DPU Extensions
DPU Extensions
DPU Developers may use or create DPU extensions. The extensions which are available and may be used are described in the following topics:
If you want to create new extensions, please be inspired by one of the existing extensions, for example: FaultTolerance extension.
Dynamic Configuration of the DPU Using RDF Configuration
Dynamic Configuration of the DPU Using RDF Configuration
This section contains a short guide on the dynamic configuration of a DPU.
Dynamic configuration allows a DPU to be configured dynamically over one of its input data unit (configuration input data unit).
If the DPU supporting dynamic configuration, receives certain configuration over its configuration input data unit, it is used instead of stored configuration for the given DPU. Dynamic configuration is defined in RDF data format.
Dynamic configuration support may be added to the DPU by defining RdfConfiguration extension:
@ExtensionInitializer.Init public RdfConfiguration _rdfConfiguration;
Additionally you can define one of the input data units to the DPU as configuration data unit:
@RdfConfiguration.ContainsConfiguration @DataUnit.AsInput(name = "config", optional = true) public RDFDataUnit rdfConfiguration;
Sample main class using dynamic configuration: https://github.com/UnifiedViews/Plugins/blob/master/e-filesDownload/src/main/java/eu/unifiedviews/plugins/extractor/filesdownload/FilesDownload.java
Further, the config class of the DPU has to be annotated, so that it is clear how the RDF classes and properties are mapped to the config class and attributes of the config class.For details, refer to the sample config annotated: https://github.com/UnifiedViews/Plugins/blob/master/e-filesDownload/src/main/java/eu/unifiedviews/plugins/extractor/filesdownload/FilesDownloadConfig_V1.java
The RDF configuration e-filesDownload supports: https://github.com/UnifiedViews/Plugins/blob/97bcdcfc24da88411cbdf61000756a1ab5ec9752/e-filesDownload/doc/About.md
Note
Do not use blank nodes in the RDF configuration dynamically configuring the target DPU.
For collections of items use
LinkedList.
Helpers for Adding Entries to RDF/Files Output Data Unit
Helpers for Adding Entries to RDF/Files Output Data Unit
This section contains a short guide on how to use helpers for adding RDF triples and files to output data units.
For basic information about data units, please refer to: Basic Concepts for DPU Developers.
To see the core data unit interfaces and how the particular types of data units (RDF, Files) extend such interfaces, please look at .
Helpers described on this page are advanced helpers which support adding of entries (files, triples) to output data units (Files, RDF data units). There are also data unit helpers, such as FilesHelper, which should be also considered. Such helpers have certain disadvantage, but are a bit simpler to be used.
The DPU extensions described on this page do not support reading of entries. For reading entries from input data units, please see this tutorial.
Refer to this tutorial how to use these simpler helpers. In general, you should use DPU extensions described on this page (rather than the simpler helpers) for adding entries to an output data unit if you to write your DPUs fault tolerant. For a more detailed comparison of these helpers, see here.
This helper is an extension.
Before this extension can be used, you have to insert the following code to the Main DPU class, where param in Line 1 contains the name of the data unit the helper wraps (in this case 'output').
@ExtensionInitializer.Init(param = "output") public WritableSimpleFiles outputFilesHelper;
There are two methods DPU developers may use to add files to the output files data unit (using the helper):
public File create(final String fileName) throws DPUException
This method created new empty file in the
outputdata unit with thesymbolicNameandvirtualPathmetadata equal tofileName. For explanation ofsymbolicNames,virtualPathand other metadata of entries in data units, please see Basic Concepts for DPU Developers . The physical name of the create file is generated and the file is physically stored in the working directory of the given pipeline execution.
public void add(final File file, final String fileName) throws DPUException
This method adds existing
fileto the output data unit. It automatically creates new entry in theoutputdata unit with thesymbolicNameandvirtualPathmetadata equal tofileName. For explanation of symbolicNames, virtualPath and other metadata of entries in data units, please see Basic Concepts for DPU Developers . In this case, the real location and the physical name of the file is as it was when it was created before calling this method. Be careful that in this case, the file is not created in the working space of the given pipeline execution.
Without using this helper, the task of adding an existing file may be executed as follows:
Symbolic symbolicName = output.addExistingFile(fileName, file.toURI().toString()); MetadataUtils.set(output, symbolicName, FilesVocabulary.UV_VIRTUAL_PATH, fileName);
In Line 1 the new entry in the output data unit is created and for such entry
symbolicNameandfileURIis set.Line 2 then sets
virtualPathmetadata for the same entry.
The advantage of the helper is that the code is cleaner: compare the code needed to add existing file to the output file data unit, which is one line (with helper) vs. two lines (when the helper is not used).
