Concept Extraction Service
Concept Extraction Service
The PoolParty Extraction Service allows you to send text to the API. The return will be a defined number of concepts from a thesaurus and/or a defined number of terms relevant for the text.
This API call accepts plain text, a web page referenced by a URL, and an uploaded file as input.
Example URL
https://<your server>/extractor/api/extract
Find details in the following topics:
Web Service Method: Extract from Text
Description |
|---|
Extracts and returns meaningful metadata like concepts and terms from a given text. |
URL: /extractor/api/extract
Request
Supported Methods |
|---|
POST |
GET |
HTTP Parameters
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptMinimumScore | Double | false | Minimum required score of concepts, default = 0 |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUIDs) are provided |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property URI and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from given text in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document, taken from documentUri |
extraConceptLanguages | Array of PPLocale | false | Additional languages used for concept extraction (en|de|es|fr|...); also supports wildcard * for all language |
extractorVersion | String | false | Version of PPX Extractor used |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = false |
findPersonNames | boolean | false | Deprecated (use nerParameters) - extracts person names from the given text |
language | PPLocale | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Deprecated (use nerParameters) - extracts locations from a given text |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition. |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
phraseLength | Integer | false | Phrase length, default = 4 |
projectId | Array of String | false | Thesaurus' project ID |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Furthermore it supports http://www.w3.org/1999/02/22-rdf-syntax-ns#type. Set to |
regexFilename | String | false | File name for regex patterns |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation; enabled if corpusIds (UUID) are provided |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
text | String | true | Text of the document |
tfidfScoring | boolean | false | Use TFIDF scoring |
title | String | false | Title of the document |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
CustomProperty
Custom property
Attribute | Type | Comment |
|---|---|---|
property | String | Property |
value | String | Value |
PPLocale
A PPLocale object
Attribute | Type | Comment |
|---|---|---|
ALL_LANGUAGES | PPLocale | |
DUTCH | PPLocale | |
ENGLISH | PPLocale | |
FRENCH | PPLocale | |
GERMAN | PPLocale | |
RUSSIAN | PPLocale | |
SPANISH | PPLocale | |
VALID | PPLocale | |
country | String | |
language | String | |
languageTag | String |
NERConfig
Named Entity Recognition configuration
Attribute | Type | Comment |
|---|---|---|
classUri | String | Class URI given to identified Named Entities |
method | Method | Method used for Named Entity Extraction. (default: MAXIMUM_ENTROPY) RULE_BASED | MAXIMUM_ENTROPY |
type | String | Type of Named Entity Model; predefined models for MAXIMUM_ENTROPY: person, organization, location |
Example of a Named Entity Recognition Usage:
|
Response
Returns
Content-Type: application/json
Response Attributes
Arrays of Response Attributes
ExtractionResponse
Results of a text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
categories | Array of Category | Categories of the document |
classificationResults | Array of DocumentClassification | Document classification results |
concepts | Array of ThesaurusConcept | Matched concepts |
detectedLanguage | PPLocale | Detected Language of the document |
extractedTerms | Array of ExtractedTerm | Extracted freeTerms |
locations | Array of Location | Matched locations |
namedEntities | Array of NamedEntityResponse | Deprecated |
personNames | Array of String | Person name matches |
regexMatches | Array of RegexMatches | Regex token matches |
sentiments | Array of Sentiment | Matched sentiments |
shadowConcepts | Array of ShadowConceptResponse | Shadow Concepts |
text | String | Text as extracted from url or file |
title | String | Title as extracted from url or file |
Category
Categorization result
Attribute | Type | Comment |
|---|---|---|
categoryConceptResults | Array of ConceptCategory | Categorized concepts |
prefLabel | String | Preferred label |
score | double | Score between 0.0-100.0 |
uri | String | Category URI |
ConceptCategory
Categorized concept
Attribute | Type | Comment |
|---|---|---|
prefLabel | String | Preferred label |
score | double | Score from 0.0 to 100.0 |
uri | String | URI |
DocumentClassification
A DocumentClassification object.
Attribute | Type | Comment |
|---|---|---|
predictedLabel | String | predictedLabel |
probabilities | Array of Prediction | Probabilities |
uri | String | URI of the classifier |
ThesaurusConcept
Concept from a PoolParty thesaurus project.
Attribute | Type | Comment |
|---|---|---|
altLabels | Map of PPLocale | Alternative labels |
broaderConcepts | Array of String | URIs of all direct broader concepts |
conceptSchemes | Array of ThesaurusConceptScheme | The concept schemes this concept resides |
corporaScore | Double | Relevance score - e.g. when extracted from a text |
customAttributes | Array of CustomAttribute | Custom attributes |
customRelations | Array of CustomRelation | Custom relations |
customSchemeTypes | Array of CustomSchemeType | URIs of the custom types assigned to the concept |
frequencyInDocument | int | Frequency of the concept in the text |
frequencyInDocuments | int | Frequency of the concept in the text |
hiddenLabels | Map of PPLocale | Hidden labels |
id | String | Concept id |
languages | Array of PPLocale | Language of the prefLabel, altLabels and hiddenLabels of this localized view of the concept |
matchingLabels | Array of MatchingLabel | Matching labels |
prefLabels | Map of PPLocale | Preferred label |
project | String | UUID of the containing PoolParty project |
relatedConcepts | Array of String | URIs of all related concepts |
score | double | Normalized relevance score - e.g. when extracted from a text |
transitiveBroaderConcepts | Array of String | URIs of all transitive broader concepts |
transitiveBroaderTopConcepts | Array of String | URIs of all top concepts that this concept is connected to via a transitive broader-chain |
uri | String | Uniform resource identifier |
wordForms | Array of String | Lemmatized word forms |
ThesaurusConceptScheme
ConceptScheme from a PoolParty thesaurus project - acts as a container for concepts.
Attribute | Type | Comment |
|---|---|---|
title | String | The localized title of this concept scheme |
uri | String | Uniform resource identifier |
CustomAttribute
Custom attribute
Attribute | Type | Comment |
|---|---|---|
literal | Literal | Literal |
property | String | Property |
CustomRelation
Custom Relation
Attribute | Type | Comment |
|---|---|---|
object | String | Object |
property | String | Property |
CustomSchemeType
(PoolParty) concept scheme - acts as a container for concepts.
Attribute | Type | Comment |
|---|---|---|
title | String | The name of this custom scheme type |
uri | String | Uniform resource identifier |
ExtractedTerm
Phrase extracted from a text that does not match any concepts.
Attribute | Type | Comment |
|---|---|---|
corporaScore | double | Corpora score |
frequencyInDocument | int | Frequency within the document where it was extracted |
frequencyInDocuments | int | Frequency within the documents where it was extracted |
score | double | Relevance score |
textValue | String | The term phrase |
Location
A geographical location extracted from a text.
