An Introduction to Inference Tagging
18/09/2025
Inference Tagging is a functionality extension of the proven PoolParty Extractor to generate additional metadata about documents or data in general. It recognizes and extracts not only explicitly mentioned concepts, but also uses relevant concepts for annotation and classification that are only implicitly or indirectly mentioned.
While PoolParty Extractor basically extracts all concepts from a given input text or file that explicitly appear in a document, and at the same time are represented in the knowledge model forming the basis of the extraction service (taxonomy and ontology), inference tagging is useful when we want to go beyond extracting explicit concepts. Inference Tagging also extracts implicit concepts from documents while using specific rules. All we need is a well-structured domain knowledge model.
All existing concepts are organized and stored using taxonomies and ontologies. Documents can be easily annotated using concepts through an extraction call. At this point it is the ontology with all the classes, subclasses, and relations which indeed makes the difference, since we can use classes and relations to infer additional concepts (new triples).
Let us take a closer look at how inference tagging works and the results it delivers. The standard variant of the PoolParty Extractor used to identify concepts in the input text saying “Climate change is a driver for heatwaves and drought”, would - provided a corresponding knowledge model is in place - extract the following concepts: climate change, heatwave, drought. Provided that the knowledge model contains relations to risks associated with heatwaves (e.g. heatstroke) and drought (e.g. crop failure) then those can also be extracted and used for both annotation and classification.
Rules determining which additional concepts are to be extracted using the Inference Tagging feature can be created, tested and edited in the Workbench. Inference Tagging uses two requests - an extract and expand request. These requests can be easily created and tested using the Workbench. An expansion call is a SPARQL request. For those less familiar with SPARQL the Workbench offers an Expansion Query Builder where such queries can be easily formulated.
The Workbench is a useful tool allowing subject matter experts to define specific rules for both calls (i.e. extraction and expansion); these calls are stored together in a configuration file and can be tested at any point using the Workbench.
The Workbench offers - reflecting your license - the following functionalities:
inference tagging
recommendation service
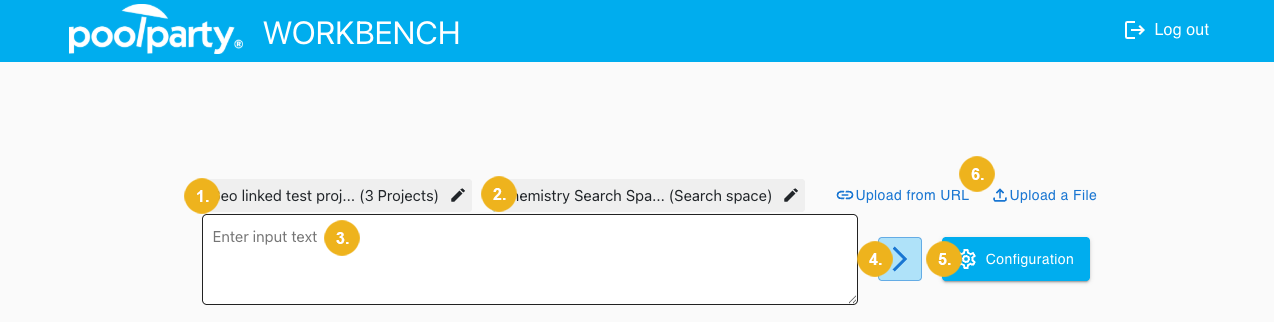
The image above shows the landing page of the Workbench.
Use the Projects tab, located to the left of the input field (1), to configure which project or projects are used. The thesauri and ontologies behind the selected projects enable the extraction of concepts from your input text, which are then expanded during the inference tagging process. It is therefore mandatory to select at least one project be able use the Inference Tagging function. The search space (2) does not have to be configured for inference tagging as it is only used for Recommendation. Then you have to enter the input that should be tagged - here you have three options available: you can enter any text in the input field (3), or you can upload content from a URL or from a file (6). Clicking on the arrow icon starts the tagging (4), whereas clicking the Configuration button (6) allows you to review all relevant settings and to modify them if required.
Click the Configuration button on the Workbench landing page to open the Settings window with several tabs allowing us to fine tune the parameters.
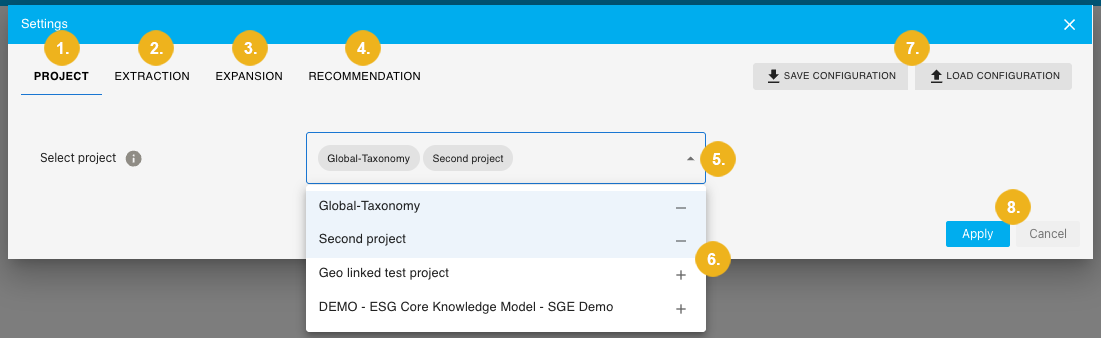
Here we see four tabs - PROJECT (1), EXTRACTION (2), EXPANSION (3), and RECOMMENDATION (4); the respective selected and active tab is indicated by an underlining blue line. Only the first three tabs are relevant for inference tagging. The fourth tab is relevant when it comes to the recommendation feature, which is explained in the Recommender User Guide.