Additionally, when the helper is not used, you as a DPU developer must be aware of virtualPath metadata, must know that the recommended practice is to set virtualPath = symbolicName.
This helper is an extension.
Before this extension can be used, the following code has to be inserted to the Main DPU class, where param in Line 1 contains name of the data unit the helper wraps (in this case 'output').
@ExtensionInitializer.Init(param = "output") public WritableSimpleRdf outputRdfHelper;
There are two methods DPU developers may use to add RDF triples to the output RDF data unit (using the helper):
public WritableSimpleRdf add(Resource s, URI p, Value o) throws
SimpleRdfException,DPUExceptionThis method adds one triple to the
outputRDF data unit. Please see the example below how Resources, URIs and Values (all classes from openRDF API) may be used.
public WritableSimpleRdf add(List<Statement> statements) throws SimpleRdfException, DPUException
This method adds list of statements (triples) previously prepared using openRDF API.
Sample usage of the first method add(Resource s, URI p, Value o) is depicted below:
org.openrdf.model.ValueFactory vf = outputRdfHelper.getValueFactory(); org.openrdf.model.URI s = valueFactory.createURI(http://data.example.com/resource/subjectS); org.openrdf.model.URI p = valueFactory.createURI(http://data.example.com/resource/predicateP); org.openrdf.model.Value = valueFactory.createLiteral(rowNumber) add(s,p,o);
By default, calling the add methods above, the triples are added to the default entry (RDF graph), automatically generated for you in the output data unit, the wrapper wraps. The symbolicName of the default entry is set to default-output.In typical cases, preparing one entry (RDF graph), where all the data (triples) is loaded, is sufficient.
In certain cases, if you already prepared an entry (e.g. by using RDFDataUnitUtils), you may specify that you want to add triples to this prepared entry (and not to the default entry generated) by calling:
public WritableSimpleRdf setOutput(RDFDataUnit.Entry entry) throws SimpleRdfException, DPUException
This method sets the output entry (RDF graph) to which data (triples) is added. This must be called before any method for adding triples (see above) is called.
public WritableSimpleRdf setOutput(final List<RDFDataUnit.Entry> entries) throws SimpleRdfException, DPUException
This method sets the output entry (RDF graph) to which data (triples) is added. This must be called before any method for adding triples (see above) is called. If the list of entries contains more then one entry then the added triples are automatically added to more output data unit entries (RDF graphs)
uses output.setOutput() and output.add()
uses output.add()
uses output.setOutput() and output.add()
RDF Profiler Extension
RDF Profiler Extension
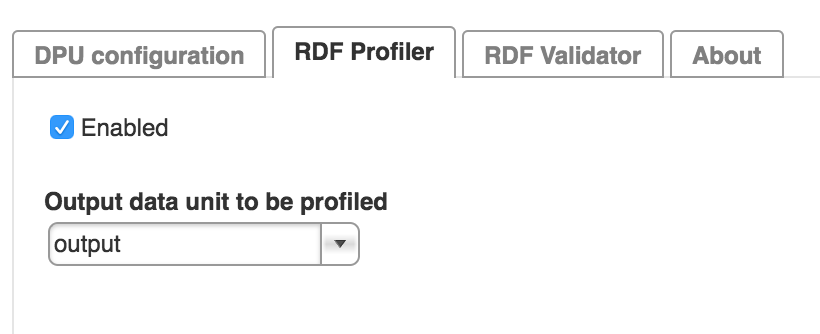
Existing Core Plugins, which output RDF data, can use the RDF Profiler extension (from the respective versions of these DPUs which use UnifiedViews API 3.0.1-SNAPSHOT+). To activate that, just go to the DPU configuration, RDF Profiler tab, where you can decide to profile output data produced by certain output RDF data unit of your choice.
 |
Then, when running the DPU having profiler enabled, profiler is automatically executed after the execution of that DPU and a new message appears in the Events Monitor showing reports about the results of profiling.