Attribute | Type | Comment |
|---|---|---|
countryCode | String | ISO 3166-1 alpha-2 country code |
latitude | float | Latitude |
longitude | float | Longitude |
matchedLabel | String | The location label that was found in the text |
name | String | Common name of the location |
score | Double | Relevance score |
type | LocationType | Location type - either city or country City | Country |
uri | String | Uniform resource identifier of the location |
NamedEntityResponse
Named Entity
Attribute | Type | Comment |
|---|---|---|
frequency | int | Frequency in document |
metadata | Map of String | Metadata |
method | String | Method |
positions | Array of SimpleTokenPosition | Position |
score | double | Score |
textValue | String | Matched text |
type | String | Type |
RegexMatches
Regex match
Attribute | Type | Comment |
|---|---|---|
regexMatches | Array of String | Tokens from the input text that match the regex pattern |
regexPattern | String | The original pattern used for matching |
Sentiment
Sentiment result
Attribute | Type | Comment |
|---|---|---|
negativeTerms | Array of String | List of negative terms |
positiveTerms | Array of String | List of positive terms |
score | float | Score |
sentiment | String | Sentiment |
ShadowConceptResponse
Shadow concept
Attribute | Type | Comment |
|---|---|---|
altLabels | Map of PPLocale | Alternative labels |
broaderConcepts | Array of String | URIs of all direct broader concepts |
conceptSchemes | Array of ThesaurusConceptScheme | The concept schemes this concept resides |
corporaScore | Double | Relevance score - e.g. when extracted from a text |
customAttributes | Array of CustomAttribute | Custom attributes |
customRelations | Array of CustomRelation | Custom relations |
customSchemeTypes | Array of CustomSchemeType | URIs of the custom types assigned to the concept |
hiddenLabels | Map of PPLocale | Hidden labels |
id | String | Concept id |
languages | Array of PPLocale | Language of the prefLabel, altLabels and hiddenLabels of this localized view of the concept |
prefLabels | Map of PPLocale | Preferred label |
project | String | UUID of the containing PoolParty project |
relatedConcepts | Array of String | URIs of all related concepts |
score | double | Normalized relevance score - e.g. when extracted from a text |
shadowConceptTerms | Array of ShadowTerm | Extracted terms that contribute to calculation of the shadow concept |
transitiveBroaderConcepts | Array of String | URIs of all transitive broader concepts |
transitiveBroaderTopConcepts | Array of String | URIs of all top concepts that this concept is connected to via a transitive broader-chain |
uri | String | Uniform resource identifier |
ShadowTerm
Phrase extracted from a text that does not match any Concepts
Attribute | Type | Comment |
|---|---|---|
score | double | Relevance score |
textValue | String | The term phrase |
Web Service Method: Extract from File
Web Service Method: Extract from File
Description |
|---|
Extracts and returns meaningful metadata like concepts and terms from a given file upload. |
URL: /extractor/api/extract
Request
Supported Methods |
|---|
POST |
Content-Type:
multipart/form-data
HTTP Parameters
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
charset | String | false | Character set used in the File |
conceptMinimumScore | Double | false | Minimum required score of concepts, default = 0 |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided. |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from file in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input. |
documentId | String | false | Internal ID of the document |
extraConceptLanguages | Array of PPLocale | false | Additional languages used for concept extraction (en|de|es|fr|...) Also supports wildcard * for all language |
extractorVersion | String | false | Version of PPX Extractor used |
file | MultipartFile | true | File to be extracted (word, excel, powerpoint, pdf, open documents) - Mimetype of file must be 'multipart/form-data' |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = false |
findPersonNames | boolean | false | Deprecated (use nerParameters) - extracts person names from the given text |
language | PPLocale | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = false |
locationExtraction | boolean | false | Deprecated (use nerParameters) - extracts locations from the given text |
metadata | String | false | Metadata of the document (concatenated fields with delimiter: '.') |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
phraseLength | Integer | false | Phrase length, default = 4 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. |
regexFilename | String | false | File name for regex patterns |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
tfidfScoring | boolean | false | Use TFIDF scoring |
title | String | false | Title of the document |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
Custom property
Attribute | Type | Comment |
|---|---|---|
property | String | Property |
value | String | Value |
PPLocale
A PPLocale object
Attribute | Type | Comment |
|---|---|---|
ALL_LANGUAGES | PPLocale | |
DUTCH | PPLocale | |
ENGLISH | PPLocale | |
FRENCH | PPLocale | |
GERMAN | PPLocale | |
RUSSIAN | PPLocale | |
SPANISH | PPLocale | |
VALID | PPLocale | |
country | String | |
language | String | |
languageTag | String |
A MultipartFile object
Named Entity Recognition configuration
Attribute | Type | Required | Comment |
|---|---|---|---|
classUri | String | false | Class URI given to identified Named Entities |
method | Method | false | Method used for Named Entity Extraction. (default: MAXIMUM_ENTROPY) RULE_BASED | MAXIMUM_ENTROPY |
type | String | false | Type of Named Entity Model. Pre-defined models for MAXIMUM_ENTROPY: person, organization, location |
|
Content-Type: application/json
Results of a file based text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
document | ExtractionResponse | Extraction result |
metadata | ExtractionResponse | Metadata extraction result |
text | String | File text content |
title | String | File title |
Results of a text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
categories | Array of Category | Categories of the document |
classificationResults | Array of DocumentClassification | Document classification results |
concepts | Array of ThesaurusConcept | Matched concepts |
detectedLanguage | PPLocale | Detected Language of the document |
extractedTerms | Array of ExtractedTerm | Extracted freeTerms |
locations | Array of Location | Matched locations |
namedEntities | Array of NamedEntityResponse | Named Entities |
personNames | Array of String | Deprecated |
regexMatches | Array of RegexMatches | Regex token matches |
sentiments | Array of Sentiment | Matched sentiments |
shadowConcepts | Array of ShadowConceptResponse | Shadow Concepts |
text | String | Text as extracted from url or file |
title | String | Title as extracted from url or file |
Categorization result
Attribute | Type | Comment |
|---|---|---|
categoryConceptResults | Array of ConceptCategory | Categorized concepts |
prefLabel | String | Preferred label |
score | double | Score between 0.0-100.0 |
uri | String | Category URI |
Categorized concept
Attribute | Type | Comment |
|---|---|---|
prefLabel | String | Preferred label |
score | double | Score from 0.0 to 100.0 |
uri | String | URI |
A DocumentClassification object.
Attribute | Type | Comment |
|---|---|---|
predictedLabel | String | predictedLabel |
probabilities | Array of Prediction | Probabilities |
uri | String | URI of the classifier |
Concept from a PoolParty thesaurus project.
Attribute | Type | Comment |
|---|---|---|
altLabels | Map of PPLocale | Alternative labels |
broaderConcepts | Array of String | URIs of all direct broader concepts |
conceptSchemes | Array of ThesaurusConceptScheme | The concept schemes this concept resides in. |
corporaScore | Double | Relevance score - e.g. when extracted from a text. |
customAttributes | Array of CustomAttribute | Custom attributes |
customRelations | Array of CustomRelation | Custom relations |
customSchemeTypes | Array of CustomSchemeType | URIs of the custom types assigned to the concept |
frequencyInDocument | int | Frequency of the concept in the text |
frequencyInDocuments | int | Frequency of the concept in the text |
hiddenLabels | Map of PPLocale | Hidden labels |
id | String | Concept id |
languages | Array of PPLocale | Language of the prefLabel, altLabels and hiddenLabels of this localized view of the concept. |
matchingLabels | Array of MatchingLabel | Matching labels |
prefLabels | Map of PPLocale | Preferred label |
project | String | UUID of the containing PoolParty project |
relatedConcepts | Array of String | URIs of all related concepts |
score | double | Normalized relevance score - e.g. when extracted from a text. |
transitiveBroaderConcepts | Array of String | URIs of all transitive broader concepts |
transitiveBroaderTopConcepts | Array of String | URIs of all top concepts that this concept is connected to via a transitive broader-chain. |
uri | String | Uniform resource identifier |
wordForms | Array of String | Lemmatized word forms |
ConceptScheme from a PoolParty thesaurus project - acts as a container for concepts.
