Annotations Service
Annotations Service
The annotations service enables you to use Web service method calls for adding and removing information (annotations) to and from documents or files.
The following methods are available for the annotations service:
Web Service Method: Annotate and Store from Text
Web Service Method: Annotate and Store from Text
Description |
|---|
[text] Returns the document annotated with extracted concepts and extracted terms in RDF/XML representation. |
URL: /extractor/api/annotate/store/text
Supported Methods |
|---|
POST |
Content-Type: application/json
Parameter | Type | Required | Comment |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptMinimumScore | Double | false | Minimum required score of concepts, default = 0 |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided. |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document, taken from documentUri |
documentUri | String | true | URI of annotated document, used as ID |
extractorVersion | String | false | Version of PPX Extractor used |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = true |
findPersonNames | boolean | false | Deprecated (use nerParameters) - extracts person names from the given text |
graphName | String | false | The name of the graph in the remote repository the PPX results gets written to |
language | String | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Deprecated (use nerParameters) - extracts locations from the given text |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
phraseLength | Integer | false | Phrase length, default = 4 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Furthermore it supports http://www.w3.org/1999/02/22-rdf-syntax-ns#type. Set to all to fetch all properties. |
regexFilename | String | false | File name for regex patterns |
repositoryId | String | false | handle of the target repository to access, defaults to configured property 'remote.repositoryid' |
resultFilterSparql | String | false | Specify an optional SPARQL query for filtering the RDF result |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided. |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
text | String | true | Text of the document |
tfidfScoring | boolean | false | Use TFIDF scoring, default = false |
title | String | false | Title of the document |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
{
"nerParameters" : [ {
"method" : "RULE_BASED",
"type" : "https://semantic-web.com/api/type#26656"
}, {
"method" : "RULE_BASED",
"type" : "https://semantic-web.com/api/type#24840"
} ],
"tfidfScoring" : true,
"useTransitiveBroaderTopConcepts" : false,
"language" : "fr",
"title" : "All about Chuck Norris",
"numberOfTerms" : 29907,
"resultFilterSparql" : "some resultFilterSparql",
"findPersonNames" : false,
"conceptMinimumScore" : 0.6875532724352691,
"customAttributeFilters" : [ {
"property" : "https://semantic-web.com/api/property#14358",
"value" : "some value"
}, {
"property" : "https://semantic-web.com/api/property#2572",
"value" : "some value"
} ],
"corpusScoring" : [ "some corpusScoring", "some corpusScoring" ],
"locationExtraction" : true,
"useRelatedConcepts" : false,
"customClassFilters" : [ "some customClassFilters", "some customClassFilters" ],
"text" : "some text",
"shadowConceptCorpusId" : [ "some shadowConceptCorpusId", "some shadowConceptCorpusId", "some shadowConceptCorpusId" ],
"categorize" : false,
"filterNestedConcepts" : false,
"useTransitiveBroaderConcepts" : false,
"displayText" : true,
"regexFilename" : "some regexFilename",
"categorizationWithPpxBoost" : false,
"documentUri" : "some documentUri",
"numberOfConcepts" : 32518,
"disambiguate" : true,
"showMatchingPosition" : true,
"graphName" : "some graphName",
"extractorVersion" : "6.0.1",
"sentimentAnalysis" : false,
"useTypes" : false,
"documentClassifierIds" : [ "some documentClassifierIds" ],
"repositoryId" : "1DF1343D-0570-0001-FAAF-149079206440",