You can save your configuration at any time using the SAVE CONFIGURATION (7) button, or load a saved one using the LOAD CONFIGURATION (7) button.
The PROJECT tab has a drop-down menu Select project (5) allowing you to select the desired project. If the settings for extraction and expansion are already correct, click Apply (8). Otherwise, continue to the EXTRACTION or EXPANSION tabs to adjust them.
Note
It is possible to select multiple projects in the Workbench. To add or remove projects, click their corresponding + and - buttons (5) in the drop-down menu of available PoolParty projects.
Keep in mind that clicking the Cancel (8) button will discard all settings made so far.
After selecting the desired project we need to continue on the EXTRACTION tab.
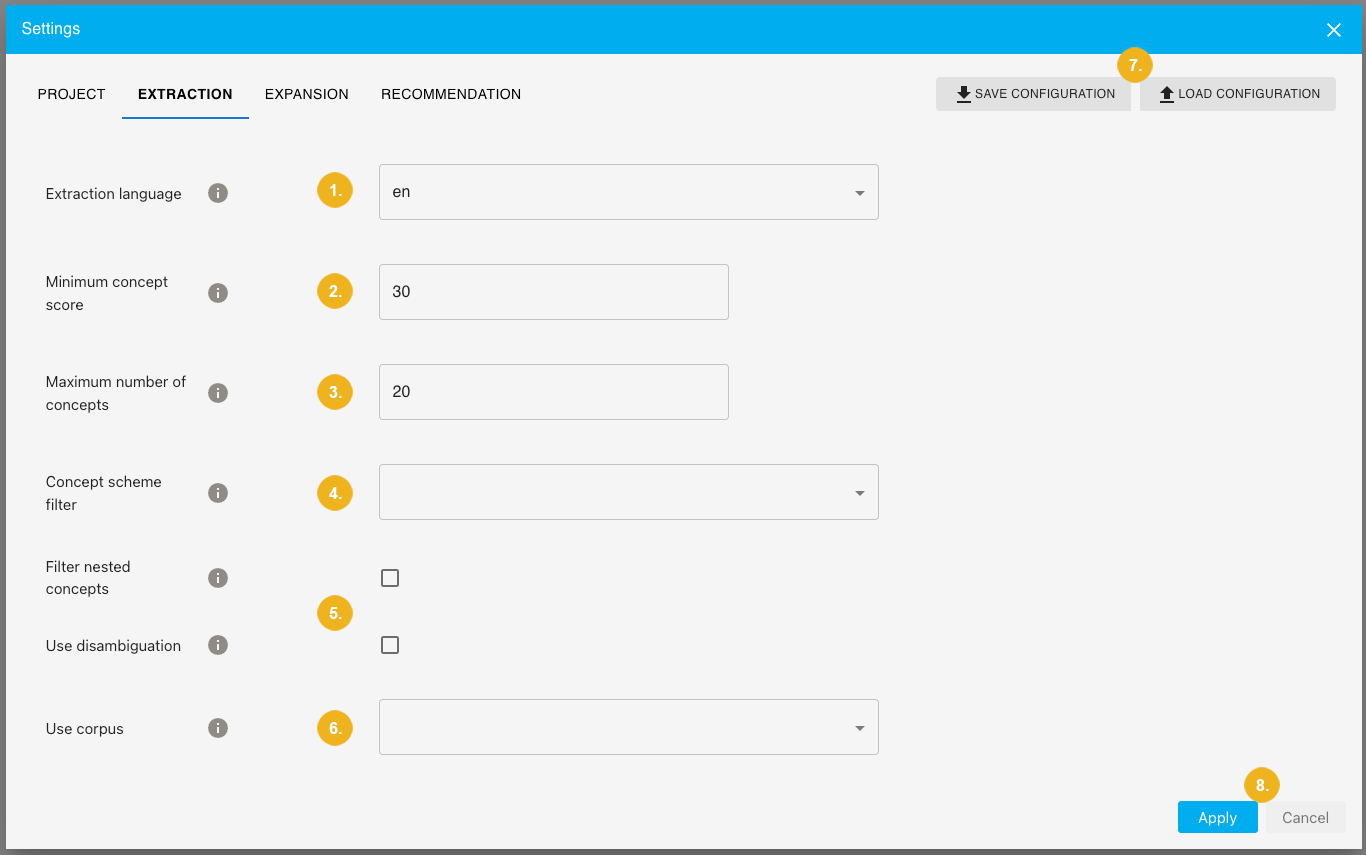
On this tab we will fine tune the extraction from our input text.