Attribute | Type | Comment |
|---|---|---|
title | String | The localized title of this concept scheme |
uri | String | Uniform resource identifier |
Custom attribute
Attribute | Type | Comment |
|---|---|---|
literal | Literal | Literal |
property | String | Property |
Custom relation
Attribute | Type | Comment |
|---|---|---|
object | String | Object |
property | String | Property |
(PoolParty) concept scheme - acts as a container for concepts
Attribute | Type | Comment |
|---|---|---|
title | String | The name of this custom scheme type |
uri | String | Uniform resource identifier |
Phrase extracted from a text that does not match any concepts
Attribute | Type | Comment |
|---|---|---|
corporaScore | Double | Corpora score |
frequencyInDocument | int | Frequency within the document where it was extracted. |
frequencyInDocuments | int | Frequency within the documents where it was extracted. |
score | Double | Relevance score |
textValue | String | The term phrase |
A geographical location extracted from a text.
Attribute | Type | Comment |
|---|---|---|
countryCode | String | ISO 3166-1 alpha-2 country code |
latitude | float | Latitude |
longitude | float | Longitude |
matchedLabel | String | The location label that was found in the text |
name | String | Common name of the location |
score | Double | Relevance score |
type | LocationType | Location type - either city or country City | Country |
uri | String | Uniform resource identifier of the location. |
Named Entity
Attribute | Type | Comment |
|---|---|---|
frequency | int | Frequency in document |
metadata | Map of String | Metadata |
method | String | Method |
positions | Array of SimpleTokenPosition | Position |
score | double | Score |
textValue | String | Matched text |
type | String | Type |
Regex match
Attribute | Type | Comment |
|---|---|---|
regexMatches | Array of String | Tokens from the input text that match the regex pattern |
regexPattern | String | The original pattern used to match |
Sentiment result
Attribute | Type | Comment |
|---|---|---|
negativeTerms | Array of String | List of negative terms |
positiveTerms | Array of String | List of positive terms |
score | float | Score |
sentiment | String | Sentiment |
Shadow concept
Attribute | Type | Comment |
|---|---|---|
altLabels | Map of PPLocale | Alternative labels |
broaderConcepts | Array of String | URIs of all direct broader concepts |
conceptSchemes | Array of ThesaurusConceptScheme | The concept schemes this concept resides |
corporaScore | Double | Relevance score - e.g. when extracted from a text |
customAttributes | Array of CustomAttribute | Custom attributes |
customRelations | Array of CustomRelation | Custom relations |
customSchemeTypes | Array of CustomSchemeType | URIs of the custom types assigned to the concept |
hiddenLabels | Map of PPLocale | Hidden labels |
id | String | Concept id |
languages | Array of PPLocale | Language of the prefLabel, altLabels and hiddenLabels of this localized view of the concept |
prefLabels | Map of PPLocale | Preferred label |
project | String | UUID of the containing PoolParty project |
relatedConcepts | Array of String | URIs of all related concepts |
score | double | Normalized relevance score - e.g. when extracted from a text |
shadowConceptTerms | Array of ShadowTerm | Extracted terms that contribute to calculation of the shadow concept |
transitiveBroaderConcepts | Array of String | URIs of all transitive broader concepts |
transitiveBroaderTopConcepts | Array of String | URIs of all top concepts that this concept is connected to via a transitive broader-chain |
uri | String | Uniform resource identifier |
Phrase extracted from a text that does not match any concepts
Attribute | Type | Comment |
|---|---|---|
score | double | Relevance score |
textValue | String | The term phrase |
Web Service Method: Extract from URL
Web Service Method: Extract from URL
Description |
|---|
[url] Extracts and returns meaningful metadata like concepts and terms from a given URL. |
URL: /extractor/api/extract
Supported Methods |
|---|
POST |
GET |
application/x-www-form-urlencoded
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptMinimumScore | Double | false | Minimum required score of concepts, default = 0 |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document |
extraConceptLanguages | Array of PPLocale | false | Additional languages used for concept extraction (en|de|es|fr|...) Also supports wildcard * for all languages |
extractorVersion | String | false | Version of PPX Extractor used |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = false |
findPersonNames | boolean | false | Deprecated (use nerParameters) - extracts person names from the given text |
language | PPLocale | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Deprecated (use nerParameters) - extracts locations from the given text |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
phraseLength | Integer | false | Phrase length, default = 4 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Set to |
regexFilename | String | false | File name for regex patterns |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
tfidfScoring | boolean | false | Use TFIDF scoring |
title | String | false | Title of the document |
url | String | true | URL to be extracted |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
Attribute | Type | Required | Comment |
|---|---|---|---|
property | String | false | Property |
value | String | false | Value |
A PPLocale object
Attribute | Type | Comment |
|---|---|---|
ALL_LANGUAGES | PPLocale | |
DUTCH | PPLocale | |
ENGLISH | PPLocale | |
FRENCH | PPLocale | |
GERMAN | PPLocale | |
RUSSIAN | PPLocale | |
SPANISH | PPLocale | |
VALID | PPLocale | |
country | String | |
language | String | |
languageTag | String |
Named Entity Recognition configuration
Attribute | Type | Required | Comment |
|---|---|---|---|
classUri | String | false | Class URI given to identified Named Entities |
method | Method | false | Method used for Named Entity Extraction. (default: MAXIMUM_ENTROPY) RULE_BASED | MAXIMUM_ENTROPY |
type | String | false | Type of Named Entity Model. Pre-defined models for MAXIMUM_ENTROPY: person, organization, location |
|
curl --location 'https://docu.semantic-web.at/extractor/api/extract' \
--header 'Authorization: Basic e3t1c2VybmFtZX19Ont7cGFzc3dvcmR9fQ==' \
--header 'Cookie: JSESSIONID=92B9D4DDDE6465C32A1F7B37B666D4B3' \
--form 'projectID="{{project_id}}"' \
--form 'url="https://en.wikipedia.org/wiki/Artificial_intelligence"' \
--form 'language="en"' \
--form 'showMatchingDetails="true"' \
--form 'displayText="true"'Content-Type: application/json
Results of a text extraction request. Properties with no entries are not present
Attribute | Type | Comment |
|---|---|---|
categories | Array of Category | Categories of the document |
classificationResults | Array of DocumentClassification | Document classification results |
concepts | Array of ThesaurusConcept | Matched concepts |
detectedLanguage | PPLocale | Detected Language of the document |
extractedTerms | Array of ExtractedTerm | Extracted freeTerms |
locations | Array of Location | Matched locations |
namedEntities | Array of NamedEntityResponse | Named Entities |
personNames | Array of String | Deprecated |
regexMatches | Array of RegexMatches | Regex token matches |
sentiments | Array of Sentiment | Matched sentiments |
shadowConcepts | Array of ShadowConceptResponse | Shadow Concepts |
text | String | Text as extracted from url or file |
title | String | Title as extracted from url or file |
Categorization result
Attribute | Type | Comment |
|---|---|---|
categoryConceptResults | Array of ConceptCategory | Categorized concepts |
prefLabel | String | Preferred label |
score | double | Score between 0.0-100.0 |
uri | String | Category URI |
Categorized concept
Attribute | Type | Comment |
|---|---|---|
prefLabel | String | Preferred label |
score | double | Score from 0.0 to 100.0 |
uri | String | URI |
A DocumentClassification object.