"conceptSchemeFilters" : [ "https://semantic-web.com/api/conceptSchemeFilters#29423", "https://semantic-web.com/api/conceptSchemeFilters#2556", "https://semantic-web.com/api/conceptSchemeFilters#31614" ],
"documentId" : "corpusDocument:0ac32384-b3c2-4e62-8bcf-7ed4fd67b630",
"lemmatization" : false,
"projectId" : [ "some projectId" ],
"properties" : [ "https://semantic-web.com/api/properties#5962", "https://semantic-web.com/api/properties#2227" ],
"showMatchingDetails" : true
}text/plain
Web Service Method: Annotate and Store from File
Web Service Method: Annotate and Store from File
Description |
|---|
[file] Annotates the file with extracted concepts in RDF/XML format and stores it in the remote repository. |
URL: /extractor/api/annotate
Supported Methods |
|---|
POST |
Content-Type: multipart/form-data
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | Boolean | false | Use Extractor boosting, default = false |
categorize | Boolean | false | Categorization extraction, default = false |
conceptMinimumScore | Double | false | Minimum required score of concepts, default = 0 |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided. |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | Boolean | false | Use thesaurus based disambiguation, default = false |
displayText | Boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input. |
documentId | String | false | Internal ID of the document, taken from documentUri. |
documentUri | String | true | URI of annotated document, used as ID |
extractorVersion | String | false | Version of PPX Extractor used |
file | MultipartFile | true | File to be annotated (Word, Excel, PowerPoint, PDF, open document) - Mime type of request must be 'multipart/form-data' |
filterNestedConcepts | Boolean | false | Remove concepts matches which are contained within other matches, default = true |
findPersonNames | Boolean | false | Deprecated (use nerParameters) - extracts person names from the given text |
language | String | false | Extraction language (en|de|es|fr|...) |
lemmatization | Boolean | false | Use lemmatization, default = true |
locationExtraction | Boolean | false | Deprecated (use nerParameters) - extracts locations from the given text |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
phraseLength | Integer | false | Phrase length, default = 4 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Furthermore it supports http://www.w3.org/1999/02/22-rdf-syntax-ns#type. Set to all to fetch all properties. |
regexFilename | String | false | File name for regex patterns |
resultFilterSparql | String | false | Specify an optional SPARQL query for filtering the RDF result |
sentimentAnalysis | Boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided. |
showMatchingDetails | Boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | Boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
tfidfScoring | Boolean | false | Use TFIDF scoring, default = false |
title | String | false | Title of the document |
useRelatedConcepts | Boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | Boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | Boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | Boolean | false | Retrieve custom types for concepts, default = false |
Attribute | Type | Required | Comment |
|---|---|---|---|
property | String | false | Property |
value | String | false | Value |
{
"property" : "https://semantic-web.com/api/property#26100",
"value" : "some value"
}Attribute | Type | Required | Comment |
|---|---|---|---|
| Method | false | Method used for Named Entity Extraction. (default: MAXIMUM_ENTROPY) RULE_BASED | MAXIMUM_ENTROPY |
| String | false | Type of Named Entity Model. Pre-defined models for MAXIMUM_ENTROPY: person, organization, location |
{
"method" : "MAXIMUM_ENTROPY",
"type" : "https://semantic-web.com/api/type#3179"
}An ObjectStreamField object.
Attribute | Type | Required | Comment |
|---|---|---|---|
field | Field | false | |
name | String | false | |
offset | int | false | |
signature | String | false | |
type | Class | false | |
unshared | Boolean | false |
Click here to expand...
