole zip container.
URL:
/extractor/api/extract/zip
URL:
/extractor/api/extract/zip/aggregated
Supported Methods |
|---|
POST |
multipart/form-data
Parameter | Type | Required | Comment |
|---|---|---|---|
file | MultipartFile | true | File to be extracted. Has to be a zip file. |
Other parameters can be used like in the main Concept Extraction Service for files.
You can use this file: cocktails.zip (containing three cocktails recipes in pdf format) together with a PoolParty project like e.g. 'All about Cocktails' (http://vocabulary.semantic-web.at/cocktails.html)
POST http://vocabulary.semantic-web.at/extractor/api/extract/zip?language=en&numberOfConcepts=3&numberOfTerms=0&projectId=1DCE0ED2-D7E8-0001-86A1-18652DF0D7A0 Content-Type: multipart/form-data file: cocktails.zip
Sample request, done with Postman:
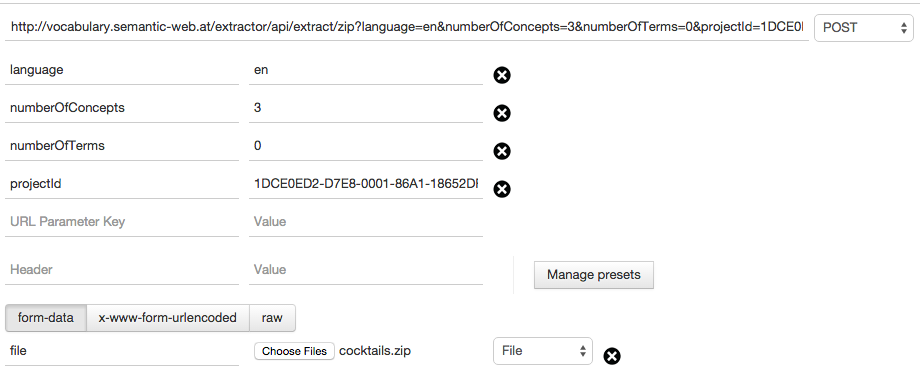 |
Postman sample requests: Postman-zip_extraction.json
You can import the json file into e.g. Postman REST Client.
Sample request, done with curl:
curl -i -X POST -H "Content-Type: multipart/form-data" -F "file=@cocktails.zip" http://USERNAME:PASSWORD@vocabulary.semantic-web.at/extractor/api/extract/zip?language=en&numberOfConcepts=3&numberOfTerms=0&projectId=1DCE0ED2-D7E8-0001-86A1-18652DF0D7A0&displayText=true
Web Service Method: Extract Metadata from Zip File - Aggregated and Asynchronously
Web Service Method: Extract Metadata from Zip File - Aggregated and Asynchronously
Description |
|---|
[file] Extracts asynchronously and returns a single aggregated document with meaningful metadata like concepts and terms from documents which are packed inside a given archive file (*.zip) upload'. |
URL: /extractor/api/extract/zip/aggregated/async
Supported Methods |
|---|
POST |
multipart/form-data
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document |
file | MultipartFile | true | File to be extracted (word, excel, powerpoint, pdf, open documents) - Mimetype of file must be 'multipart/form-data' |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = false |
findPersonNames | boolean | false | Person name extraction, default = false |
language | String | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Location extraction, default = false |
metadata | String | false | Metadata of the document (concatenated fields with delimiter: '.') |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Furthermore it supports http://www.w3.org/1999/02/22-rdf-syntax-ns#type. Set to all to fetch all properties. |
regexFilename | String | false | File name for regex patterns |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
tfidfScoring | boolean | false | Use TFIDF scoring |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
Attribute | Type | Comment |
|---|---|---|
property | String | Property |
value | String | Value |
This method returns execution results in JSON format.
Common base response defining the minimum result structure and semantics.
Attribute | Type | Comment |
|---|---|---|
message | String | short descriptive message of the operation result, or an error description |
result | Object | the actual response content body, defined by the resultType. |
resultType | String | MIME type of the result if successful, or Exception type if an error occurred |
status | int | HTTP status code of the requested operation |
success | boolean | true if the operation was successful (i.e. returning a status of 2xx |
taskId | String |
Web Service Method: Request an Aggregated Task Synchronously
Web Service Method: Request an Aggregated Task Synchronously
Description |
|---|
Returns a synchronous called aggregation extraction identified by the task ID. |
URL: /extractor/api/extract/zip/task/aggregated
Supported Methods |
|---|
GET |
application/x-www-form-urlencoded
Parameter | Type | Required | Description |
|---|---|---|---|
taskId | String | true | Task ID of the asynchronous called task. |
This method returns execution results in JSON format.
Click here to expand Response Arrays and Attributes...