Attribute | Type | Comment |
|---|---|---|
predictedLabel | String | predictedLabel |
probabilities | Array of Double | Probabilities |
uri | String | URI of the classifier |
Concept from a PoolParty thesaurus project
Attribute | Type | Comment |
|---|---|---|
altLabels | Map of PPLocale | Alternative labels |
broaderConcepts | Array of String | URIs of all direct broader concepts |
conceptSchemes | Array of ThesaurusConceptScheme | The concept schemes this concept resides |
corporaScore | double | Relevance score - e.g. when extracted from a text. |
customAttributes | Array of CustomAttribute | Custom attributes |
customRelations | Array of CustomRelation | Custom relations |
customSchemeTypes | Array of CustomSchemeType | URIs of the custom types assigned to the concept |
frequencyInDocument | int | Frequency of the concept in the text |
frequencyInDocuments | int | Frequency of the concept in the text |
hiddenLabels | Map of PPLocale | Hidden labels |
id | String | Concept id |
languages | Array of PPLocale | Language of the prefLabel, altLabels and hiddenLabels of this localized view of the concept. |
matchingLabels | Array of MatchingLabel | Matching labels |
prefLabels | Map of PPLocale | Preferred label |
project | String | UUID of the containing PoolParty project. |
relatedConcepts | Array of String | URIs of all related concepts |
score | double | Normalized relevance score - e.g. when extracted from a text. |
transitiveBroaderConcepts | Array of String | URIs of all transitive broader concepts |
transitiveBroaderTopConcepts | Array of String | URIs of all top concepts that this concept is connected to via a transitive broader-chain. |
uri | String | Uniform resource identifier |
wordForms | Array of String | Lemmatized word forms |
ConceptScheme from a PoolParty thesaurus project - acts as a container for concepts
Attribute | Type | Comment |
|---|---|---|
title | String | The localized title of this concept scheme |
uri | String | Uniform resource identifier |
Custom attribute
Attribute | Type | Comment |
|---|---|---|
literal | Literal | Literal |
property | String | Property |
Custom Relation
Attribute | Type | Comment |
|---|---|---|
object | String | Object |
property | String | Property |
(PoolParty) concept scheme - acts as a container for concepts
Attribute | Type | Comment |
|---|---|---|
title | String | The name of this custom scheme type |
uri | String | Uniform resource identifier |
Phrase extracted from a text that does not match any concepts
Attribute | Type | Comment |
|---|---|---|
corporaScore | Double | Corpora score |
frequencyInDocument | int | Frequency within the document where it was extracted |
frequencyInDocuments | int | Frequency within the documents where it was extracted |
score | Double | Relevance score |
textValue | String | The term phrase |
A geographical location extracted from a text.
Attribute | Type | Comment |
|---|---|---|
countryCode | String | ISO 3166-1 alpha-2 country code |
latitude | float | Latitude |
longitude | float | Longitude |
matchedLabel | String | The location label that was found in the text. |
name | String | Common name of the location. |
score | Double | Relevance score |
type | LocationType | Location type - either city or country City | Country |
uri | String | Uniform resource identifier of the location |
Named Entity
Attribute | Type | Comment |
|---|---|---|
frequency | int | Frequency in document |
metadata | Map of String | Metadata |
method | String | Method |
positions | Array of SimpleTokenPosition | Position |
score | double | Score |
textValue | String | Matched text |
type | String | Type |
Regex match
Attribute | Type | Comment |
|---|---|---|
regexMatches | Array of String | Tokens from the input text that match the regex pattern |
regexPattern | String | The original pattern used to match |
Sentiment result
Attribute | Type | Comment |
|---|---|---|
negativeTerms | Array of String | List of negative terms |
positiveTerms | Array of String | List of positive terms |
score | float | Score |
sentiment | String | Sentiment |
Shadow Concept
Attribute | Type | Comment |
|---|---|---|
altLabels | Map of PPLocale | Alternative labels |
broaderConcepts | Array of String | URIs of all direct broader concepts |
conceptSchemes | Array of ThesaurusConceptScheme | The concept schemes this concept resides |
corporaScore | Double | Relevance score - e.g. when extracted from a text |
customAttributes | Array of CustomAttribute | Custom attributes |
customRelations | Array of CustomRelation | Custom relations |
customSchemeTypes | Array of CustomSchemeType | URIs of the custom types assigned to the concept |
hiddenLabels | Map of PPLocale | Hidden labels |
id | String | Concept id |
languages | Array of PPLocale | Language of the prefLabel, altLabels and hiddenLabels of this localized view of the concept |
prefLabels | Map of PPLocale | Preferred label |
project | String | UUID of the containing PoolParty project |
relatedConcepts | Array of String | URIs of all related concepts |
score | double | Normalized relevance score - e.g. when extracted from a text |
shadowConceptTerms | Array of ShadowTerm | Extracted terms that contribute to calculation of the shadow concept |
transitiveBroaderConcepts | Array of String | URIs of all transitive broader concepts |
transitiveBroaderTopConcepts | Array of String | URIs of all top concepts that this concept is connected to via a transitive broader-chain |
uri | String | Uniform resource identifier |
Phrase extracted from a text that does not match any Concepts
Attribute | Type | Comment |
|---|---|---|
score | double | Relevance score |
textValue | String | The term phrase |
Concept Extraction Service - Examples
Concept Extraction Service - Examples
These topics contain a few examples that can help you to use the API to advantage.
Free Terms Extraction Based on a Text Corpus
Free Terms Extraction Based on a Text Corpus
During the corpus analysis free terms are extracted and scored according to statistical methods (see Extracted Terms List in the corpus management section).
These scores indicate the relevance of terms in a given text corpus and can be used to improve scores of free terms in the extraction of single documents. When you use the parameter "corpusScoring" then the relevance scores the extracted terms have in the corpus are taken into account. This way terms that show higher relevance in the corpus will be ranked higher in the document. This is especially useful for short documents where the term frequencies are low and the scoring based on the document alone does not provide satisfying results.
Example text to be analysed:
A five-door version, called Sportback, was launched in November 2011, with sales starting in export markers during spring 2012. The A1 is designed to compete with the Mini (marque) Mini, and Alfa Romeo MiTo. The car is aimed mostly at young, affluent Urban area urban buyers. The A1 is produced at Audi Brussels Audi's Belgian factory in Forest, Belgium Forest, near Brussels.
Call without parameter:
http://[PoolParty Server URL]/extractor/api/extract?projectId=1DBCB738-3DDE-0001-456B-1A80824632E0&language=en&numberOfTerms=10&text=A%20five-door%20version,%20called%20Sportback,%20was%20launched%20in%20November%202011,%20with%20sales%20starting%20in%20export%20markers%20during%20spring%202012.%20The%20A1%20is%20designed%20to%20compete%20with%20the%20Mini%20(marque)%20Mini,%20and%20Alfa%20Romeo%20MiTo.%20The%20car%20is%20aimed%20mostly%20at%20young,%20affluent%20Urban%20area%20urban%20buyers.%20The%20A1%20is%20produced%20at%20Audi%20Brussels%20Audi%27s%20Belgian%20factory%20in%20Forest,%20Belgium%20Forest,%20near%20Brussels.
