Tabular File To RDF
Tabular File To RDF
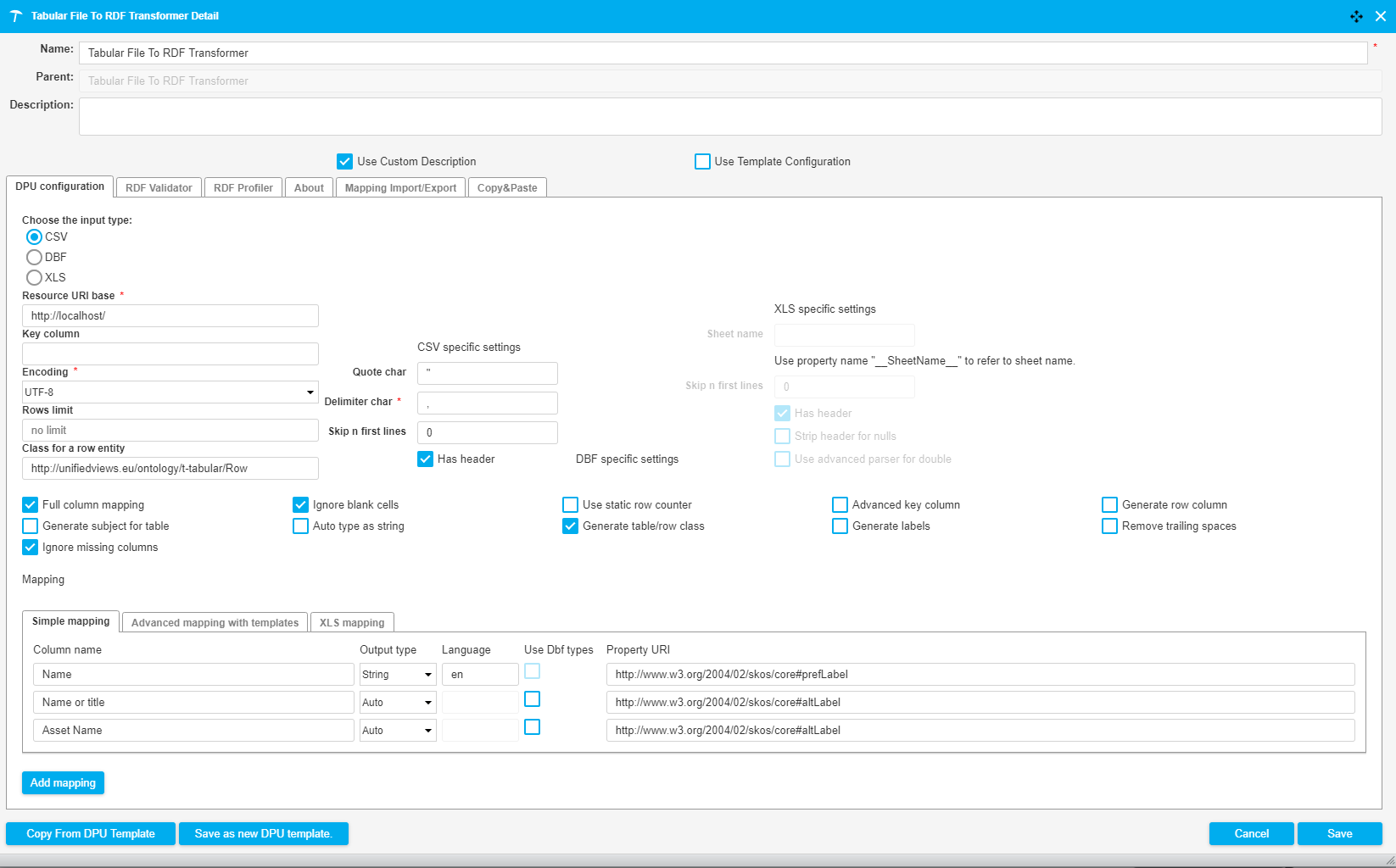
This DPU converts tabular data into RDF data. As an input it takes CSV, DBF and XLS files.
It supports RDF Validation Extension.