Here you can adjust the following settings:
Extraction language (1) - this is the language used for extraction and the language used in your selected project - our example shows English - en.
Minimum concept score (2) - the higher the score the fewer results you will obtain - our example shows 30 as the minimum score.
Maximum number of concepts (3) - here you can define the maximum number of concepts to be extracted, which is 20 in our example.
If you have a concept scheme defined in PoolParty for the selected project - you can use the Concept scheme filter (4) by selecting one of the available schemata in this drop-down menu.
The two checkboxes below (5) - Filter nested concepts and Use disambiguation are optional but ticking them will narrow down the number of retrieved results.
If you have a corpus defined for the selected project in PoolParty you can specify it here using the corresponding Use corpus (6) drop-down menu.
After having fine tuned the extraction parameters we can move on to the EXPANSION tab. If you only want to extract concepts from your input without expanding them, click on the Apply (8) button at this point. Keep in mind that clicking the Cancel (8) button will discard all settings made so far.
Note
Use the SAVE CONFIGURATION (7) button to save your current configuration, respectively the LOAD CONFIGURATION (7) button to load an existing one.
Our next step will be to define the expansion SPARQL query. For users less familiar with the SPARQL query language, the PoolParty feature Expansion Query Builder facilitates formulation of such queries. Experts can of course use the command line input available on the Switch to SPARQL sub-tab where they can formulate sophisticated queries going beyond the options available on the UI.
We will now guide you through the Expansion Query Builder feature facilitating the formulation of the required SPARQL query illustrated by a sample query.
In our example we will create an inference tagging scenario and then use the Workbench to configure the required settings, in particular the Expansion Query Builder, to be able to run the inference tagging feature and obtain inferred concepts.
The following assumptions are underlying our scenario:
A knowledge manager wants to find out how certain regulations within the ESG (Environment, Social and Governance) domain address concepts tagged in their documents. Such regulations may or may not be explicitly mentioned in the content, however, with the combined power of Inference Tagging and the existing knowledge model, these documents can be annotated with these hidden concepts.
This knowledge manager uses both PoolParty Taxonomy and Ontology and has the PoolParty Workbench installed providing the Expansion Query Builder feature.
Our scenario uses the following input text: "As part of our environmental management program, we are committed to ensuring that our employees receive training to raise awareness of environmental issues and our processes to reduce environmental impact. In 2021, site workers received 1,500 hours of environmental training, focusing on job-specific environmental awareness, hazardous material management, spill response, and reporting."
In our example we will use the ESG Core Knowledge Model (taxonomy & ontology) which will return the following concept Environmental Management Program. This concept has a few connections (i.e. relations) within our knowledge model, however, we are interested in the "is addressed by" relation, pointing to concepts with the class Regulation. Here, the concept Environmental Management Program points to two separate resources, namely ISO 14000 and United Nations Global Compact. These are not explicitly mentioned in the text, however, we want to annotate the content with those concepts. When we run Extraction without the Inference Tagging functionality on top, we get the following tags for the above input text: Educations, ESG Management, Employee, and Employment. However, what we want is the following: Education, ESG Management, Employee, Employment + ISO 14000, United Nations Global Compact. In order to annotate the text with these additional, implicit concepts we need to set up an Inference Tagging rule stating "If a certain concept is found within the text, then also include concepts connected via the "is addressed by" relation in the Extraction results".
Now, as we have our Inference Tagging scenario, we can make use of the Expansion Query Builder to assist us in setting up the tagging rule. To do so, we click on the PoolParty Workbench landing page on Configuration. There click on Expansion and select the Expansion Query Builder sub-tab. The image below shows the Expansion Query Builder sub-tab with all fields filled in.