Results:
{
"freeTerms": [
{
"textValue": "five-door version called sportback",
"score": 100,
"frequencyInDocument": 1
},
{
"textValue": "called sportback was launched",
"score": 95,
"frequencyInDocument": 1
},
{
"textValue": "sales starting in export",
"score": 77,
"frequencyInDocument": 1
},
{
"textValue": "starting in export markers",
"score": 75,
"frequencyInDocument": 1
},
{
"textValue": "export markers during spring",
"score": 70,
"frequencyInDocument": 1
},
{
"textValue": "compete with the mini",
"score": 52,
"frequencyInDocument": 1
},
{
"textValue": "five-door",
"score": 50,
"frequencyInDocument": 1
},
{
"textValue": "five-door version",
"score": 50,
"frequencyInDocument": 1
},
{
"textValue": "five-door version called",
"score": 50,
"frequencyInDocument": 1
},
{
"textValue": "version",
"score": 49,
"frequencyInDocument": 1
}
]
}Call with corpus parameter (parameter value is the corpus ID as it is shown in corpus detail):
http://[PoolParty Server URL]/extractor/api/extract?projectId=1DBCB738-3DDE-0001-456B-1A80824632E0&language=en&numberOfTerms=10&corpusScoring=corpus:ace05665-5a18-4162-9f59-d8ea2f4c2226&text=A%20five-door%20version,%20called%20Sportback,%20was%20launched%20in%20November%202011,%20with%20sales%20starting%20in%20export%20markers%20during%20spring%202012.%20The%20A1%20is%20designed%20to%20compete%20with%20the%20Mini%20(marque)%20Mini,%20and%20Alfa%20Romeo%20MiTo.%20The%20car%20is%20aimed%20mostly%20at%20young,%20affluent%20Urban%20area%20urban%20buyers.%20The%20A1%20is%20produced%20at%20Audi%20Brussels%20Audi%27s%20Belgian%20factory%20in%20Forest,%20Belgium%20Forest,%20near%20Brussels.
The corpus contains a few hundred documents related to the theme "cars" and now those terms related to the theme are scored higher. Results:
{
"freeTerms": [
{
"textValue": "alfa romeo",
"score": 43,
"frequencyInDocument": 1
},
{
"textValue": "version called",
"score": 32,
"frequencyInDocument": 1
},
{
"textValue": "mini marque",
"score": 27,
"frequencyInDocument": 1
},
{
"textValue": "alfa romeo mito",
"score": 27,
"frequencyInDocument": 1
},
{
"textValue": "romeo mito",
"score": 22,
"frequencyInDocument": 1
},
{
"textValue": "young affluent urban area",
"score": 22,
"frequencyInDocument": 1
},
{
"textValue": "affluent urban area urban",
"score": 21,
"frequencyInDocument": 1
},
{
"textValue": "mini",
"score": 20,
"frequencyInDocument": 2
},
{
"textValue": "urban area urban buyers",
"score": 20,
"frequencyInDocument": 1
},
{
"textValue": "launched in november",
"score": 19,
"frequencyInDocument": 1
}
]
}Special Extractor Functionalities
Special Extractor Functionalities
The PPX extractor can match user defined regular expressions in text. The regular expressions are defined in a file on the PoolParty server (see PoolParty Directory Structure Linux). The regular expressions are defied using the Java syntax (see http://docs.oracle.com/javase/9/docs/api/java/util/regex/Pattern.html).
Regular expression:
\b(B|BA|BL|BM|BN|BR|BZ|DL|DO|E|EF|EU|FB|FE|FF|FK|FR|G|GB|GD|GF|GM|GR|GS|GU|HA|HB|HE|HL|HO|I|IL|IM|JE|JO|JU|K|KB|KF|KI|KL|KO|KR|KS|KU|L|LA|LB|LE|LF|LI|LL|LN|LZ|MA|MD|ME|MI|MU|MZ|ND|NK|OP|OW|P|PE|PL|RA|RE|RI|RO|S|SB|SD|SE|SL|SP|SR|SV|SW|SZ|TA|TU|UU|VB|VI|VK|VL|VO|W|WB|WE|WL|WN|WO|WT|WU|WY|WZ|ZE|ZT)[- -]?\d[\dA-Z]{2,4}[A-Z]\bThis regular expression matches Austrian license plates.
Input text:
KI-42KB for a Kfz characteristic of the district Kirchdorf to the Krems
permissible combinations are: KI-1AAA, KI-10AA, KI-100A; KI-10ZZZ, KI-100ZZ, KI-1000Z.
Permissible combinationsfor Vienna are: W-10AAA, W-100AA, W-1000A, W-10000A; W-10ZZZZ; W-100ZZZ; W-1000ZZ, W-10000Z.
Some authorities (particularly in the larger cities) reserve certain letter combinations for vehicles with special use in the context of this system:
BB federal bus (public Kraftfahrlinien) (W-4333BB) and Federal Railroads (those parts, which do not notice sovereign tasks)
Funeral (W-1256BE)
EW power station (W-8322EW)
L.G. fire-brigade (AM-23FW)
GE municipality-own vehicles (SW-10GE)
GT commercial goods transport (W-1234GT)
GW gas works (W-4136GW)
KT commercial small transportation (W-3614KT)
LO urban line motorbuses (W-3982LO)
mA vehicle of municipal authorities (W-2412MA)
MW rented car (P-673MW)
RD emergency service (outpatient clinic) (ME-100RD)
RK red cross (WN-19RK)
TX Taxi (SW-45TX)
VB vehicle of the urban transporting enterprises (W-7261VB)
API call:
http://test.semantic-web.at/extractor/api/extract?projectId=1DAAFECD-CF6D-0001-C2FE-3F8F14A111E5&language=de&text=KI-42KB%20for%20a%20Kfz%20characteristic%20of%20the%20district%20Kirchdorf%20to%20the%20Krems%20permissible%20combinations%20are:%20KI-1AAA,%20KI-10AA,%20KI-100A;%20KI-10ZZZ,%20KI-100ZZ,%20KI-1000Z.%20Permissible%20combinationsfor%20Vienna%20are:%20W-10AAA,%20W-100AA,%20W-1000A,%20W-10000A;%20W-10ZZZZ;%20W-100ZZZ;%20W-1000ZZ,%20W-10000Z.%20Some%20authorities%20%28particularly%20in%20the%20larger%20cities%29%20reserve%20certain%20letter%20combinations%20for%20vehicles%20with%20special%20use%20in%20the%20context%20of%20this%20system:%20BB%20federal%20bus%20%28public%20Kraftfahrlinien%29%20%28W-4333BB%29%20and%20Federal%20Railroads%20%28those%20parts,%20which%20do%20not%20notice%20sovereign%20tasks%29%20Funeral%20%28W-1256BE%29%20EW%20power%20station%20%28W-8322EW%29%20L.G.%20fire-brigade%20%28AM-23FW%29%20GE%20municipality-own%20vehicles%20%28SW-10GE%29%20GT%20commercial%20goods%20transport%20%28W-1234GT%29%20GW%20gas%20works%20%28W-4136GW%29%20KT%20commercial%20small%20transportation%20%28W-3614KT%29%20LO%20urban%20line%20motorbuses%20%28W-3982LO%29%20mA%20vehicle%20of%20municipal%20authorities%20%28W-2412MA%29%20MW%20rented%20car%20%28P-673MW%29%20RD%20emergency%20service%20%28outpatient%20clinic%29%20%28ME-100RD%29%20RK%20red%20cross%20%28WN-19RK%29%20TX%20Taxi%20%28SW-45TX%29%20VB%20vehicle%20of%20the%20urban%20transporting%20enterprises%20%28W-7261VB%29®exFilename=KFZ.txt&numberOfTerms=0
Result:
{
"regexMatches": [
{
"regexMatches": [
"KI-42KB",
"KI-1AAA",
"KI-10AA",
"KI-100A",
"KI-10ZZZ",
"KI-100ZZ",
"KI-1000Z",
"W-10AAA",
"W-100AA",
"W-1000A",
"W-10000A",
"W-10ZZZZ",
"W-100ZZZ",
"W-1000ZZ",
"W-10000Z",
"W-4333BB",
"W-1256BE",
"W-8322EW",
"SW-10GE",
"W-1234GT",
"W-4136GW",
"W-3614KT",
"W-3982LO",
"W-2412MA",
"P-673MW",
"ME-100RD",
"WN-19RK",
"SW-45TX",
"W-7261VB"
],
"regexPattern": "\\b(B|BA|BL|BM|BN|BR|BZ|DL|DO|E|EF|EU|FB|FE|FF|FK|FR|G|GB|GD|GF|GM|GR|GS|GU|HA|HB|HE|HL|HO|I|IL|IM|JE|JO|JU|K|KB|KF|KI|KL|KO|KR|KS|KU|L|LA|LB|LE|LF|LI|LL|LN|LZ|MA|MD|ME|MI|MU|MZ|ND|NK|OP|OW|P|PE|PL|RA|RE|RI|RO|S|SB|SD|SE|SL|SP|SR|SV|SW|SZ|TA|TU|UU|VB|VI|VK|VL|VO|W|WB|WE|WL|WN|WO|WT|WU|WY|WZ|ZE|ZT)[- -]?\\d[\\dA-Z]{2,4}[A-Z]\\b"
}
]
}This functionality extracts person names from the input text.
Input text:
Brigitte Helm is one of a unique group of iconic actresses; like Greta Garbo, Marlene Dietrich, and Louise Brooks, her face and image are recognized across generations, and in most corners of the world.
API call:
http://test.semantic-web.at/extractor/api/extract?projectId=1DAAFB0B-F69F-0001-55C2-62A0481C1075&language=en&numberOfTerms=0&numberOfConcepts=0&findPersonNames=true&text=Brigitte%20Helm%20is%20one%20of%20a%20unique%20group%20of%20iconic%20actresses;%20like%20Greta%20Garbo,%20Marlene%20Dietrich,%20and%20Louise%20Brooks,%20her%20face%20and%20image%20are%20recognized%20across%20generations,%20and%20in%20most%20corners%20of%20the%20world.
Result:
{
"personNames": [
"Louise Brooks",
"Greta Garbo",
"Marlene Dietrich",
"Brigitte Helm"
]
}The location extraction functionality lets you find mayor geographical locations in the input text.
API call
http://test.semantic-web.at/extractor/api/extract?projectId=1DAB0E22-3005-0001-6A68-3EB01EB220C0&language=en&text=Germany&locationExtraction=true
Result:
{
"locations": [
{
"latitude": 51.5,
"longitude": 10.5,
"uri": "http://sws.geonames.org/2921044/",
"score": 0,
"matchedLabel": "Germany",
"countryCode": "http://reegle.info/countries/DE",
"name": "Federal Republic of Germany",
"type": "Country"
}
],
}Thesaurus Based Disambiguation of Annotated Concepts
Thesaurus Based Disambiguation of Annotated Concepts
One frequently observed phenomenon in controlled vocabularies like thesauri are ambiguous terms, that is, when different concepts share the same label. This leads to wrong annotations in the text extraction process.
The PoolParty Extractor can distinguish such occurrences based on the thesaurus structure and the local context of the ambiguous concepts.
The following example explains the applied method:
In the thesaurus there are two concepts, 'Data mart' and 'Data mining', and both share the alternative label 'DM':
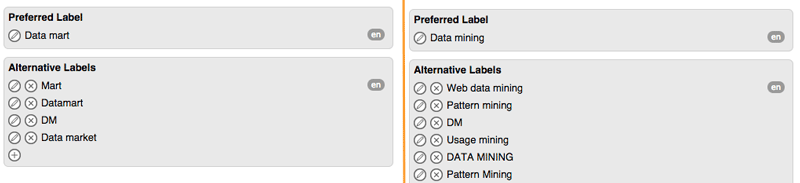 |
The method takes into account all the other concepts that are found in the surrounding of the ambiguous label in a given text and evaluates how close they are in the thesaurus.
For example, 'Data mart' has a related concept 'OLAP cube', whereas 'Data mining' is related to the concept 'SEMMA' in the thesaurus.
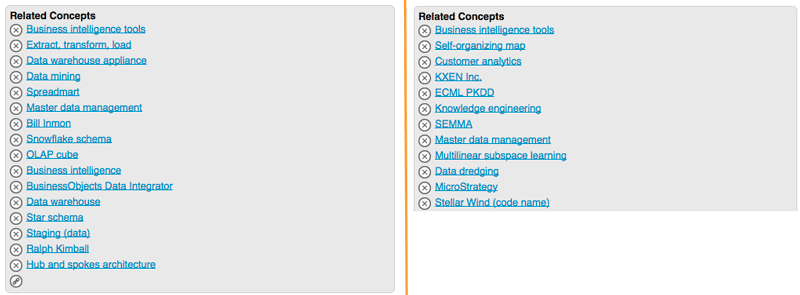 |
If one of those concepts occurs near the term 'DM' in the text, then the system is able to decide how it should be annotated, that is, if it should return 'Data mining' or 'Data mart'. This way, the annotation quality of PoolParty's text mining feature is greatly enhanced.
You can define which relationships in the thesaurus should be considered to calculate distances among the concepts.
Click CORPORA in the main menu.
Select Disambiguation Settings.
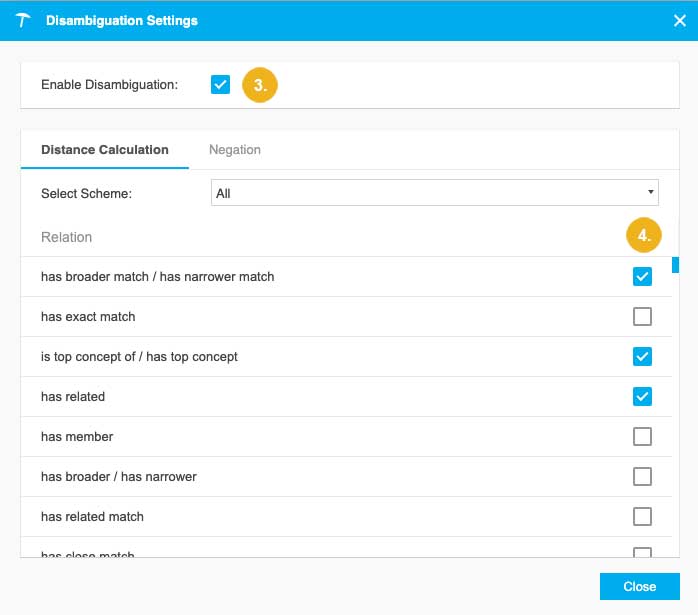
The Disambiguation Settings dialogue opens.