Name | Description | Example |
|---|---|---|
Resource URI base | This value is used as base URI for automatic column property generation and also to create absolute URI if relative URI is provided in 'Property URI' column. | http://localhost/ |
Key column | Name of the column that will be appended to 'Resource URI base' and used as subject for rows. | Employee |
Encoding | Character encoding of input files. Possible values: UTF-8, UTF-16, ISO-8859-1, windows-1250 | UTF-8 |
Rows limit | Max. count of processed lines | 1,000 |
Class for a row entity | This value is used as a class for each row entity. If no value is specified, the default "Row" class is used. | http://unifiedviews.eu/ontology/t-tabular/Row |
Full column mapping | A default mapping is generated for every column | true |
Ignore blank cells | Blank cells are ignored and no output will be generated for them. | false |
Use static row counter | When multiple files are processed those files share the same row counter. The process can be viewed as if files are appended before parsing. | false |
Advanced key column | 'Key column' is interpreted as template. An example of a template is http://localhost/{type}/content/{id}, where "type" and "id" are names of the columns in the input CSV file. | false |
Generate row column | If checked, a triple containing the row number is generated for each row. The triple looks like this: <URI> <http://linked.opendata.cz/ontology/odcs/tabular/row> <Row Number>. | true |
Generate subject for table | A subject for each table that points to all rows in given table is created. The predicate used is "http://linked.opendata.cz/ontology/odcs/tabular/hasRow". With the predicate "http://linked.opendata.cz/ontology/odcs/tabular/symbolicName" the symbolic name of the source table is also attached. | false |
Auto type as string | All auto types are considered to be strings. This can be useful with full column mapping to enforce the same type over all the columns and get rid of warning messages. | false |
Generate table/row class | If checked, a class for the entire table is generated. The triple looks like this: <File URI> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type><http://unifiedviews.eu/ontology/t-tabular/Table>. Note: This additional triple is only generated when "Generate subject for table" is also checked. | false |
Generate labels | If checked, a label for each column URI is generated. The corresponding value of the header row is used as label. If the file does not contain a header data from the first row is used.It does not generate labels for advanced mapping. | false |
Remove trailing spaces | Trailing spaces in cells are removed. | false |
Ignore missing columns | If a named column is missing only info level log is used instead of error level log. | false |
There are three different types of mapping available:
Simple mapping
Advanced mapping with templates
XLS mapping
The simple mapping tab allows to define how the columns should be mapped to the resulting predicates, including also information about the datatypes. The Advanced mapping tab is equivalent to the Simple mapping tab, but it allows to specify templates for values of the predicates. A sample template is http://localhost/{type}/content/{id}, where "type" and "id" are names of the columns in the input file. The XLS mapping can be used for the static mapping of cells to named cells. Named cells are accessible as extension in every row.
Name | Description | Example |
|---|---|---|
Quote char | If no quote char is indicated, no quote chars are used. In this case values must not contain separator characters. | " |
Delimiter char | Character used to specify the boundary between separate values. | , |
Skip n first lines | Number of indicated rows are skipped when processing the file. | 10 |
Has header | If the file has no header the columns are accesible as col0, col1, .... | true |
Name | Description | Example |
|---|---|---|
Sheet name | Specify the name of the sheet that is to be processed. | Table1 |
Skip n first lines | Number of indicated rows are skipped when processing the file. | 10 |
Has header | If the file has no header the columns are accesible as col0, col1, .... | true |
Strip header for nulls | Trailing null values in the header are removed. This can be useful if the header is bigger than data so that no exepton for "diff number of cells in header" is thrown. | false |
Use advanced parser for double | In XLS integer, double and date are all represented in the same way. This option enables advanced detection of integers and dates based on value and formatting. | false |
Name | Type | Data Unit | Description | Required |
|---|---|---|---|---|
table | input | FilesDataUnit | Input files containing tabular data |  |
triplifiedTable | output | FilesDataUnit | RDF data | |
The following image shows a fragment of a pipeline which downloads a CSV file from the tmp folder of the UnifiedViews server. The data of the file is subsequently converted to RDF and loaded into a Virtuoso triple store. The DPU configuration is illustrated in the image below.
