PoolParty Recommender at a Glance
This sections aims at making you a bit more familiar with the workflow used by the PoolParty semantic recommender. It also provides some information on text annotations, knowledge graph, semantic expansion (also called semantic footprinting) and the delivered results for which you can follow the reasoning path from input to result.
The following workflow illustrates how the PoolParty semantic recommender functions.
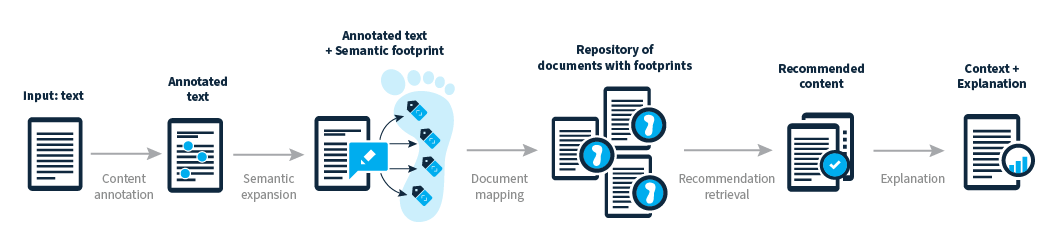
Input stands for a text. It may be either a paragraph or section of a document, or even an entire document.
The input text is processed by the PoolParty Extractor being the text annotation component. The PoolParty Extractor adds concepts to the input from the underlying knowledge graph (which is the domain model).
The concepts are then semantically expanded on the basis of this domain model providing additional context to the input. This process is referred to as semantic footprinting and serves enhancement of retrieval of the recommendations. The expansion calls use SPARQL.
Recommendation results can now be retrieved based on the annotated and enriched input.
Context is provided for every individual result clarifying the reasons underlying such recommendation results.
Let us now look at some of these individual steps in greater detail - text annotations, semantic expansion and clear, traceable and transparent results.
Text Annotations
The PoolParty Extractor takes the most relevant concepts, terms, and named entities from a given document or text section, whereas the Recommender only uses concepts. The Extractor can distinguish ambiguous terms which may refer to multiple concepts based on the taxonomy structure and the local context of the ambiguous concepts.
Different data or metadata schemes can be mapped to a thesaurus used as a unified semantic knowledge model. During this process the extracted entities are linked to the knowledge model (the thesaurus) by URIs ensuring direct integration in line with the Semantic Web principles.

Knowledge Graph
Knowledge graphs (KG) are models of a knowledge domain created by subject-matter experts. KGs provide a structure and common interface for data and enable creation of smart multilateral relations throughout databases. Enterprise knowledge graphs help companies create their specific web of knowledge representing their specific domain.
In the recommender, knowledge graphs provide the vocabulary for tagging content with domain relevant concepts. Additionally, they give the context to the concepts identified in the process of semantic footprinting.
Semantic Expansion
In the process of semantic expansion, concepts are placed into the context of the domain model (i.e. the knowledge graph). Nodes closely connected to the source concept are those which are related to it. How they are related to it is defined by the edges which connect the nodes. The semantic expansion defines rules or heuristics determining the patterns of edges in the knowledge graph to be traversed.
The result of such expansion is a footprint of concepts which encompass the surroundings of the source concept in a defined way. This context from the knowledge graph sets the semantic recommendation approach apart from methods without such explicit knowledge. The semantic recommender reaches further (increasing recall) without losing precision as the context is semantically defined.
Clear, Traceable and Transparent Results
One major advantage of the semantic recommendation approach is that the results are clear, traceable and transparent. You can follow the reasoning path from input to result.
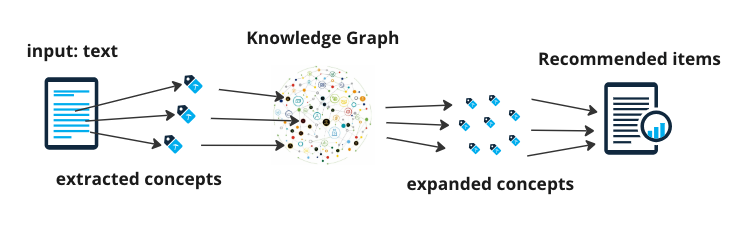
The figure above illustrates this process. Domain specific concepts are extracted from the input text. Their context is obtained through the knowledge graph (expanded concepts or semantic footprint) and recommended items being then retrieved. The PoolParty Semantic Recommender synergistically combines the advantages of concept-based search with the full-text search functionality of Elasticsearch. Elasticsearch index is required for the last call, the recommendation.