Train a Classifier
Train a Classifier
In order to use the classifiers you created, you first have to train them. This section explains how to do it.
The following has to be in place in order for you to be able to use the classifier:
A PoolParty Enterprise Server or Semantic Integrator license with Semantic Classifier add-on included.
An opened PoolParty thesaurus project you created.
PoolParty's default machine learning algorithms represent state-of-the-art calculation models. In order to use them to advantage you have to train them manually by checking classification results and tweaking settings.
We recommend to train the classifiers until the scoring for the mean f1, as well as for recall and precision are above 70 %.
How to Train a Classifier
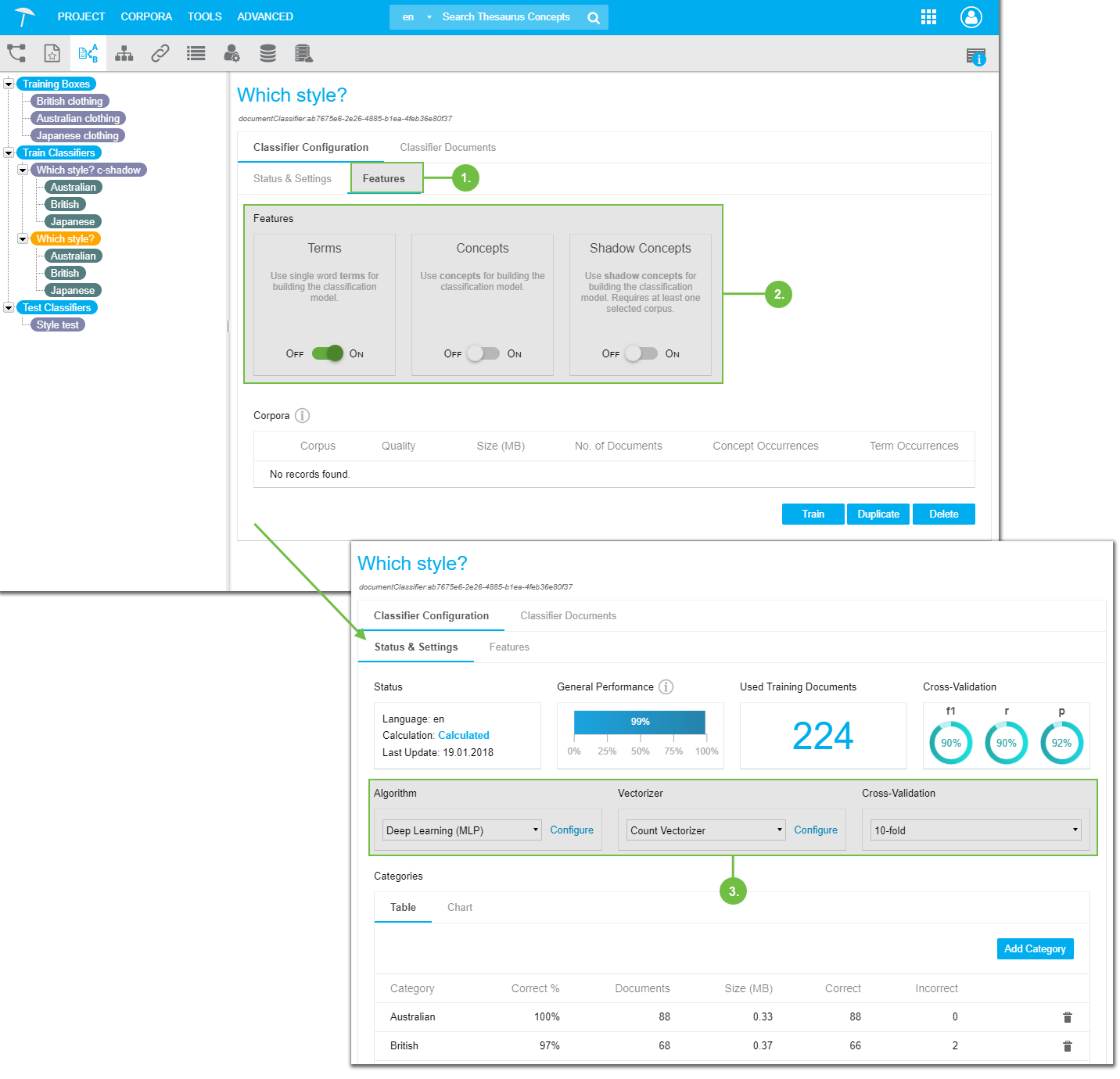
After you have created a classifier and added documents to it, choose settings in the Features tab.
You can choose which of the additional functions you want to use: include Shadow Conceptsin the calculation, the project's thesaurus as well as just single word terms.
In the Status & Settings tab select the algorithm of your choice, configure the Vectorizer and select the Cross-Validation level.
These settings, their values and their effects find explained in detail in a separate topic.
 |
For details on the training of a classifier, please refer to: Train a Classifier - Best Practices