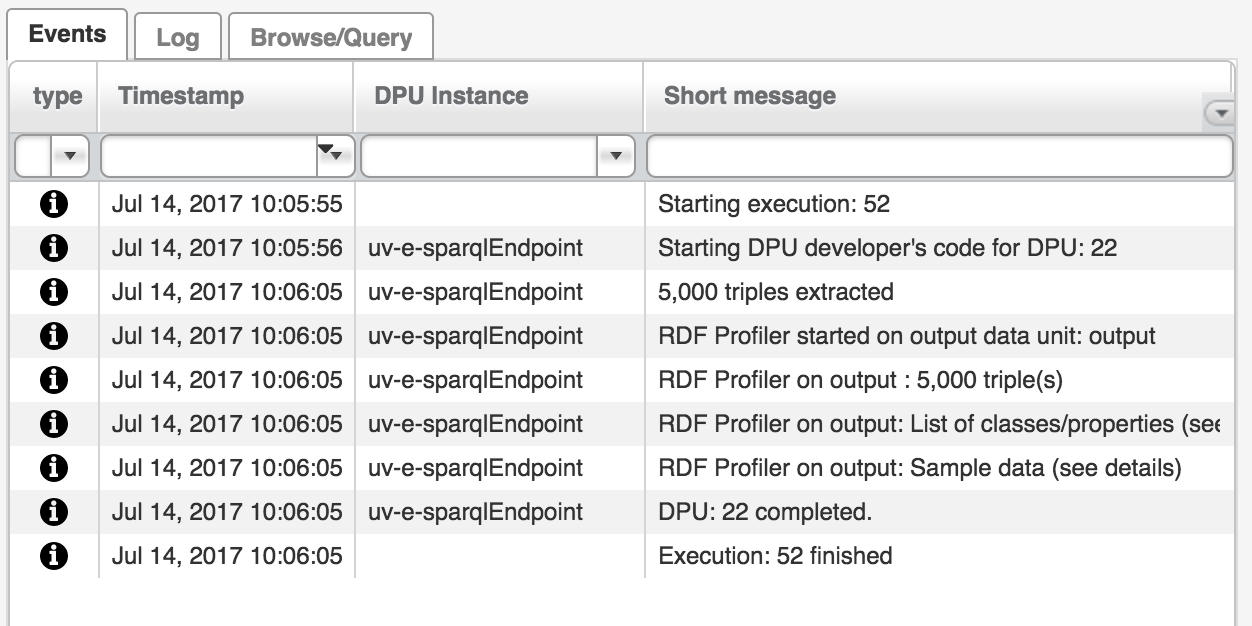 |
In particular, it shows:
Number of triples in the data unit
Top 100 classes and number of instances for each such class
Top 100 predicates and number of occurrences for each such predicate
Descriptions of up to 5 sample resources for the most often used classes from top 100 classes
See below sample reports:
 |
 |
You may simply turn on for every DPU RDF Profiler extension by inserting the following fragment to you main DPU class:
@ExtensionInitializer.Init public RdfProfiler rdfProfiler;
Note
In order to use this extension, you have to build your DPUs with Plugin-devEnv version 3.0.1-SNAPSHOT+. In pom.xml, you have to define:
<parent> <groupId>eu.unifiedviews</groupId> <artifactId>uv-pom-dpu</artifactId> <version>3.0.1-SNAPSHOT</version> <relativePath /> </parent>
RDF Validation Extension
RDF Validation Extension
You may simply turn on for every DPU RDF Validation extension by inserting the following fragment to your main DPU class:
@ExtensionInitializer.Init public RdfValidation rdfValidation;
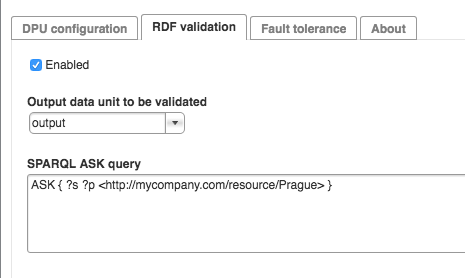
As a result, after importing such DPU to UnifiedViews (2.X), pipeline designer may decide to check output produced by certain output RDF data unit. In particular, pipeline designer may select which output RDF data unit should be checked and may define SPARQL ASK queries checking the outputted RDF data. If the SPARQL ask query returns false, the given output is INVALID and an error is reported.
 |
Note
You may define only one SPARQL ASK query
if you need to check that graph pattern A OR graph pattern B is satisfied, you may use UNION:
ASK WHERE {
{<http://dbpedia.org/resource/Prague> owl:sameAs <http://mycompany.com/resource/Prague> }
UNION {<http://dbpedia.org/resource/Prague> owl:sameAs <http://mycompany.com/resource/Prag>}
}
If you need to check that pattern A AND pattern B are both satisfied, you may use the following approach:
ASK WHERE {
{<http://dbpedia.org/resource/Prague> owl:sameAs <http://mycompany.com/resource/Prague> }
{<http://dbpedia.org/resource/Prague> owl:sameAs <http://mycompany.com/resource/Prag>}
}
Note
In order to use this extension, you have to build your DPUs with Plugin-devEnv version 2.1.7+. In pom.xml, you have to define:
<parent> <groupId>eu.unifiedviews</groupId> <artifactId>uv-pom-dpu</artifactId> <version>2.1.7</version> <relativePath /> </parent>
Note
To check the number of triples in the given RDF data unit:
#check there is 197 triples extracted
ASK {
{
SELECT (COUNT(*) as ?count)
WHERE {
?s ?p ?o
}
}
FILTER (?count=197)
}