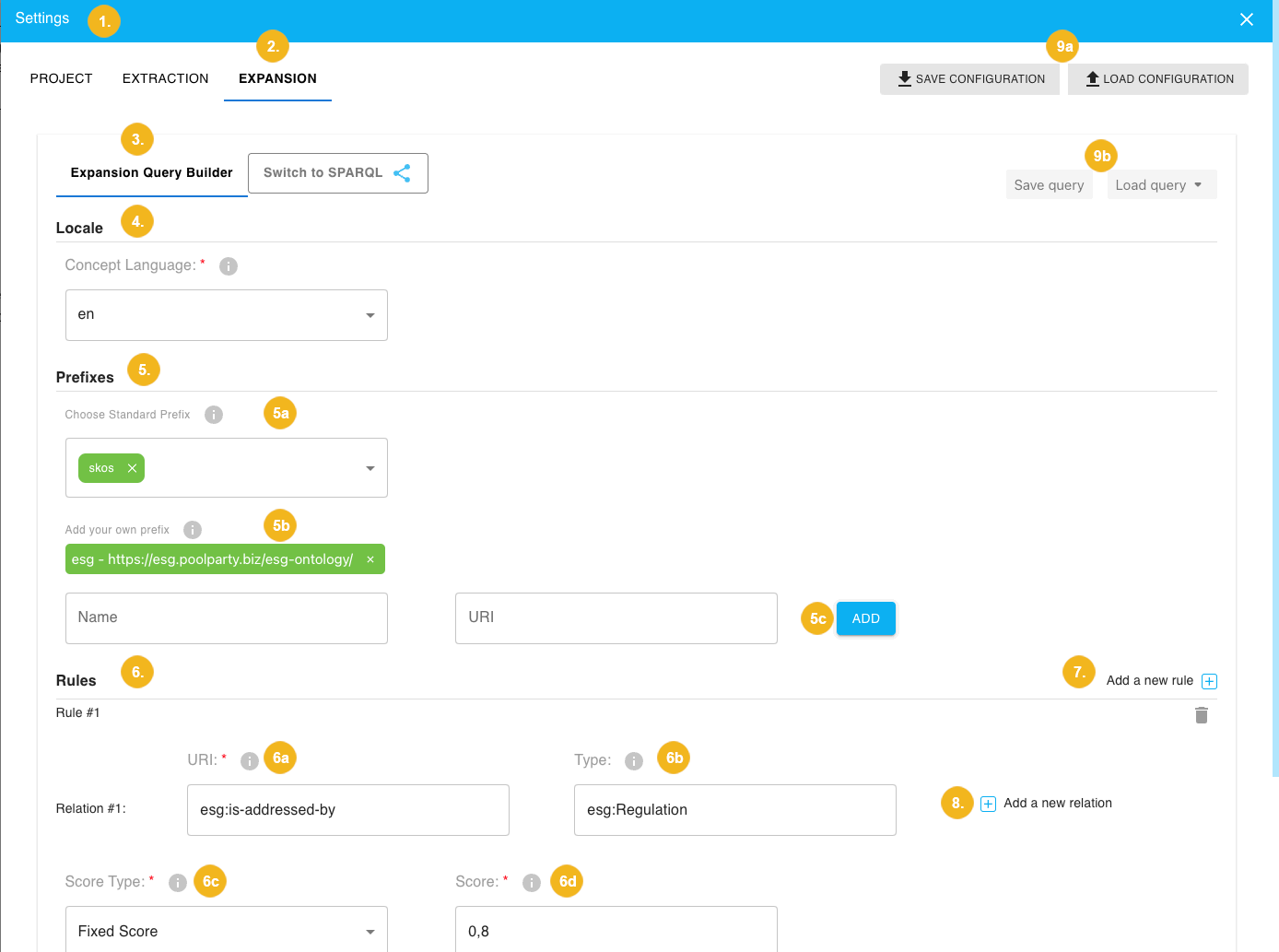
After opening the Settings (1) window we navigate to the EXPANSION (2) tab where we have two sub-tabs; Expansion Query Builder (3) and Switch to SPARQL. We will now focus on how to use the Expansion Query Builder sub-tab to formulate a SPARQL query.
Tip
The Save query and Load query (9a) buttons on the right allow you to save your query or if you already have queries stored to load one.
The first step will be to specify the language using the Locale (4) pulldown. You have to keep in mind that only those concepts will be returned for which the specified language matches your selection here. This parameter is mandatory.
Then we can specify the Prefixes (5) which can be a standard prefix using the Choose Standard Prefix (5a) pulldown. The standard prefixes include skos, rdf, dcterms, etc. We can specify one or more standard prefixes. In our example we are using skos as the selected standard prefix. We can however also add our own prefix (5b) by entering the Name and the corresponding URI and clicking the ADD (5c) button. In our example we entered esg in the Name field and https://esg.poolparty.biz/esg-ontology/ in the URI field. Specifying prefixes upfront will allow us to skip the full path (URI) every time we use a prefix when defining the rules of our inference tagging. The saved custom prefix is always shown above the two input fields Name and URI; also here we can define more than one custom prefix.
Next step is to specify the rules. Sometimes we will need multiple rules, in such case we can use the Add a new rule button (7) on the very right.
In the Rules (6) section of this tab we can specify all the required details we need for each rule. Every rule is comprised of a relation and score. A relation is then comprised of the URI (mandatory) field (6a) and Type field (6b). In our example the Relation #1 contains the relation esg:is-addressed-by. (Since we have defined our custom prefix esg in the previous step we only need to enter its name (egs) and can skip entering the complete URL.) The Type (6a) field is in our case esg:Regulation. This field works as an additional filter; here we specify that we want to receive inferred concepts linked to the extracted concepts using the esg:is-addressed-by relation HOWEVER ONLY if such concepts belong to the esg:Regulation class. If in contrast we intended to retrieve all possible concepts irrespective of their class we would enter skos:Concept in the Type (6b) field. If we want to add another relation to a rule we will use the Add a new relation (8) button to the right.