{
"field" : {
"genericInfo" : {
"factory" : null,
"tree" : null,
"genericType" : null
},
"declaredAnnotations" : { },
"overrideFieldAccessor" : { },
"signature" : "some signature",
"annotations" : [ 48 ],
"securityCheckCache" : { },
"slot" : 26477,
"fieldAccessor" : { },
"modifiers" : 24139,
"type" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 32463,
"enumConstantDirectory" : { },
"classRedefinedCount" : 22746,
"initted" : false,
"cachedConstructor" : null,
"useCaches" : true,
"SYNTHETIC" : 27448,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null ],
"serialVersionUID" : 10320,
"ANNOTATION" : 14968,
"enumConstants" : [ null, null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
},
"ACCESS_PERMISSION" : {
"serialVersionUID" : 26505,
"name" : "some name"
},
"root" : {
"genericInfo" : null,
"declaredAnnotations" : { },
"overrideFieldAccessor" : null,
"signature" : "some signature",
"annotations" : [ 119, 46, 76 ],
"securityCheckCache" : null,
"slot" : 5243,
"fieldAccessor" : null,
"modifiers" : 32720,
"type" : null,
"ACCESS_PERMISSION" : null,
"root" : null,
"name" : "some name",
"override" : false,
"reflectionFactory" : null,
"clazz" : null
},
"name" : "some name",
"override" : true,
"reflectionFactory" : {
"inflationThreshold" : 19524,
"initted" : true,
"soleInstance" : null,
"reflectionFactoryAccessPerm" : null,
"langReflectAccess" : null,
"noInflation" : false
},
"clazz" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 14462,
"enumConstantDirectory" : { },
"classRedefinedCount" : 26901,
"initted" : true,
"cachedConstructor" : null,
"useCaches" : true,
"SYNTHETIC" : 15733,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null ],
"serialVersionUID" : 1996,
"ANNOTATION" : 14537,
"enumConstants" : [ null, null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
}
},
"offset" : 8626,
"signature" : "some signature",
"unshared" : false,
"name" : "some name",
"type" : {
"annotationData" : {
"declaredAnnotations" : { },
"redefinedCount" : 4678,
"annotations" : { }
},
"genericInfo" : {
"factory" : null,
"superclass" : null,
"tree" : null,
"typeParams" : [ null, null, null ],
"NONE" : null,
"superInterfaces" : [ null, null, null ]
},
"ENUM" : 4825,
"enumConstantDirectory" : { },
"classRedefinedCount" : 19620,
"initted" : true,
"cachedConstructor" : {
"genericInfo" : null,
"declaredAnnotations" : { },
"hasRealParameterData" : false,
"parameterTypes" : [ null, null ],
"signature" : "some signature",
"annotations" : [ 0, 59 ],
"securityCheckCache" : null,
"constructorAccessor" : null,
"slot" : 29100,
"modifiers" : 9877,
"ACCESS_PERMISSION" : null,
"exceptionTypes" : [ null ],
"root" : null,
"override" : false,
"parameterAnnotations" : [ 74, 86 ],
"reflectionFactory" : null,
"clazz" : null,
"parameters" : [ null, null ]
},
"useCaches" : false,
"SYNTHETIC" : 24161,
"annotationType" : {
"inherited" : false,
"members" : { },
"memberDefaults" : { },
"$assertionsDisabled" : false,
"memberTypes" : { },
"retention" : "RUNTIME"
},
"newInstanceCallerCache" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 1033,
"enumConstantDirectory" : { },
"classRedefinedCount" : 10123,
"initted" : false,
"cachedConstructor" : null,
"useCaches" : false,
"SYNTHETIC" : 6635,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null, null ],
"serialVersionUID" : 6521,
"ANNOTATION" : 26847,
"enumConstants" : [ null, null, null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
},
"reflectionData" : {
"next" : null,
"discovered" : null,
"referent" : null,
"pending" : null,
"lock" : null,
"clock" : 24478,
"queue" : null,
"timestamp" : 16613
},
"classValueMap" : { },
"serialPersistentFields" : [ {
"field" : null,
"offset" : 22640,
"signature" : "some signature",
"unshared" : true,
"name" : "some name",
"type" : null
}, {
"field" : null,
"offset" : 23255,
"signature" : "some signature",
"unshared" : false,
"name" : "some name",
"type" : null
} ],
"serialVersionUID" : 20269,
"ANNOTATION" : 24004,
"enumConstants" : [ { }, { } ],
"name" : "some name",
"reflectionFactory" : {
"inflationThreshold" : 17765,
"initted" : true,
"soleInstance" : null,
"reflectionFactoryAccessPerm" : null,
"langReflectAccess" : null,
"noInflation" : true
},
"allPermDomain" : {
"staticPermissions" : false,
"debug" : null,
"hasAllPerm" : false,
"codesource" : null,
"permissions" : null,
"classloader" : null,
"principals" : [ null, null ],
"key" : null
}
}
}text/plain
Status: 200 - OK
Write PoolParty Extractor Results Into a Graph Database
Write PoolParty Extractor Results Into a Graph Database
When a graph database is configured as remote repository then this service can be used to annotate documents and write the results directly into the graph database.
