Loader DPUs
Loader DPUs
Loader DPUs are integration points with the external data sources similarly to Extractor DPUs.
In contrast to the extractors though, loaders only accept input from other DPUs and have no output. They load the received data to the external data sources based on the configuration. This is usually the last step of a data processing pipeline, where new data is produced and published to other users for further consumption.
PoolParty UnifiedViews provides DPUs to load data to file systems, HTTP API endpoints, SQL and SPARQL endpoints, and more.
Please refer to the respective topics for detailed descriptions:
DPU Documentation Template
DPU Documentation Template
<Explain the functionalities of the DPU>
<List of the configurable parameters in DPU configuration panel>
Name | Description | Example |
|---|---|---|
<List of the DPU input / output channels>
Name | Type | Data Unit | Description | Mandatory |
|---|---|---|---|---|
<Explain any important concept or parameter specific to this DPU>
<Provide examples and screenshots of pipeline and DPU configuration to cover the features of the DPU as much as possible>
* symbol is a notation for mandatory fields. Please remove it before publishing
RDF Loader
RDF Loader
RDF HTTP Loader executes update queries in and load the input RDF data to a remote SPARQL endpoint via HTTP based on SPARQL 1.1 Update Protocoland SPARQL 1.1 Graph Store HTTP Protocol. It is compatible with any SPARQL endpoint supporting the aforementioned protocols.
Name | Description | Example |
|---|---|---|
Host | Resolvable host name or IP address of the target remote SPARQL endpoint (excluding protocol prefix such as "http://") | |
Port | Port number of the SPARQL endpoint | 8080 |
SPARQL Endpoint | The context path of the SPARQL endpoint relative to base URL | /sparql |
Basic Authentication | HTTP Basic Authentication for the SPARQL endpoint | true |
Username | Account name of the user granted access to the SPARQL endpoint | dba |
Password | Password of the user | *** |
Input Data Type | Type of input data for this DPU, see the following chapters for more information | RDF | File | SPARQL Update |
RDF File Format | Serialization format of the RDF data when input as file | Turtle |
Specify Target Graph | Enable the input to specify the loading destination of RDF data | true |
Graph URI | URI of the target RDF graph | |
Overwrite Existing Data | Decide if new data overwrites or appends to existing data | true |
SPARQL Update | SPARQL Update query to be executed on the SPARQL endpoint | DELETE WHERE {?s ?p ?o} |
Validate Update Query | Verify if the syntax of SPARQL update query is correct | true |
Name | Type | Data Unit | Description | Mandatory |
|---|---|---|---|---|
rdfInput | input | RDFDataUnit | RDF data in RDF objects or RDF data structure |  |
fileInput | input | FilesDataUnit | RDF data serialized to a standard RDF serialization file format | |
RDF HTTP Loader deals with three types of input data:
RDF: selected when RDF data comes from rdfInput wrapped in RDFDataUnit as Java Objects. In such case the input data is serialized into N-Triples, inserted into the body of a SPARQL Update query, and loaded to the target SPARQL endpoint through update query. This approach can be used for small datasets if N-Triples serialization is less than 10 MB.
File: selected when RDF data comes from fileInput wrapped in FilesDataUnit as files based on any standard RDF serialization format. In this case the input data is uploaded to the SPARQL endpoint as files in post body. In the meanwhile RDF File Format must be specified properly to set the appropriate content type header in the request. This approach is recommended for large datasets. Note that the SPARQL endpoint for file uploading of nearly every RDF database is different. So it is necessary to adjust the path of SPARQL endpoint accordingly.
SPARQL Update: selected when input data is provided manually in the update query instead of the connected DPU or any update and management task needs to be executed on the SPARQL endpoint. Based on the selection of input data type, the corresponding input data source is used to retrieve data. An error will be thrown when the input data type and input data source do not match.
The service path of SPARQL endpoint differs according to the RDF database. The following table summarizes the paths for common RDF databases.
Database | Path Variable | Service Path for SPARQL Update | Service Path for SPARQL Graph Store HTTP Protocol |
|---|---|---|---|
RDF4J | $REPOSITORY: RDF4J repository name | /$REPOSITORY/statements | /$REPOSITORY_ID/rdf-graphs/service |
Stardog | $DATABASE: Stardog database name | /$DATABASE/update | /$DATABASE |
MarkLogic | None. "repository" is decided by port number | /v1/graphs/sparql | /v1/graphs |
Allegrograph | $REPOSITORY: RDF4J repository name | /repositories/$REPOSITORY | Not supported |
GraphDB | $REPOSITORY: GraphDB repository name | /$REPOSITORY/statements | /$REPOSITORY_ID/rdf-graphs/service |
URI of the target RDF graph on the SPARQL endpoint can be specified to describe the destination of the RDF data to be loaded into. The default graph is used if no graph URI is specified by the user. In the case that input data type is a SPARQL update query, this option is disabled because graph operations should be specified in the update query.
