GraphSearch on RDF Dataset
03/02/2026
After navigating to the GraphSearch Admin Dashboard, you can verify the connection to the remote database. If the connection is successful, the database will be marked as UP.
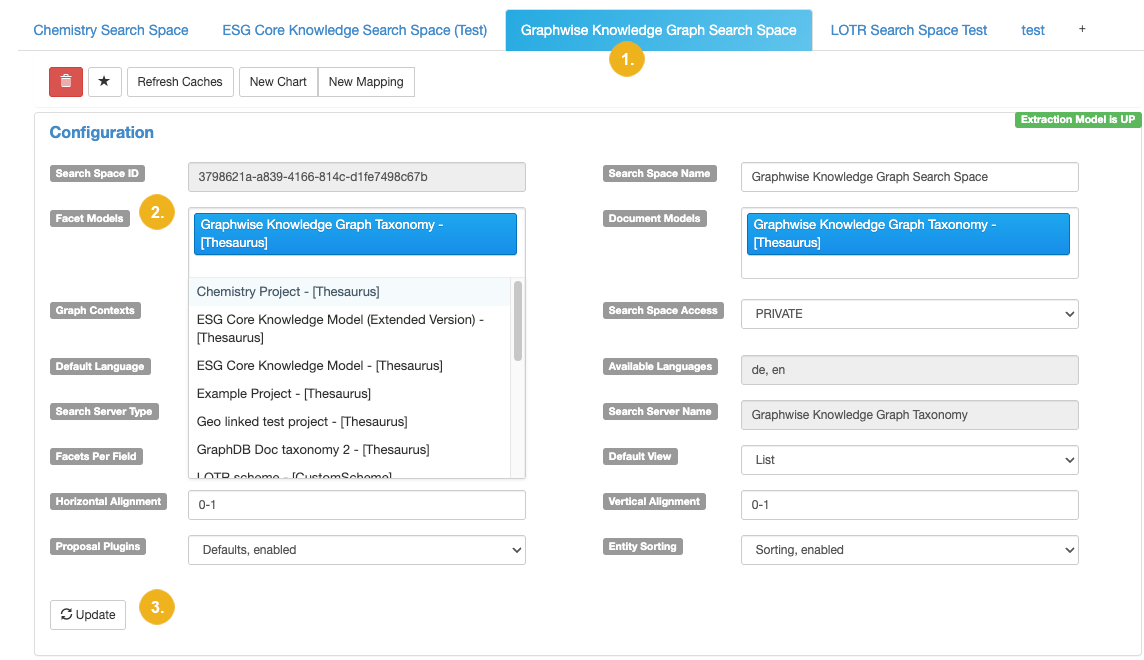
If the connection is active (indicated by green UP icon), navigate to the search space to view the configuration options. To configure facets, click Facet Models.. This opens the pulldown (2) listing all thesauri and custom schemes available for the selected search space (1). Select the facet models you want to use for the facet definition. Confirm your selection with a click on Update (3).
By default, search result of RDF resources are presented as documents in a list, with title and description fields providing some information about resources. In the Mappings section, you can specify the predicate URIs of resources representing the attribute values which can be used for titles and descriptions as well as facets, images and full text search.
If you want to use <http://schema.org/name> as title and <http://schema.org/description> as description, those two predicate URIs have to be added into the corresponding fields of the mapping list. For each field, multiple predicates can be provided as an ordered list and the first valid value will be used.
Given the description field in the image below, for example, the object value of skos:definition will be displayed as description in the search result. If it does not exist, then rdfs:comment will be used. When no object of any predicate exists in the dataset, the field will be empty.
Important
At least one predicate URI has to be specified for Description Mappings and Title Mappings.
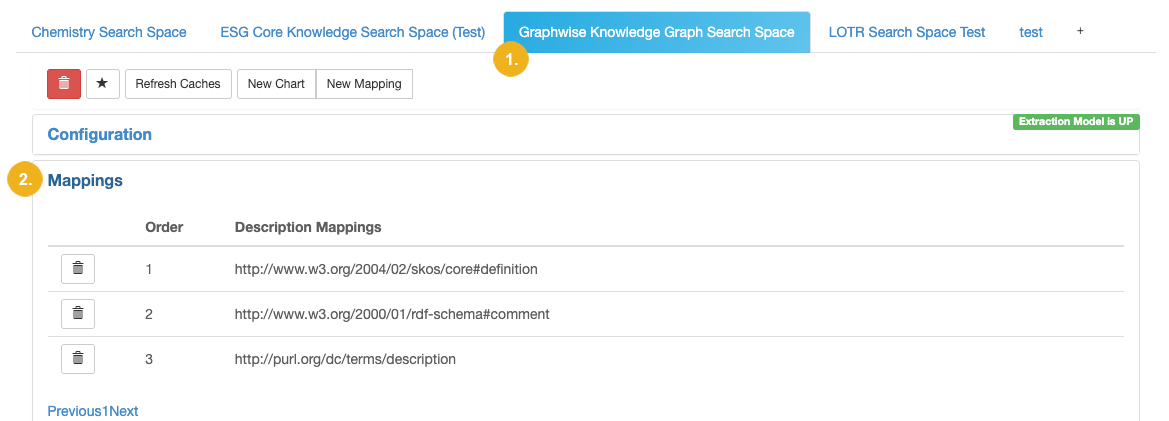
When a facet from a relation exists, it is also possible to specify a predicate URI of which a value can be used to represent the object resource in a more human readable way. Otherwise, facet members in the facet list will be displayed as URIs of object resource. This configuration is also integrated with the predicate configuration of the title field. So the predicates listed in title field actually defines two views at the same time.