Execution Monitor Section
Execution Monitor Section
This section contains a guide on the Execution Monitor of UnifiedViews and the available options there.
The Execution Monitor section of the main menu is used to view detailed information about pipeline execution.
The following topics are contained in this section to guide you through the options:
Execution Monitor Overview — This section contains a short guide on the Execution Monitor and it options and settings.
Execution Monitor - Options in Execution Records — This section contains a short guide on options that are available inside the Execution Monitor.
Viewer for Execution Details (VED) - Tabs — This section contains a guide on the Viewer for Execution Details (VED) and its tabs.
Execution States in the UnifiedViews Execution Monitor — This section contains a short guide on the individual execution states visible in the Execution Monitor.
Note
Terms special to UnifiedViews and their meaning are explained in our UnifiedViews Glossary .
Execution Monitor Overview
Execution Monitor Overview
This section contains a short guide on the Execution Monitor and it options and settings.
The Execution Monitor section is represented as a table that contains the following columns.
Note
You can sort by the columns Status, Pipeline, Started, Debug, Scheduled, or Executed by.
Column | Icon | Option | Description | |
|---|---|---|---|---|
Actions | Debug data | NoteThis icon has two functions, depending on how the pipeline is executed. is displayed for executions that have been started in debug mode. | ||
Show log | is displayed for executions that have been started in common mode. | |||
| Cancel | is displayed only for executions which are in RUNNING and SCHEDULED states. | ||
Run pipeline | is displayed for executions which are in all states except RUNNING and CANCELLING. | |||
Debug pipeline | is displayed for executions which are in all states except RUNNING and CANCELLING. | |||
Status | actual status of the executions, depicted by these icons | |||
| SCHEDULED | |||
| RUNNING | |||
| CANCELLING | |||
| CANCELLED | |||
| FAILED | |||
| FINISHED SUCCESS | |||
| FINISHED WARNING | |||
Pipeline |
| Details icon | name of the executed pipeline - click the icon to display the details of this pipeline | |
Started | - | Date and time of the last run of this pipeline | ||
Duration | - | Time that the execution has taken. | ||
Debug |
| shows if a pipeline has been run on debug mode or in run mode | ||
Scheduled |
| shows if a pipeline has been scheduled or not | ||
Executed by | user name of the user that executed the pipeline | |||











Above the table, there are these buttons:
Refresh: for refreshing the table.
Reset Filers: for clearing filters of the table.
Reset Sort: to reset custom sorting.
 |
Execution records are created and placed into the table after the following actions:
Run a pipeline from the Pipelines section.
Debug a pipeline from the Pipelines section.
Clicking Debug to this DPU icon on the DPU instance tool bar in pipeline canvas.
The start which is planned by a scheduling rule.
Execution Monitor - Options in Execution Records
Execution Monitor - Options in Execution Records
This section contains a short guide on options that are available inside the Execution Monitor.
You are authorized to interrupt the pipeline execution if this button is visible. Click to cancel the execution.
Note
The Cancel button is available in an execution table only if the pipeline execution is in states RUNNING or SCHEDULED.
The user is able to repeat the pipeline running directly from Execution Monitor section. Click Run, or Debug for running in debug mode .
Note
New executions will be shown in the table.
Click Debug Data (3), to follow the events, logs and (when debugging) data flow between DPUs.
The Viewer for Execution Details (VED) appears as a slide window on the right side (4). VED lists all records of the pipeline execution.
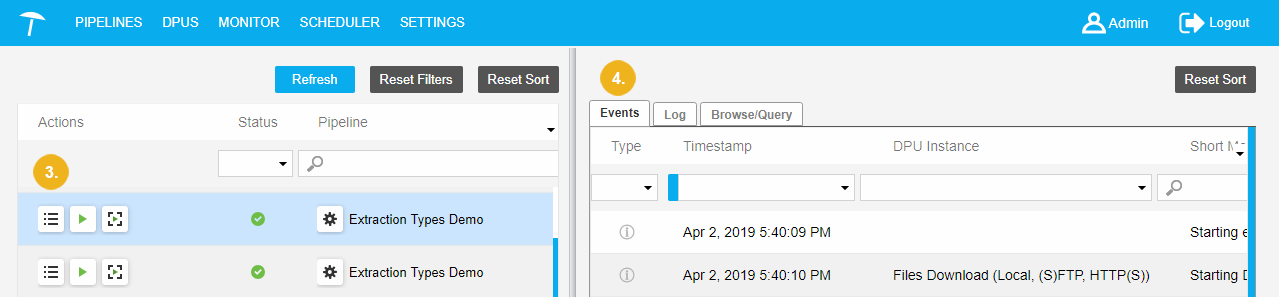 |
The user may follow the data flow between DPUs. VED consists of three tabs:
Viewer for Execution Details (VED) - Tabs
Viewer for Execution Details (VED) - Tabs
This section contains a guide on the Viewer for Execution Details (VED) and its tabs.