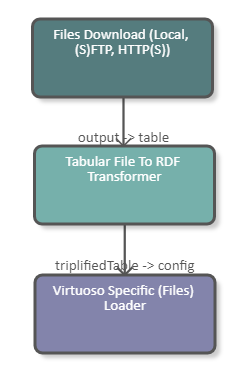 |
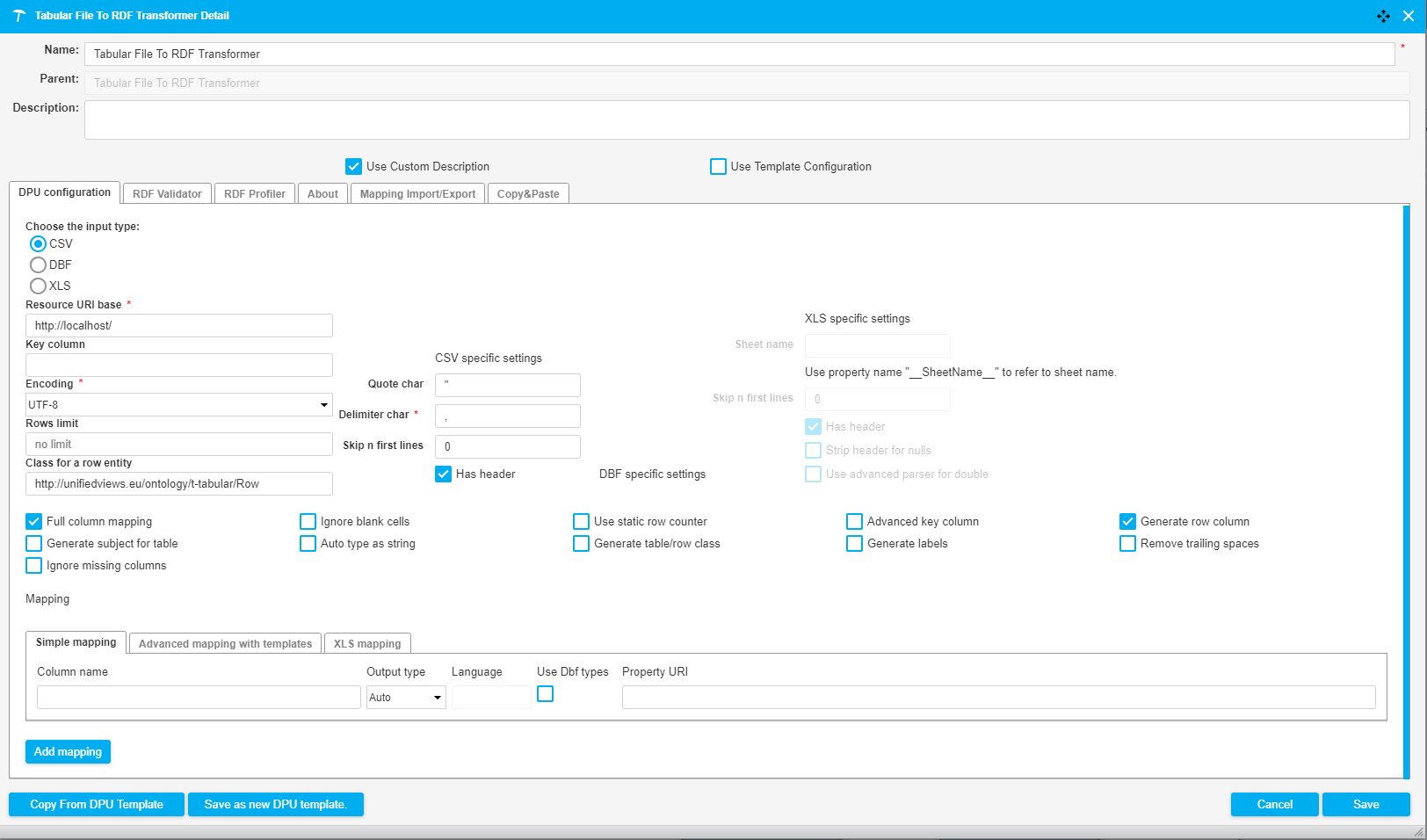 |
The following image shows a fragment of a pipeline which downloads an Excel file (.xls) from the tmp folder of the UnifiedViews server. The data of the Excel file is subsequently converted to RDF and serves as input for a SPARQL Construct Query. The purpose of this query is to construct the configuration file of the second Files Download DPU. After the files are downloaded they are uploaded to the tmp folder of the UnifiedViews server using the Files Upload DPU. The DPU configuration is illustrated in the image below.