When files are used as input to be loaded to the remote SPARQL endpoint, one can specify if the new data is inserted into the existing target graph directly or after clearing the target graph. This operation is defined in SPARQL Graph Store HTTP Protocol by using HTTP operation POST or PUT. For SPARQL endpoints not conforming to this protocol strictly, inserting data to a non-existing target graph with overwritten option by HTTP PUT may do nothing.
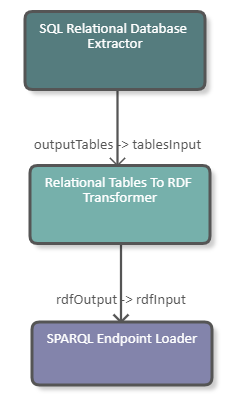
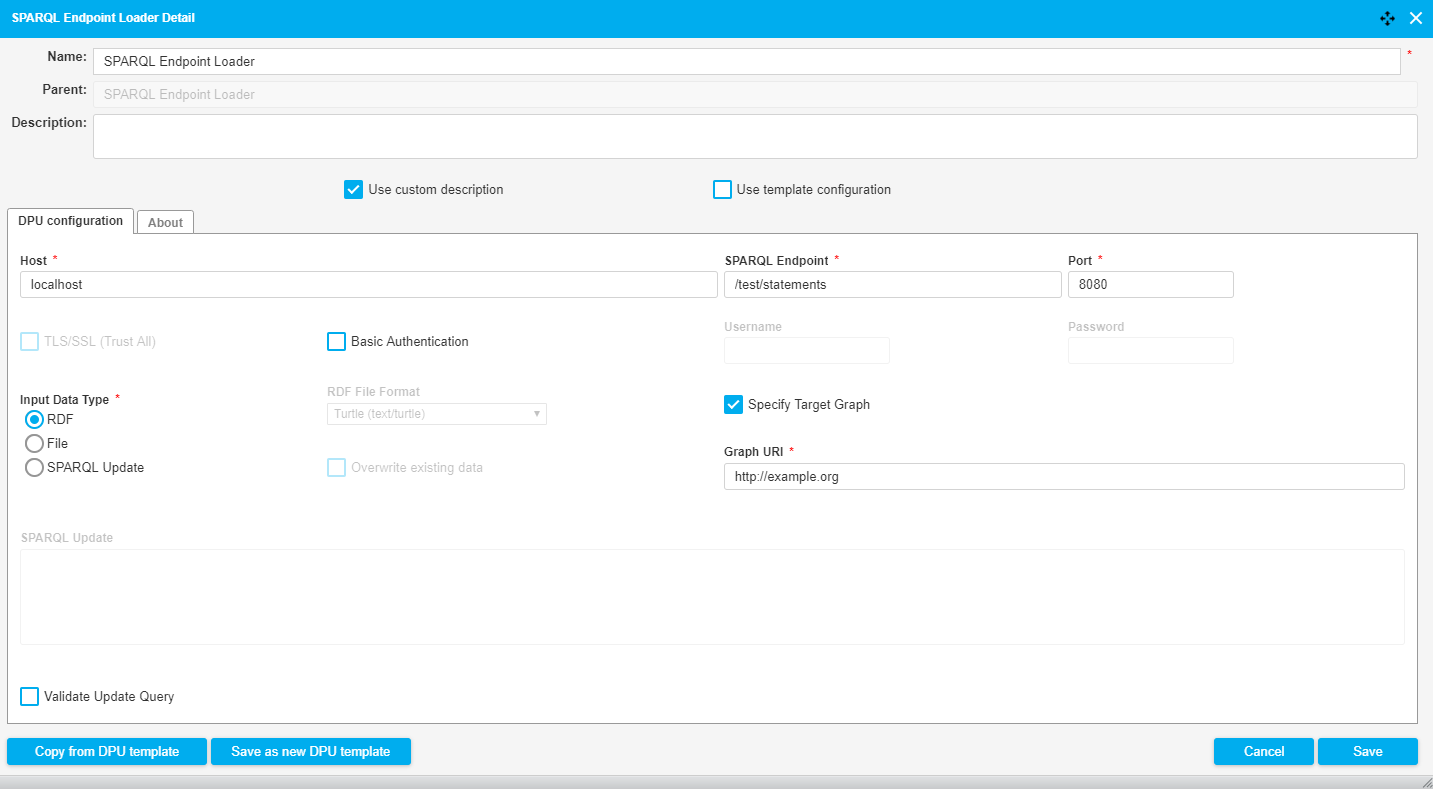
The following image shows a fragment of a pipeline which retrieves data from a SQL database, transforms relational data to RDF data, and loads RDF data to a remote SPARQL endpoint. The DPU receives RDF data from its "rdfInput" channel so the "Input Data Type" is set to "RDF". The target is an RDF4J repository named "test", so the correct path for the SPARQL update endpoint is "/test/statements". Data is loaded to a named graph with URI <http://example.org>. The DPU configuration is also illustrated in the image.