Viewer for Execution Details (VED) - Events Tab
Viewer for Execution Details (VED) - Events Tab
The Events tab consists of the following columns:
Type: type of an event.
Date: date when an event was started.
DPU Instance: DPU on which the action is performed.
Short Message: description of an event.
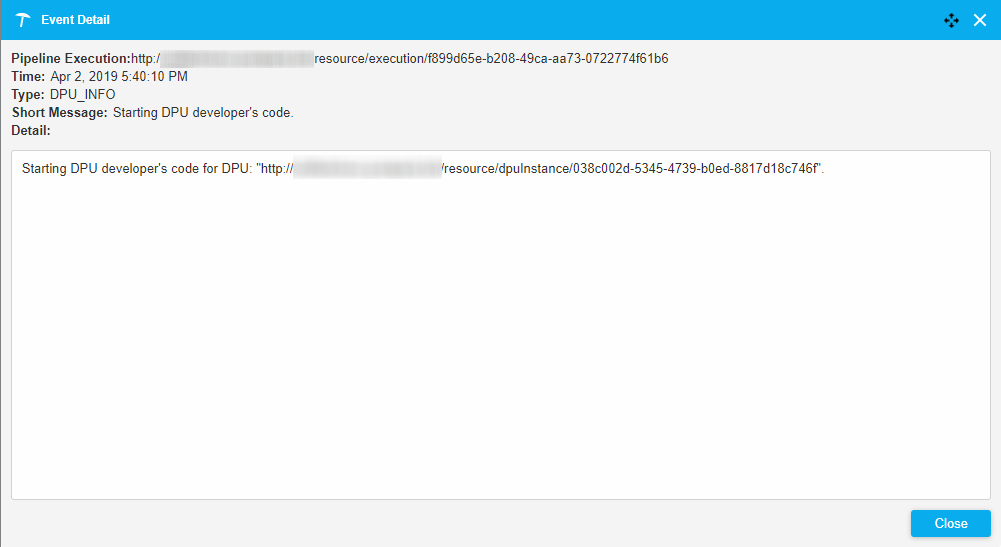
The page of latest events is displayed by default:
You can open a record detail by double clicking the respective row in the table:
Viewer for Execution Details (VED) - Log Tab
Viewer for Execution Details (VED) - Log Tab
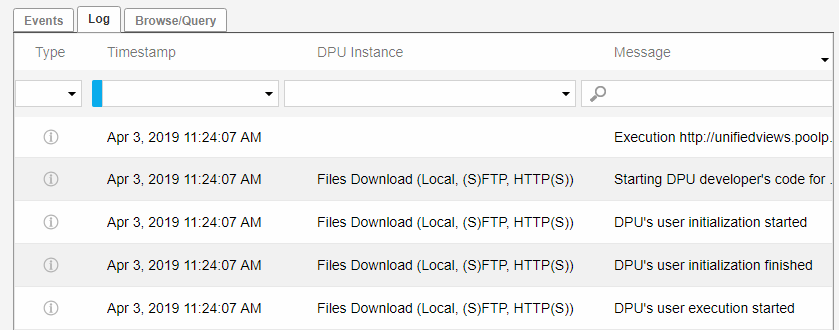
The Log tab consist of the columns: Type, Timestamp, DPU Instance, and Message.