We can specify one or more rules, and for each rule one or more relations. All specified rules will be applied and are combined via OR; Each rule is however independent. At the same time the relation specified within the rule defines a path. If more than one relation is specified for a rule, then they form a path within the graph applying one after the other.
Then we need to select the Score Type (6c) and enter the Score (6d). The Score Type field is a pulldown with two options: Multiplier and Fixed Score.
In our example we will used the Fixed Score option and enter the 0.8 as the score - this means that each inferred concept will have this score. If we however used the Multiplier option and entered 0.8 in the Score field then - depending on the score of the concept extracted from our input - the inferred concept would a have a variable score equal to 0.8 times the score of the original extracted concept; e.g. if our original concept has a score of 80, then using the Multiplier option will result in the inferred concept having a score of 0.8 times 80 = 64.
Tip
You can test your SPARQL query before applying it.
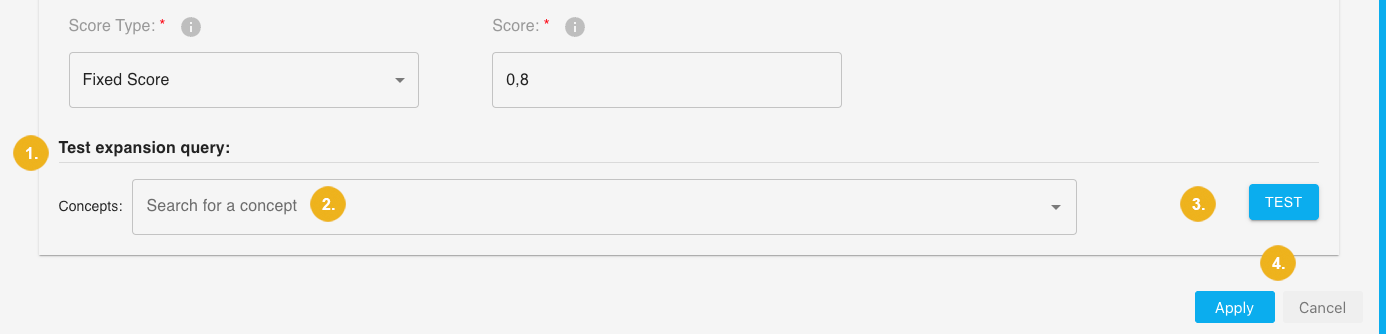
To test your SPARQL query scroll to the bottom of the window until you see the Test expansion query: (1) section. There you only need to enter a concept from the extraction in the Concepts (2) field and click on the TEST (3) button. The input field Concepts uses the auto-complete function, i.e. after having entered thirst three letters of a concept you will automatically see a list with one or more concepts matching the first leading letters. Simply select one of those shown here. You can specify more than one concept for testing your query.
Click the Apply (4) button to add your query or the Cancel (4) button if you want to discard the formulated query and any other settings you may have made on the other two tabs - PROJECT and EXTRACTION.
Tip
You can start your extraction and expansion also from the Settings window with a click on the Apply (4) button.
Clicking Apply and then the Arrow button will direct you to the results page:
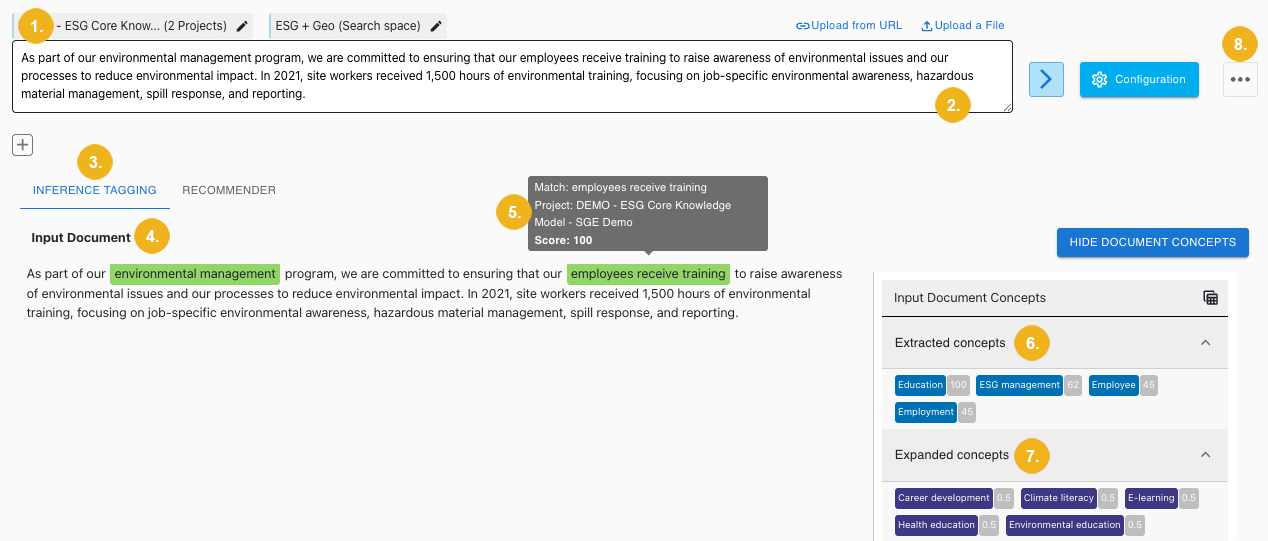
After running both an extraction and expansion query we will see both the extracted and expanded color-coded concepts returned for the input text (2) and the selected project (1). The INFERENCE TAGGING tab (3) is open by default.