Method: annotateAndStore
URL:
/extractor/api/annotate/store
This API call accepts plain text, a web page referenced by an URL, and an uploaded file as input.
Supported Methods |
|---|
GET |
POST |
Parameter | Type | Required | Value range | Comment |
|---|---|---|---|---|
text | String | true | The text to be used for the extraction request. | |
title | String | false | The title of the document. |
Supported Methods |
|---|
GET |
POST |
Parameter | Type | Required | Value range | Comment |
|---|---|---|---|---|
url | String | true | The Url to the document be used for the extraction request. |
Supported Methods |
|---|
POST |
The Mimetype of request must be 'multipart/form-data'.
Parameter | Type | Required | Value range | Comment |
|---|---|---|---|---|
file | MultipartFile | true | The file to be uploaded for the extraction request. Supported input formats are Word, Excel, Powerpoint, Pdf, Open Document Format. |
Parameter | Type | Required | Value range | Comment |
|---|---|---|---|---|
projectId | String | true | The unique identifier of the PoolParty project to use for the extraction (the UUID of the project e.g. "d06bd0f8-03e4-45e0-8683-fed428fca242") | |
text | String | true | The text to be used for the extraction request. | |
documentUri | String | true | A URI to identify the document. | |
graphName | String | false | The URI of the graph in the graph database where the results should be written to. If not specified a new graph with the name of the document will be created. | |
language | String | true | The language of the text (e.g. "en", "de", "es", "fr", ...). NoteA stop word list is only available for the following languages: en (english), de (german), fr (french). Other languages can be added on demand. CJK languages are not supported. | |
transitiveBroaderConcepts | boolean | false |
| Retrieve transitive broader concepts.
Depending on the depth of the thesaurus hierarchy this option can return a large number of transitive broaders per concept. Only set this parameter to |
transitiveBroaderTopConcepts | boolean | false |
| Retrieve transitive broader top concepts.
|
relatedConcepts | boolean | false |
| Retrieve related concepts.
|
numberOfConcepts | Integer | false | The number of concepts to be retrieved. | |
numberOfTerms | Integer | false | The number of terms to be retrieved. |
This service generates an RDF graph of for the results in the same way as the annotate service that is written into the installed graph database. A document URI has to be specified for each document that is used to identify the documents in the store. If a graph name is provided the results are written to that graph (useful if one processes document sets). If not graph name is provided the results for each document are written into a separate graph based on the document URI.
Web Service Method: Annotate and Store from URL
Web Service Method: Annotate and Store from URL
Description |
|---|
[url] Annotates the document from the url with extracted concepts and stores it in the remote repository. |
URL: /extractor/api/annotate/store
Supported Methods |
|---|
POST |
Content-Type: application/json
This method returns execution results in JSON format.