The table can be filtered by these parameters. The page with the latest logs is displayed by default.
 |
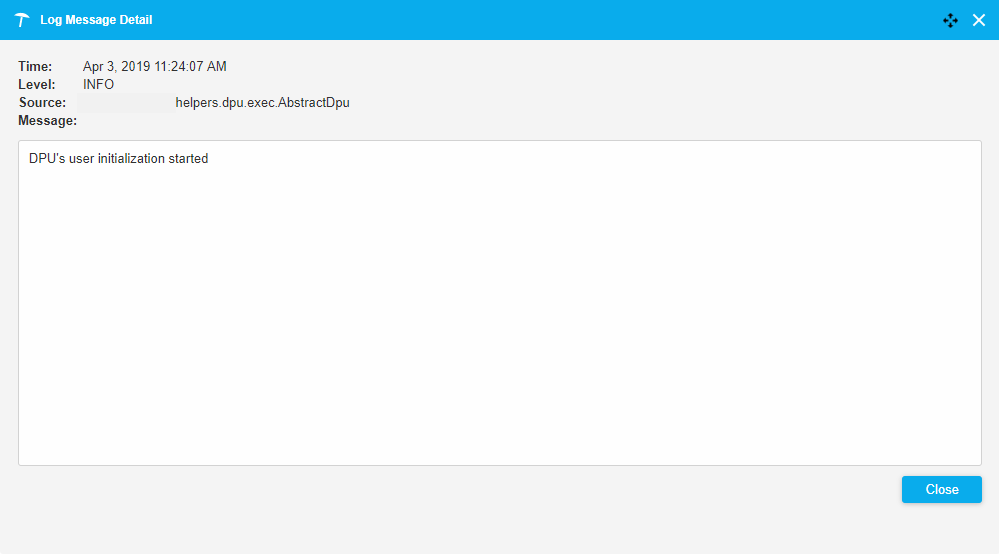
Double click on the row in the Log table to display the Log Message Detail dialogue.
The dialogue contains: Time, Level, Source and Message fields with information.
Use the black Cross icon in the top right-hand corner to toggle the Log Message Details dialogue to either have it fill the browser window or stay in front.
User can download logs in plain text format on the Options tab.
Viewer for Execution Details (VED) - Browse/Query Tab
Viewer for Execution Details (VED) - Browse/Query Tab
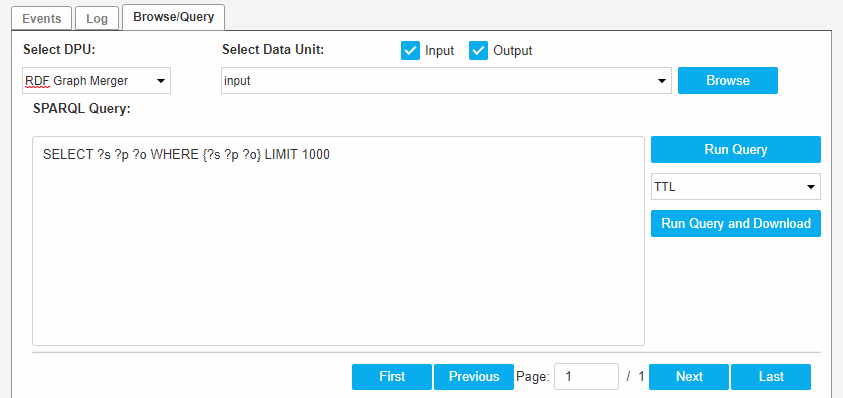
The Browse/Query tab is enabled if the pipeline is running in debug mode only. In all other cases this tab is disabled.
Select an item in the drop down Select DPU, to enable all other components of the tab.
The Select Data Unit drop down displays the first input data unit per default.
If there are no input data units, then the first output data unit is shown.
You can select the Input/Output check boxes. Based on that, the selection of data units is adjusted and again the first data unit is selected.