Results of an file based text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
aggregatedResponse | FileExtractionResponse | Aggregated result |
defaultExtractions | Array of FileExtractionResponse | List of extracted file results |
message | String | Additional message |
numberOfExtractedDocuments | int | Number of extracted documents |
Results of an file based text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
document | ExtractionResponse | Extraction result |
metadata | ExtractionResponse | Metadata extraction result |
text | String | File text content |
title | String | File title |
Results of an text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
categories | Array of Category | Categories of the document |
classificationResults | Array of DocumentClassification | Document classification results |
concepts | Array of ThesaurusConcept | Matched concepts |
detectedLanguage | String | Detected Language of the document |
extractedTerms | Array of ExtractedTerm | Extracted freeTerms |
locations | Array of Location | Matched locations |
personNames | Array of String | Person name matches |
regexMatches | Array of RegexMatches | Regex token matches |
sentiments | Array of Sentiment | Matched sentiments |
shadowConcepts | Array of ThesaurusConcept | Shadow Concepts |
text | String | Text as extracted from url or file |
title | String | Title as extracted from url or file |
Categorization result
Attribute | Type | Comment |
|---|---|---|
categoryConceptResults | Array of ConceptCategory | Categorized concepts |
prefLabel | String | Preferred label |
score | double | Score |
uri | String | Uri |
Categorized concept
Attribute | Type | Comment |
|---|---|---|
prefLabel | String | Preferred label |
score | double | Score |
uri | String | Uri |
A DocumentClassification object.
Attribute | Type | Comment |
|---|---|---|
predictedLabel | String | predictedLabel |
probabilities | Array of Prediction | Probabilities |
uri | String | URI of the classifier |
Concept from a PoolParty thesaurus project
Attribute | Type | Comment |
|---|---|---|
altLabels | Array of String | Alternative labels |
broaderConcepts | Array of String | URIs of all direct broader concepts |
conceptSchemes | Array of ThesaurusConceptScheme | The concept schemes this concept resides |
corporaScore | double | Relevance score - e.g. when extracted from a text |
customAttributes | Array of CustomAttribute | Custom attributes |
customRelations | Array of CustomRelation | Custom relations |
customSchemeTypes | Array of CustomSchemeType | URIs of the custom types assigned to the concept |
frequencyInDocument | int | Frequency of the concept in the text |
frequencyInDocuments | int | Frequency of the concept in the text |
hiddenLabels | Array of String | Hidden labels |
id | String | Concept id |
language | String | Language of the prefLabel, altLabels and hiddenLabels of this localized view of the concept |
matchingLabels | Array of MatchingLabel | Matching labels |
prefLabel | String | Preferred label |
project | String | UUID of the containing PoolParty project |
relatedConcepts | Array of String | URIs of all related concepts |
score | double | Normalized relevance score - e.g. when extracted from a text |
shadowConceptTerms | Array of ExtractedTerm | |
transitiveBroaderConcepts | Array of String | URIs of all transitive broader concepts |
transitiveBroaderTopConcepts | Array of String | URIs of all top concepts that this concept is connected to via a transitive broader-chain |
uri | String | Uniform resource identifier |
wordForms | Array of String | Lemmatized word forms |
ConceptScheme from a PoolParty thesaurus project - acts as a container for concepts
Attribute | Type | Comment |
|---|---|---|
title | String | The localized title of this concept scheme |
uri | String | Uniform resource identifier |
Custom attribute
Attribute | Type | Comment |
|---|---|---|
literal | Literal | Literal |
property | String | Property |
Custom Relation
Attribute | Type | Comment |
|---|---|---|
object | String | Object |
property | String | Property |
(PoolParty) concept scheme - acts as a container for concepts
Attribute | Type | Comment |
|---|---|---|
title | String | The name of this custom scheme type |
uri | String | Uniform resource identifier |
Phrase extracted from a text that does not match any Concepts
Attribute | Type | Comment |
|---|---|---|
corporaScore | double | Corpora score |
frequencyInDocument | int | Frequency within the document where it was extracted |
frequencyInDocuments | int | Frequency within the documents where it was extracted |
score | double | Relevance score |
textValue | String | The term phrase |
A geographical location extracted from a text
Attribute | Type | Comment |
|---|---|---|
countryCode | String | ISO 3166-1 alpha-2 country code |
latitude | float | Latitude |
longitude | float | Longitude |
matchedLabel | String | The location label that was found in the text |
name | String | Common name of the location |
score | Double | Relevance score |
type | LocationType | Location type - either city or country City | Country |
uri | String | Uniform resource identifier of the location |
Regex match
Attribute | Type | Comment |
|---|---|---|
regexMatches | Array of String | Tokens from the input text that match the regex pattern |
regexPattern | String | The original pattern used to match |
Sentiment result
Attribute | Type | Comment |
|---|---|---|
negativeTerms | Array of String | List of negative terms |
positiveTerms | Array of String | List of positive terms |
score | float | Score |
sentiment | String | Sentiment |
Web Service Method: Request a Task's Status
Web Service Method: Request a Task's Status
Description |
|---|
Returns the current status of an asynchronously called extraction identified by the task ID. |
URL: /extractor/api/extract/zip/taskstatus
Supported Methods |
|---|
GET |
application/x-www-form-urlencoded
Parameter | Type | Required | Description |
|---|---|---|---|
taskId | String | true | Task id of the asynchronous called task |
BASIC_AUTH | String | false | |
CLIENT_CERT_AUTH | String | false | |
DIGEST_AUTH | String | false | |
FORM_AUTH | String | false |
This method returns execution results in JSON format.
A TaskStatus object.
Web Service Method: Request Task Information from Zip
Web Service Method: Request Task Information from Zip
Description |
|---|
Returns an asynchronously called extraction identified by the task ID. |
URL: /extractor/api/extract/zip/task
Supported Methods |
|---|
GET |
Content-Type: application/json
This method returns execution results in JSON format.
Parameter | Description | Type | Required |
|---|---|---|---|
taskId | Task ID of the asynchronously called task | String | true |