Below the Input Document (4) heading you see the input text with identified concepts. You can hover over an identified concept to view more information on the concept, (5) such as the project it corresponds to and its score. To the right you see all Extracted concepts (6) and all Expanded concepts (7). Next to each concept you can see its score, highlighted with a grey background.
If you want to save the configuration or individual calls, click on the three dots (8) in the upper right section of the screen to open a context menu. This context menu allows you to import and export configurations.
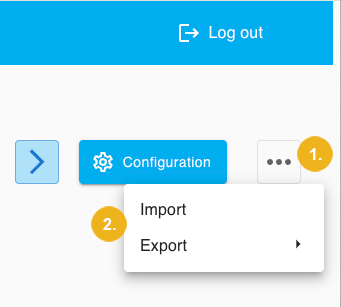
The image above shows the dots button (1), along with the import and export options (2). You can export the complete configuration or individual calls as cURL. These exported cURL files can be used later for API calls. Please refer to the PoolParty Workbench guide for more details on how to export configuration and individual calls. These requests may look like this:
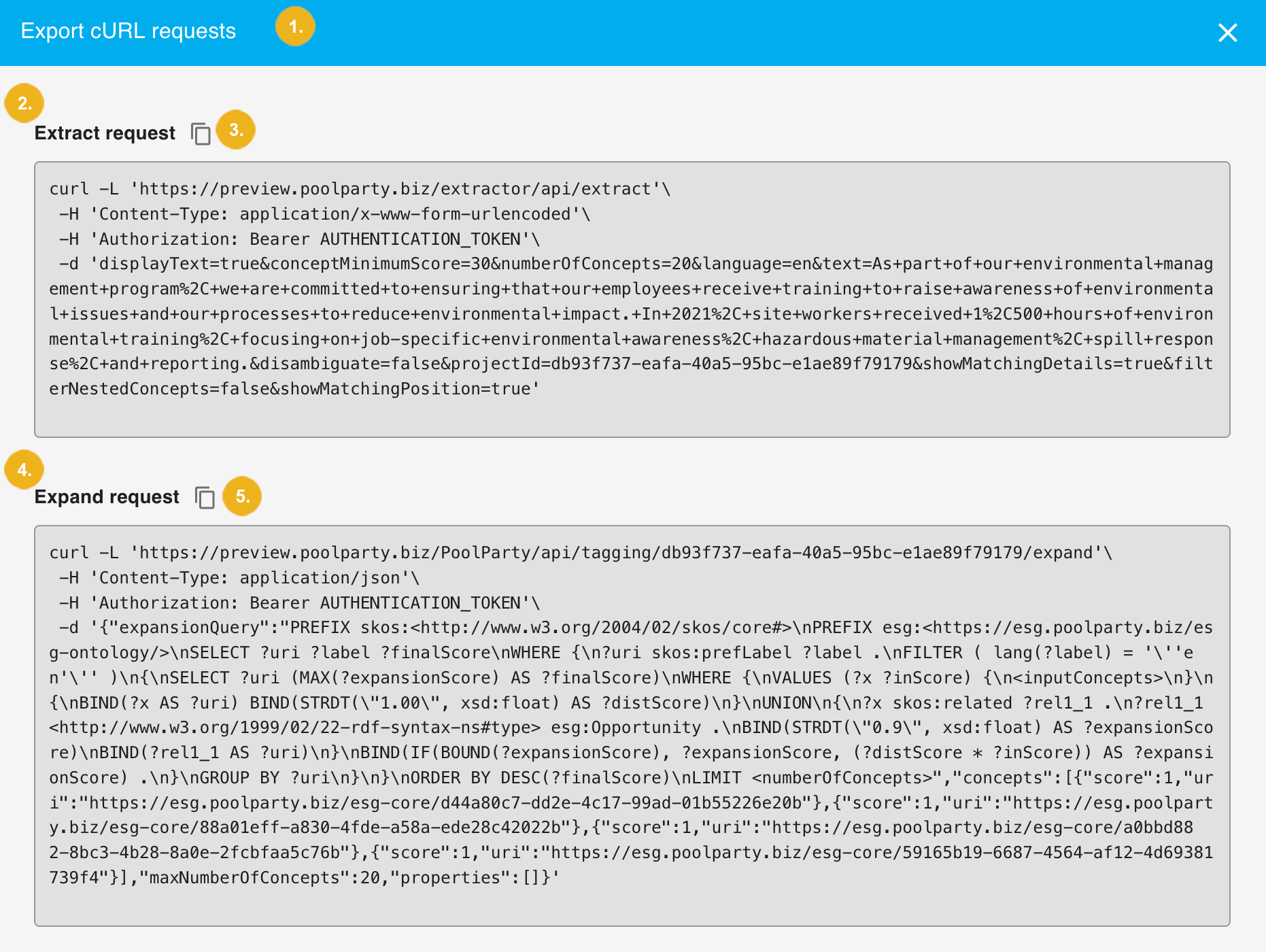
Exporting as cURL opens the Export cURL requests (1) window where you see the Extract request (2), and a page symbol next to it (3) which will copy the complete request to clipboard; below is the second request - the Expand request (4) also with the page symbol next to it (5) allowing you to copy the complete request to clipboard.