 |
 |
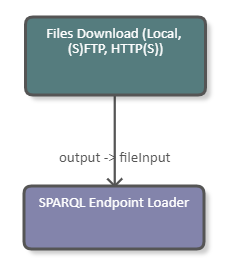
The following image shows a fragment of a pipeline which downloads an RDF Turtle file from file system and loads it to a remote SPARQL endpoint. The DPU receives file data from its "fileInput" channel so the "Input Data Type" is set to "File". "RDF File Format" is set to "Turtle" because of the format of the input file. The target is an RDF4J repository named "test", so the correct path for the SPARQL Graph Store HTTP endpoint is "/test/rdf-graphs/service". File is loaded to a named graph with URI <http://example.org> without removing existing data. The DPU configuration is also illustrated in the image.
 |
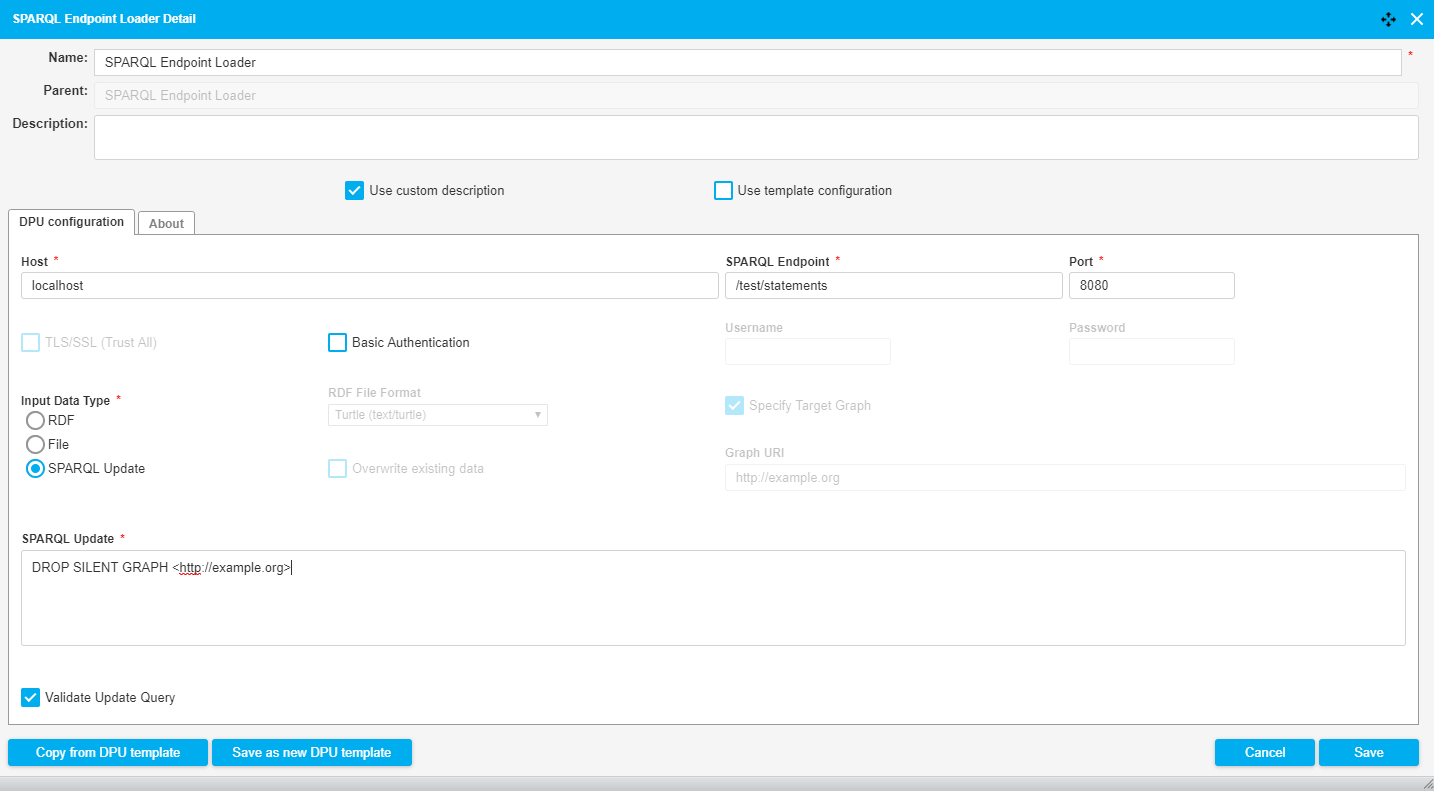
The following image shows a fragment of a pipeline which runs a SPARQL update query in a SPARQL endpoint. The DPU does not need any input since the update query is provided in the DPU configuration. The "Input Data Type" is set to "SPARQL Update". "SPARQL Endpoint" is same as accepting RDF data. "SPARQL Update" is a query to drop a graph from the SPARQL endpoint with the query validated for syntax correctness. The DPU configuration is also illustrated in the image.
 |
 |