Parameter | Description | Type | Required |
|---|---|---|---|
url | Url to document be annotated | String | true |
language | Language of text (en|de|es|fr|...) | String | false |
documentUri | Internal ID of the document | String | true |
graphName | The name of the graph in the remote repository the PPX results gets written to | String | false |
projectIds | Thesaurus projectIds | String | false |
conceptSchemeFilters | Concept scheme filters | String | false |
customClassFilters | Custom class filters | String | false |
numberOfTerms | Number of terms to return | Integer | false |
numberOfConcepts | Number of concepts to return | Integer | false |
conceptMinimumScore | Minimum required score of concepts, default = 0 | Double | false |
useTransitiveBroaderConcepts | Retrieve transitive broader concepts of the extracted concepts, default = false | Boolean | false |
useTransitiveBroaderTopConcepts | Retrieve transitive broader top concepts of the extracted concepts, default = false | Boolean | false |
useRelatedConcepts | Retrieve related concepts of the extracted concepts, default = false | Boolean | false |
disambiguate | Use thesaurus based disambiguation, default = false | boolean | false |
useTypes | Retrieve the custom types for concepts, default = false | boolean | false |
tfidfScoring | Use tfidf scoring, default = false | boolean | false |
corpusScoring | Adapt the document scores with the corpus analysis. Enabled if corpusId (uuid) is provided, default = disabled | String | false |
properties | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Set to all to fetch all properties. | String | false |
phraseLength | Phrase length, default = 4 | Integer | false |
Web Service Method: Annotate from Text
Web Service Method: Annotate from Text
Description |
|---|
[text] Returns the document annotated with extracted concepts and extracted terms in RDF/XML representation. |
URL: /extractor/api/annotate
Supported Methods |
|---|
POST |
GET |
Content-Type: application/x-www-form-urlencoded
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptMinimumScore | Double | false | Minimum required score of concepts, default = 0 |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided. |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document, taken from documentUri |
documentUri | String | true | URI of annotated document, used as ID |
extraConceptLanguages | Array of PPLocale | false | Additional languages used for concept extraction (en|de|es|fr|...) |
extractorVersion | String | false | Version of PPX Extractor used |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = true |
findPersonNames | boolean | false | Deprecated (use nerParameters) - extracts person names from the given text |
language | PPLocale | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Deprecated (use nerParameters) - extracts locations from the given text |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
phraseLength | Integer | false | Phrase length, default = 4 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Furthermore it supports http://www.w3.org/1999/02/22-rdf-syntax-ns#type. Set to all to fetch all properties. |
regexFilename | String | false | File name for regex patterns |
resultFilterSparql | String | false | Specify an optional SPARQL query for filtering the RDF result |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided. |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
text | String | true | Text of the document |
tfidfScoring | boolean | false | Use TFIDF scoring, default = false |
title | String | false | Title of the document |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
CASE_INSENSITIVE_ORDER | Comparator | false | |
hash | int | false | |
serialPersistentFields | Array of ObjectStreamField | false | |
serialVersionUID | long | false | |
value | Array of char | false |
Attribute | Type | Required | Comment |
|---|---|---|---|
property | String | false | Property |
value | String | false | Value |
{
"property" : "https://semantic-web.com/api/property#30874",
"value" : "some value"
}Named Entity Recognition configuration
Attribute | Type | Required | Comment |
|---|---|---|---|
method | Method | false | Method used for Named Entity Extraction. (default: MAXIMUM_ENTROPY) RULE_BASED | MAXIMUM_ENTROPY |
type | String | false | Type of Named Entity Model. Pre-defined models for MAXIMUM_ENTROPY: person, organization, location |
{
"method" : "MAXIMUM_ENTROPY",
"type" : "https://semantic-web.com/api/type#16216"
}Attribute | Type | Required | Comment |
|---|---|---|---|
field | Field | false | |
name | String | false | |
offset | int | false | |
signature | String | false | |
type | Class | false | |
unshared | boolean | false |
Click here to expand...