The EXPANSION tab offers also a possibility to formulate advanced queries directly on the command line. This is possible on the Switch to SPARQL (2) sub-tab which looks as follows:
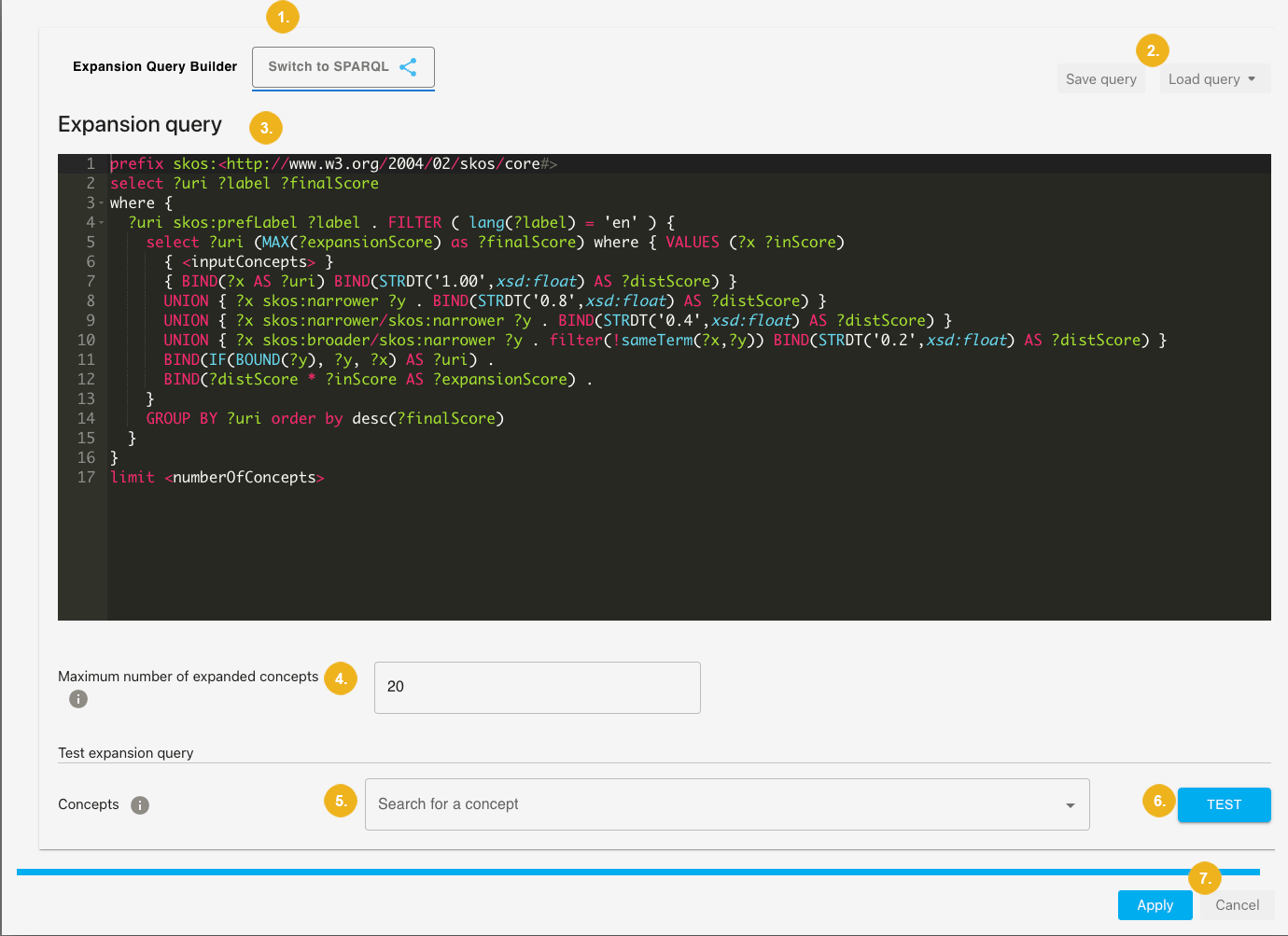
In the top right area you have two buttons Save query (2) and Load query (2). The large section below called Expansion query (3) is where you enter the SPARQL query with all rules and relations you want to specify. Underneath you can set the Maximum number of expanded concepts (4) and test your query by entering concepts in the Concepts (5) field and clicking the TEST (6) button.