Select the Enable Disambiguation checkbox.
Enable the relevant relation types. The most common relation types to consider are:
'has broader / has narrower' (this is how concepts are related hierarchically),
'is top concept in scheme / has top concept' (this is how concepts are related to concept schemes),
'has related' (to related concepts in a non-hierarchical manner).
Yet other SKOS and custom properties can be included. For more information on custom properties, see Create Custom Relations.
Refresh the extraction model for the changes to take effect. For more information, see Create an Extraction Model.
Now this text can be annotated: 'An OLAP cube is a specialization around a DM.'
The API call without disambiguation parameter looks as follows:
http://localhost/extractor/api/extract?projectId=1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0&language=en&numberOfTerms=0&text=An%20OLAP%20cube%20is%20a%20specialization%20around%20a%20DM.
The result of this call see here.
In total 3 concepts that all have an alternative label 'DM' are returned:
{
"concepts": [
{
"language": "en",
"id": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0:http://dbpedia.org/resource/OLAP_cube@en",
"prefLabel": "OLAP cube",
"score": 100,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Business intelligence",
"uri": "http://dbpedia.org/resource/Category:Business_intelligence"
}
],
"altLabels": [
"Olap cube",
"Cube (disambiguation)"
],
"project": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0",
"uri": "http://dbpedia.org/resource/OLAP_cube"
},
{
"language": "en",
"id": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0:http://dbpedia.org/resource/Dimensional_modeling@en",
"prefLabel": "Dimensional modeling",
"score": 14,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Business intelligence",
"uri": "http://dbpedia.org/resource/Category:Business_intelligence"
}
],
"altLabels": [
"DM"
],
"project": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0",
"uri": "http://dbpedia.org/resource/Dimensional_modeling"
},
{
"language": "en",
"id": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0:http://dbpedia.org/resource/Data_mart@en",
"prefLabel": "Data mart",
"score": 14,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Business intelligence",
"uri": "http://dbpedia.org/resource/Category:Business_intelligence"
}
],
"altLabels": [
"DM",
"Datamart",
"Data market",
"Mart"
],
"project": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0",
"uri": "http://dbpedia.org/resource/Data_mart"
},
{
"language": "en",
"id": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0:http://dbpedia.org/resource/Data_mining@en",
"prefLabel": "Data mining",
"score": 14,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Data mining",
"uri": "http://dbpedia.org/resource/Category:Data_mining"
}
],
"altLabels": [
"Knowledge Discovery in Databases",
"Subject-based data mining",
"Data miner",
"Information-mining",
"Predictive software",
"Pattern mining",
"Information mining",
"Knowledge discovering in databases",
"Data-mining",
"Artificial Intelligence in Data Mining",
"Predictive Analytics Software",
"DATA MINING",
"Web data mining",
"Knowledge discovery in databases",
"DM",
"Datamining",
"Datamine",
"Visual Data Mining",
"Data Mining",
"Usage mining",
"Mining (disambiguation)",
"KDD",
"Knowledge mining",
"Pattern Mining"
],
"project": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0",
"uri": "http://dbpedia.org/resource/Data_mining"
}
]
}The same call but with the parameter 'disambiguate=true':
http://localhost/extractor/api/extract?projectId=1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0&language=en&numberOfTerms=0&disambiguate=true&text=An%20OLAP%20cube%20is%20a%20specialization%20around%20a%20DM.
Now only the correct concept is returned:
{
"concepts": [
{
"language": "en",
"id": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0:http://dbpedia.org/resource/OLAP_cube@en",
"prefLabel": "OLAP cube",
"score": 100,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Business intelligence",
"uri": "http://dbpedia.org/resource/Category:Business_intelligence"
}
],
"altLabels": [
"Olap cube",
"Cube (disambiguation)"
],
"project": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0",
"uri": "http://dbpedia.org/resource/OLAP_cube"
},
{
"language": "en",
"id": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0:http://dbpedia.org/resource/Data_mart@en",
"prefLabel": "Data mart",
"score": 14,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Business intelligence",
"uri": "http://dbpedia.org/resource/Category:Business_intelligence"
}
],
"altLabels": [
"DM",
"Datamart",
"Data market",
"Mart"
],
"project": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0",
"uri": "http://dbpedia.org/resource/Data_mart"
}
]
}Another test with the text 'SEMMA' mainly focuses on the modeling tasks of DM projects, leaving the business aspects out.
It returns only 'Data mining' for the ambiguous label 'DM'.
{
"concepts": [
{
"language": "en",
"id": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0:http://dbpedia.org/resource/SEMMA@en",
"prefLabel": "SEMMA",
"score": 100,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Data mining",
"uri": "http://dbpedia.org/resource/Category:Data_mining"
},
{
"title": "Business intelligence",
"uri": "http://dbpedia.org/resource/Category:Business_intelligence"
}
],
"project": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0",
"uri": "http://dbpedia.org/resource/SEMMA"
},
{
"language": "en",
"id": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0:http://dbpedia.org/resource/Data_mining@en",
"prefLabel": "Data mining",
"score": 36,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Data mining",
"uri": "http://dbpedia.org/resource/Category:Data_mining"
}
],
"altLabels": [
"Knowledge Discovery in Databases",
"Subject-based data mining",
"Data miner",
"Information-mining",
"Predictive software",
"Pattern mining",
"Information mining",
"Knowledge discovering in databases",
"Data-mining",
"Artificial Intelligence in Data Mining",
"Predictive Analytics Software",
"DATA MINING",
"Web data mining",
"Knowledge discovery in databases",
"DM",
"Datamining",
"Datamine",
"Visual Data Mining",
"Data Mining",
"Usage mining",
"Mining (disambiguation)",
"KDD",
"Knowledge mining",
"Pattern Mining"
],
"project": "1DBCCDFA-41C8-0001-BC24-BA4E1BF03AE0",
"uri": "http://dbpedia.org/resource/Data_mining"
}
]
}There is also the possibility to explicitly state that IF a certain concept appears THEN another related ambiguous concept will never be considered for disambiguation in that context.
