Analyse Documents in Your Document Corpus
Analyse Documents in Your Document Corpus
How do you use PoolParty's Corpus Analysis?
After you have uploaded documents to your corpus, you can start a corpus analysis.
Select the Metadata & Statistics tab in the corpus Details View.
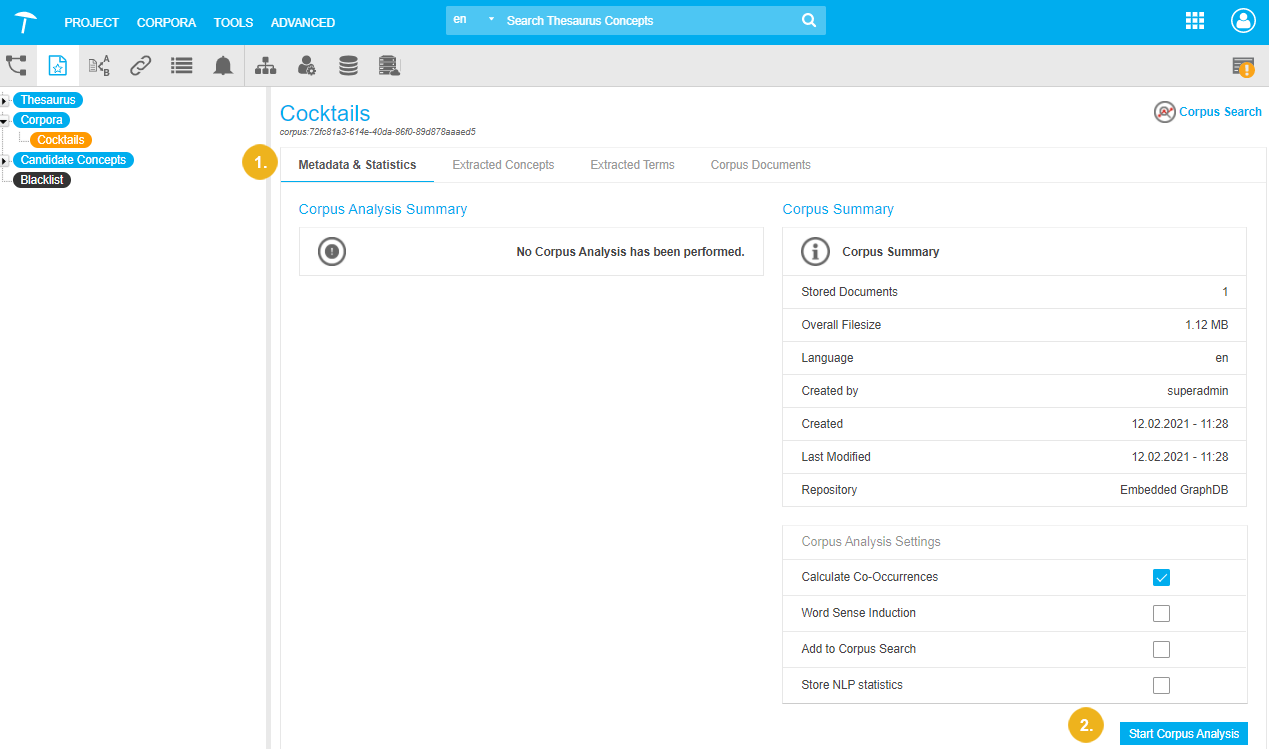
Click Start Corpus Analysis in the bottom right-hand corner.
You can also start the corpus analysis using the respective entry in the context menu of the corpus node.
After the first calculation the button is renamed to Recalculate Corpus Analysis.
The Analyzing Corpus dialogue opens providing information on the status and progress of the analysis process. You can stop the analysis by clicking Cancel.
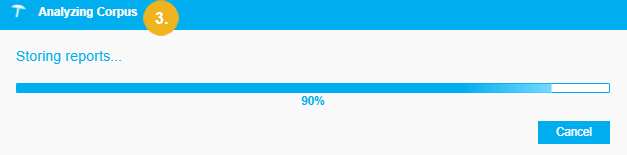
When the analysis is completed, the dialogue is closed and the updated statistics are displayed in the Corpus Analysis Summary.
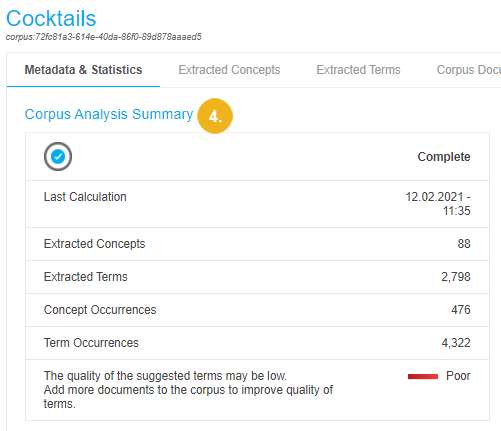
Note
If not available, the necessary extraction model for the project is calculated automatically when you start the corpus analysis.
In case you changed your thesaurus, you have to recalculate the extraction model first so the changes take effect in the corpus analysis.
In the Corpus Analysis Settings section of the Metadata & Statistics tab in the Corpus Details View you can enable and disable additional calculations to be performed in the course of a corpus analysis:
Calculate Co-Occurrences: activate this check box to find co-occurrences of terms in the corpus with concepts of your thesaurus and of concepts found in the documents. Co-occurring terms are suggested to enrich candidate concepts and thesaurus concepts as synonyms or possible related concepts. Co-occuring concepts are suggested as relations for candidate concepts. (Default: enabled)
Word Sense Induction: enable this to disambiguate potentially ambiguous terms. By calculating co-occurrences the context of a word will enable PoolParty to make sure, if a term means a coffee brand instead of a cocktail. The term 'Americano' would be such an example. (Default: disabled)
Add to Corpus Search: activate to use the Corpus Search function in PoolParty. It allows you to quickly check on the corpus and its contents in relation to your thesaurus, as a search application would present it. (Default: disabled)
Store NLP statistics: activate if you want to store the frequency and score for each concept found in the corpus. The statistics are attached to the concept in the thesaurus data and can be retrieved via PoolParty's SPARQL Endpoint.
The corpus analysis results in the following lists:
Details on the corpus quality find here: Corpus Quality
Tip
If you would like to learn more about this topic, please watch this PoolParty Academy Tutorial video:
2.5 Corpus Management Advanced
When the video is not available, you can sign up to the PoolParty Academy.