To test your SPARQL query use the Test expansion query section. There you only need to enter a concept from the extraction in the Concepts (5) field and click on the TEST (6) button. The input field Concepts: uses the auto-complete function, i.e. after having entered thirst three letters of a concept you will automatically see a list with one or more concepts matching the first leading letters. Simply select one of those shown here. You can specify more than one concept for testing your query.
Click the Apply (7) button to add your query to the configuration or the Cancel (7) button if you want to discard the formulated query and any other settings you may have made on the other two tabs - PROJECT and EXTRACTION.
The example we will use is based on the following scenario:
A Knowledge Manager wants to identify opportunities that can be inferred from concepts found in their documents. Such opportunities may or may not be explicitly stated in the content, but attributable to the combined power of Inference Tagging and knowledge model, all documents will be annotated using such inferred concepts.
The input text used in our example is: As part of our environmental management program, we are committed to ensuring that our employees receive training to raise awareness of environmental issues and our processes to reduce environmental impact. In 2021, site workers received 1,500 hours of environmental training, focusing on job-specific environmental awareness, hazardous material management, spill response, and reporting.
The intention of this query is to identify any opportunities that can be inferred from the concepts found in this input texts.
After running both an extraction and expansion query we will see the following concepts (both the extracted and expanded color-coded concepts) returned for the input text and the selected project (1).
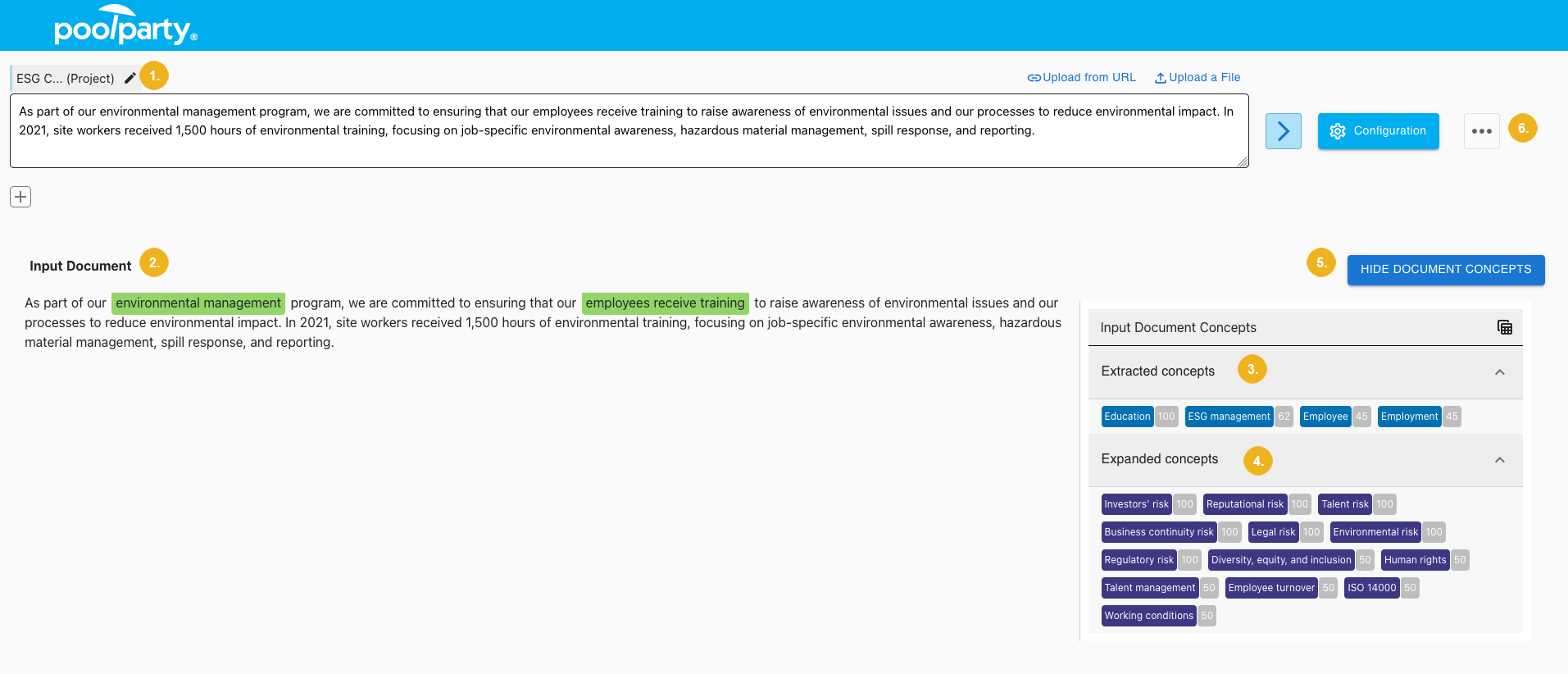
Below the Input Document (2) heading you see the input text with identified concepts. To the right you see all Extracted concepts (3) and all Expanded concepts (4). Next to each concept is its score.