To illustrate this principle lets assume the following thesaurus:
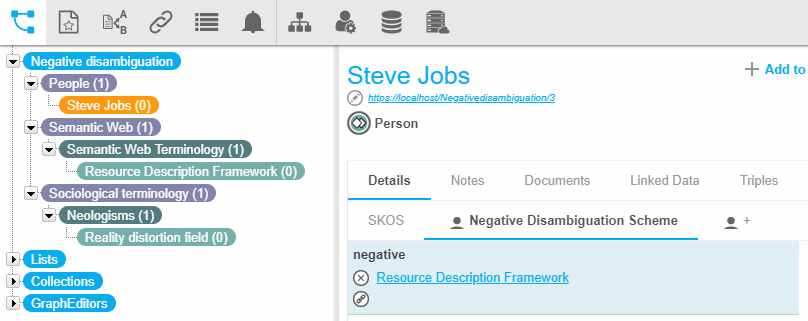 |
There are two concepts, 'Resource Description Framework' and 'Reality distortion field' that share the same label 'RDF':
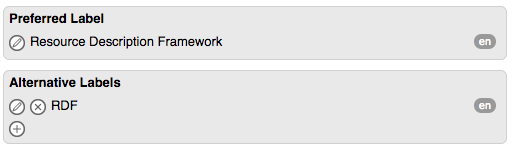 |
We presuppose now that if 'Steve Jobs' occurs in the text, then we are sure that 'RDF' does not mean 'Resource Description Framework'.
To express this we define a custom relation in a custom scheme to link 'Steve Jobs' to 'Resource Description Framework'. For more information on custom relations, see Create Custom Relations.
In this example we defined a relation 'negative' in the custom schema 'Disambiguation' (you can use any relation you define).
Then you select the relationship in the Disambiguation Settings dialogue in the Negation tab and refresh the extraction model.
Now a text like this can be annotated:
'The RDF was said by Andy Hertzfeld to be Steve Jobs' ability to convince himself and others to believe almost anything with a mix of charm, charisma, bravado, hyperbole, marketing, appeasement and persistence.'
http://localhost/extractor/api/extract?projectId=1DCDEF6F-680D-0001-9AB3-FB1BF82067A0&language=en&numberOfTerms=0&text=%22The%20RDF%20was%20said%20by%20Andy%20Hertzfeld%20to%20be%20Steve%20Jobs%27%20ability%20to%20convince%20himself%20and%20others%20to%20believe%20almost%20anything%20with%20a%20mix%20of%20charm,%20charisma,%20bravado,%20hyperbole,%20marketing,%20appeasement%20and%20persistence.%22
In the result both concepts are returned:
{
"concepts": [
{
"language": "en",
"id": "1DCDEF6F-680D-0001-9AB3-FB1BF82067A0:http://localhost/Negativedisambiguation/Resource_Description_Framework@en",
"prefLabel": "Resource Description Framework",
"score": 100,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Semantic Web",
"uri": "http://localhost/Negativedisambiguation/Semantic_Web"
}
],
"altLabels": [
"RDF"
],
"project": "1DCDEF6F-680D-0001-9AB3-FB1BF82067A0",
"uri": "http://localhost/Negativedisambiguation/Resource_Description_Framework"
},
{
"language": "en",
"id": "1DCDEF6F-680D-0001-9AB3-FB1BF82067A0:http://localhost/Negativedisambiguation/Reality_distortion_field@en",
"prefLabel": "Reality distortion field",
"score": 100,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Sociological terminology",
"uri": "http://localhost/Negativedisambiguation/Sociological_terminology"
}
],
"altLabels": [
"RDF"
],
"project": "1DCDEF6F-680D-0001-9AB3-FB1BF82067A0",
"uri": "http://localhost/Negativedisambiguation/Reality_distortion_field"
},
{
"language": "en",
"id": "1DCDEF6F-680D-0001-9AB3-FB1BF82067A0:http://localhost/Negativedisambiguation/Steve_Jobs@en",
"prefLabel": "Steve Jobs",
"score": 66,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "People",
"uri": "http://localhost/Negativedisambiguation/People"
}
],
"project": "1DCDEF6F-680D-0001-9AB3-FB1BF82067A0",
"uri": "http://localhost/Negativedisambiguation/Steve_Jobs"
}
]
}http://localhost/extractor/api/extract?projectId=1DCDEF6F-680D-0001-9AB3-FB1BF82067A0&language=en&numberOfTerms=0&disambiguate=true&text=%22The%20RDF%20was%20said%20by%20Andy%20Hertzfeld%20to%20be%20Steve%20Jobs%27%20ability%20to%20convince%20himself%20and%20others%20to%20believe%20almost%20anything%20with%20a%20mix%20of%20charm,%20charisma,%20bravado,%20hyperbole,%20marketing,%20appeasement%20and%20persistence.%22
Now only the correct concept is returned:
{
"concepts": [
{
"language": "en",
"id": "1DCDEF6F-680D-0001-9AB3-FB1BF82067A0:http://localhost/Negativedisambiguation/Reality_distortion_field@en",
"prefLabel": "Reality distortion field",
"score": 100,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "Sociological terminology",
"uri": "http://localhost/Negativedisambiguation/Sociological_terminology"
}
],
"altLabels": [
"RDF"
],
"project": "1DCDEF6F-680D-0001-9AB3-FB1BF82067A0",
"uri": "http://localhost/Negativedisambiguation/Reality_distortion_field"
},
{
"language": "en",
"id": "1DCDEF6F-680D-0001-9AB3-FB1BF82067A0:http://localhost/Negativedisambiguation/Steve_Jobs@en",
"prefLabel": "Steve Jobs",
"score": 66,
"frequencyInDocument": 1,
"conceptSchemes": [
{
"title": "People",
"uri": "http://localhost/Negativedisambiguation/People"
}
],
"project": "1DCDEF6F-680D-0001-9AB3-FB1BF82067A0",
"uri": "http://localhost/Negativedisambiguation/Steve_Jobs"
}
]
}Negative indications are just another way to think about disambiguation.
In this example linking Steve Jobs via skos:related to the 'Reality distortion field' would lead to the same results (if skos:related is included in the relations to consider). But sometimes for modeling purposes it is more elegant to use a negation.
Use API Calls to Classify Documents Using Trained Classifiers
Use API Calls to Classify Documents Using Trained Classifiers
This section provides a short guide on how to use the PoolParty API for classification of unknown documents.
When you have created Train Classifiers, added documents to them and tested them successfully, you will be ready to classify unknown documents in large numbers using our API.
The following has to be in place in order for you to be able to use the classifier:
A PoolParty Enterprise Server or Semantic Integrator license with Semantic Classifier add-on included.
An opened PoolParty thesaurus project you created.
Find the URI of the Train Classifier you want to use, by looking it up in PoolParty's interface or using the API method.
Use the Concept Extraction Services and the classifier relevant parameters, details find in the Examples section.
Create a script or code snippet to loop through such calls for classifying multiple documents.
Note
As also explained in more detail in our API documentation, you can easily use a software like Postman or any browser extension you find online to support you placing API calls.
In the Concept Extraction Service, the following parameters are available:
Path | Parameter | Comment |
|---|---|---|
GET, POST /extract | documentClassifierIds | Enable document classification by giving the document classifier IDs as input. |
The following example would classify a document according to the setup inside the respective classifiers and their categories. Terms or concepts have been excluded here:
{{url}}extractor/api/extract?documentClassifierIds=documentClassifier:365f06b1-84d5-456d-aca8-185c67b0633a&language=en&projectId={{project}}&numberOfConcepts=0&numberOfTerms=0&file={mime-file-type}This example uses more than one classifier in a row:
{{url}}extractor/api/extract?documentClassifierIds=documentClassifier:365f06b1-84d5-456d-aca8-185c67b0633a, documentClassifier:54eb65e3-c933-4a05-ae1e-f0e990a696a9&language=en&projectId={{project}}&numberOfConcepts=0&numberOfTerms=0&file={mime-file-type}