You can change the value of the Select Data Unit drop down.
 |
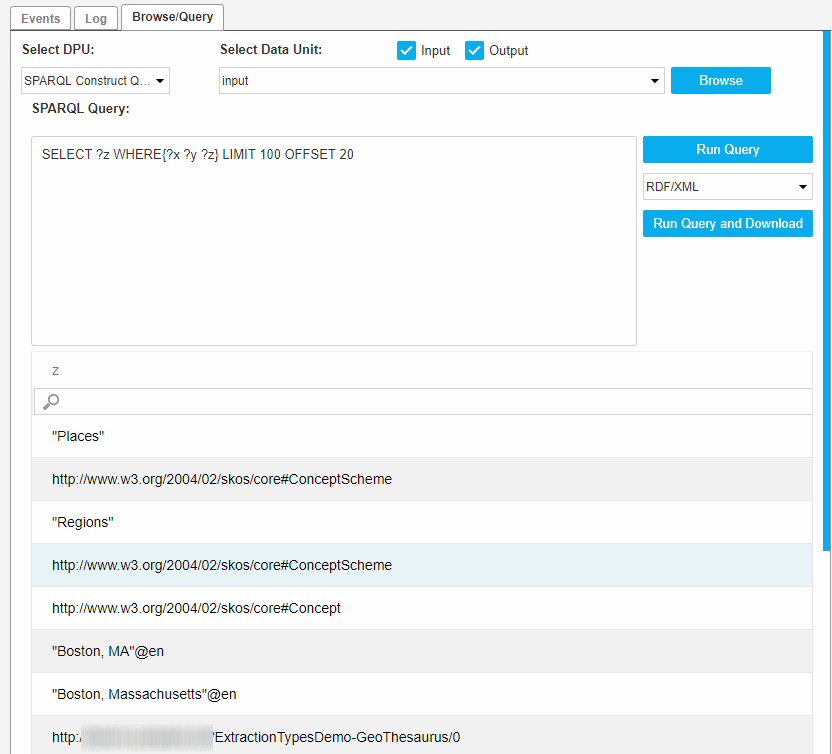
When the Select Data Unit is filled, you can show the data by clicking Browse, which displays all triples in the data unit .
This is internally the same as running construct {?s ?p ?o} where {?s ?p ?o}.
When clicking on the Browse button, the query is prefilled with the default construct query.
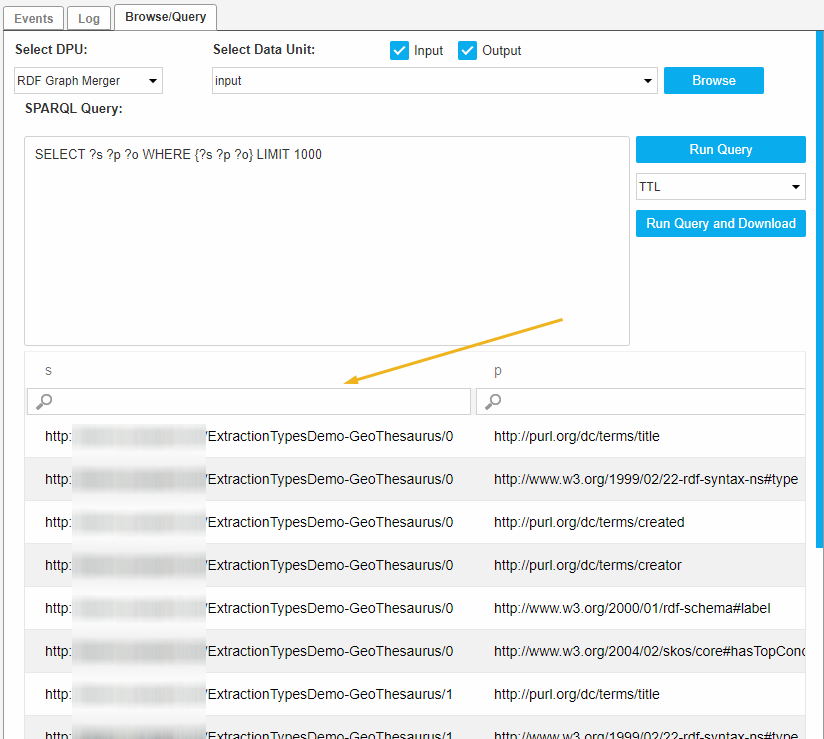
If the user changes Select DPU to be browsed, the available data units are refreshed. Similarly if the user changes the Input/Output selection check boxes, data units are refreshed. But the view of the data is refreshed only when the user clicks on the Browse again.
You can define your own queries and run them.
Enter your query into the SPARQL Query text area and click Run Query.
Note
If you click Run Query, you must provide the query string, otherwise a warning is displayed.