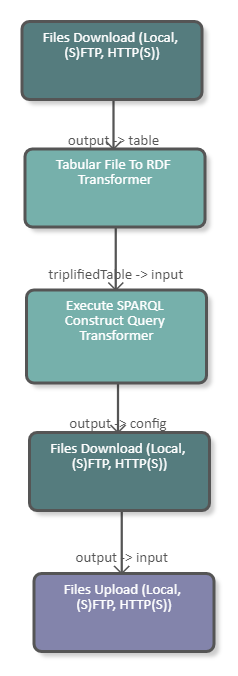 |
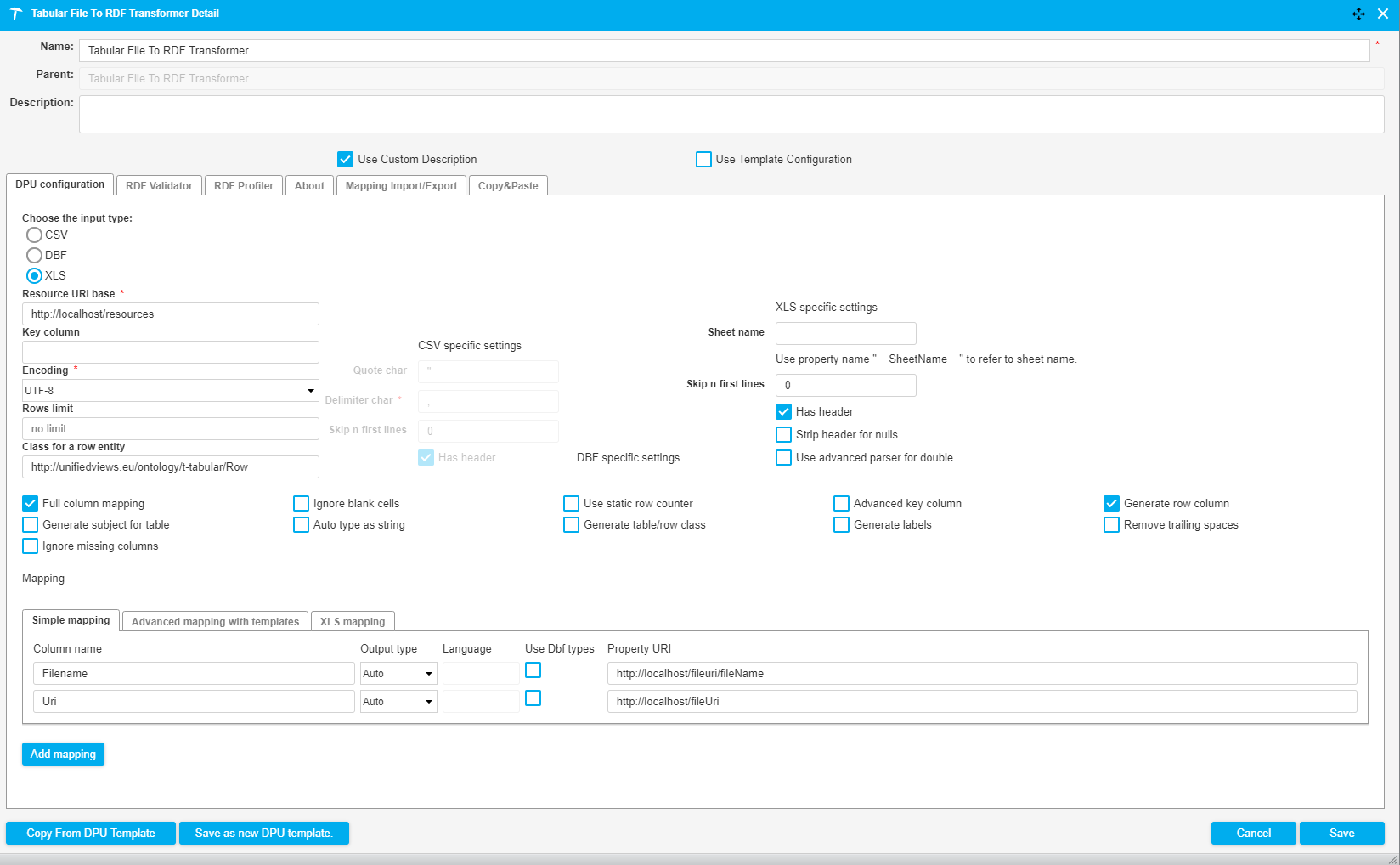 |
The query used in this pipeline creates triples containing the download URI and the file name of the files that are to be downloaded. The query reads as follows:
CONSTRUCT {
<http://localhost/resource/config> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://unifiedviews.eu/ontology/dpu/filesDownload/Config>;
<http://unifiedviews.eu/ontology/dpu/filesDownload/hasFile> <http://localhost/resource/file/0>.
<http://localhost/resource/file/0> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://unifiedviews.eu/ontology/dpu/filesDownload/File>;
<http://unifiedviews.eu/ontology/dpu/filesDownload/file/uri> ?fileUri;
<http://unifiedviews.eu/ontology/dpu/filesDownload/file/fileName> ?fileName.
}
WHERE {
?s <http://localhost/fileuri/fileName> ?fileName.
?s <http://localhost/fileUri> ?fileUri
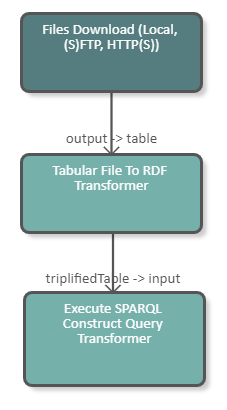
}The following image shows a fragment of a pipeline which downloads a CSV file from the server and transforms it into RDF. With a SPARQL Construct we convert the URI generated by the Tabular File To RDF Transformer into a UUID. The DPU configuration is illustrated in the image below.
 |
 |