The result of the query will be shown in the table below. Queries are divided into CONSTRUCT and SELECT queries.
SPARQL Query: SELECT ?z WHERE{?x ?y ?z} LIMIT 100 OFFSET 20
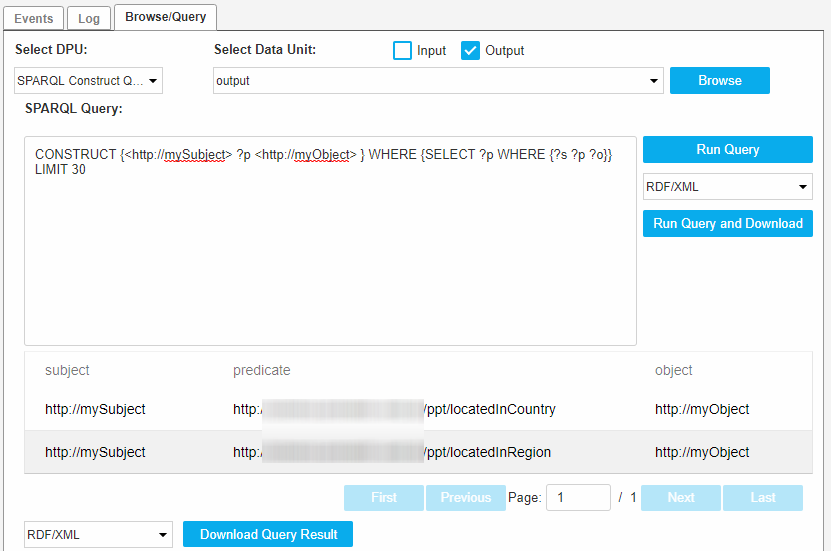
SPARQL Query: CONSTRUCT {<http://mySubject> ?p <http://myObject> } WHERE {SELECT ?p WHERE {?s ?p ?o}} LIMIT 30
If you change the Selected DPU to be browsed, available data units are refreshed.
Similarly, if you change the Input/Output selection check boxes, data units are refreshed.
On the other hand, the result of the query is refreshed only as a result of clicking Run Query.
You can download the results of the running query. Click Download Query Result beneath the table showing the result of a running query.
After that the data will be downloaded in the selected format to the destination you choose.
Download formats are different for two types of queries:
Construct query: formats :RDF/XML, TTL, N3, N-TRIPLES, TRIX and TriG.
Select query: formats are:
XML
CSV
JSON
TSV
You can click the Run Query and Download button. In this case you have to provide the query string.
Otherwise it throws a warning. The data will be downloaded in the selected format to the destination you choose. No data will be shown in the table.
Execution States in the UnifiedViews Execution Monitor
Execution States in the UnifiedViews Execution Monitor
This section contains a short guide on the individual execution states visible in the Execution Monitor.
SCHEDULED state means that the pipeline execution record is stored in the database, but the execution has not started. The pipeline execution in this state is created by scheduler, execution is scheduled for the exact date and time. Also the pipeline execution in SCHEDULED state can be created in case of pressing Run or Debug pipeline buttons when the backend is offline.
RUNNING means that the pipeline currently is in execution state. For each running pipeline the staging data for each DPU in the pipeline are stored in the staging database . The data are stored under automatically generated names. Also a record about execution is stored in database. The record contains last finished DPU.
CANCELLING state is an interim status. It appears after you have clicked Cancel when the pipeline has been in RUNNING or SCHEDULED states. The execution record will remain in the CANCELLING state until the execution is CANCELLED.
 |
CANCELLED state means that the pipeline execution has been interrupted by the Cancel button.
FAILED state means that the pipeline execution started, but a fatal unrecoverable error has occurred somewhere in the execution process.
Therefore the pipeline execution has not finished, which means that a loader has not loaded all the data (or any at all) being processed into intended destination. Graphs in the staging database cannot be deleted in this state, so they may be used for debugging.
FINISHED SUCCESS state means that the pipeline execution finished without any reported errors, a loader successfully loaded all the data into the knowledge base.
FINISHED WARNING state means that the pipeline execution finished, however some recoverable errors occurred during execution. Graphs in the staging database cannot be deleted in this state, so they may be used for debugging.