{
"field" : {
"genericInfo" : {
"factory" : null,
"tree" : null,
"genericType" : null
},
"declaredAnnotations" : { },
"overrideFieldAccessor" : { },
"signature" : "some signature",
"annotations" : [ 54, 99 ],
"securityCheckCache" : { },
"slot" : 7232,
"fieldAccessor" : { },
"modifiers" : 9075,
"type" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 10078,
"enumConstantDirectory" : { },
"classRedefinedCount" : 31375,
"initted" : false,
"cachedConstructor" : null,
"useCaches" : false,
"SYNTHETIC" : 4809,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null ],
"serialVersionUID" : 24960,
"ANNOTATION" : 32249,
"enumConstants" : [ null, null, null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
},
"ACCESS_PERMISSION" : {
"serialVersionUID" : 17792,
"name" : "some name"
},
"root" : {
"genericInfo" : null,
"declaredAnnotations" : { },
"overrideFieldAccessor" : null,
"signature" : "some signature",
"annotations" : [ 44 ],
"securityCheckCache" : null,
"slot" : 1259,
"fieldAccessor" : null,
"modifiers" : 15456,
"type" : null,
"ACCESS_PERMISSION" : null,
"root" : null,
"name" : "some name",
"override" : true,
"reflectionFactory" : null,
"clazz" : null
},
"name" : "some name",
"override" : true,
"reflectionFactory" : {
"inflationThreshold" : 16638,
"initted" : true,
"soleInstance" : null,
"reflectionFactoryAccessPerm" : null,
"langReflectAccess" : null,
"noInflation" : true
},
"clazz" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 30901,
"enumConstantDirectory" : { },
"classRedefinedCount" : 13157,
"initted" : false,
"cachedConstructor" : null,
"useCaches" : true,
"SYNTHETIC" : 18792,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null ],
"serialVersionUID" : 7011,
"ANNOTATION" : 3943,
"enumConstants" : [ null, null, null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
}
},
"offset" : 7713,
"signature" : "some signature",
"unshared" : false,
"name" : "some name",
"type" : {
"annotationData" : {
"declaredAnnotations" : { },
"redefinedCount" : 9363,
"annotations" : { }
},
"genericInfo" : {
"factory" : null,
"superclass" : null,
"tree" : null,
"typeParams" : [ null, null ],
"NONE" : null,
"superInterfaces" : [ null, null ]
},
"ENUM" : 10784,
"enumConstantDirectory" : { },
"classRedefinedCount" : 11824,
"initted" : true,
"cachedConstructor" : {
"genericInfo" : null,
"declaredAnnotations" : { },
"hasRealParameterData" : true,
"parameterTypes" : [ null, null, null ],
"signature" : "some signature",
"annotations" : [ 85, 4, 110 ],
"securityCheckCache" : null,
"constructorAccessor" : null,
"slot" : 20713,
"modifiers" : 7871,
"ACCESS_PERMISSION" : null,
"exceptionTypes" : [ null, null, null ],
"root" : null,
"override" : false,
"parameterAnnotations" : [ 42 ],
"reflectionFactory" : null,
"clazz" : null,
"parameters" : [ null, null ]
},
"useCaches" : true,
"SYNTHETIC" : 5209,
"annotationType" : {
"inherited" : true,
"members" : { },
"memberDefaults" : { },
"$assertionsDisabled" : true,
"memberTypes" : { },
"retention" : "SOURCE"
},
"newInstanceCallerCache" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 139,
"enumConstantDirectory" : { },
"classRedefinedCount" : 12963,
"initted" : true,
"cachedConstructor" : null,
"useCaches" : true,
"SYNTHETIC" : 23823,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null, null ],
"serialVersionUID" : 10600,
"ANNOTATION" : 1872,
"enumConstants" : [ null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
},
"reflectionData" : {
"next" : null,
"discovered" : null,
"referent" : null,
"pending" : null,
"lock" : null,
"clock" : 31429,
"queue" : null,
"timestamp" : 5262
},
"classValueMap" : { },
"serialPersistentFields" : [ {
"field" : null,
"offset" : 18525,
"signature" : "some signature",
"unshared" : true,
"name" : "some name",
"type" : null
}, {
"field" : null,
"offset" : 6141,
"signature" : "some signature",
"unshared" : true,
"name" : "some name",
"type" : null
} ],
"serialVersionUID" : 7640,
"ANNOTATION" : 16250,
"enumConstants" : [ { }, { }, { } ],
"name" : "some name",
"reflectionFactory" : {
"inflationThreshold" : 19353,
"initted" : false,
"soleInstance" : null,
"reflectionFactoryAccessPerm" : null,
"langReflectAccess" : null,
"noInflation" : false
},
"allPermDomain" : {
"staticPermissions" : true,
"debug" : null,
"hasAllPerm" : true,
"codesource" : null,
"permissions" : null,
"classloader" : null,
"principals" : [ null, null ],
"key" : null
}
}
}Content-type: text/plain
Status: 200 - Ok
You can now manipulate the response format to any RDF format, as also defined here: http://docs.rdf4j.org/javadoc/2.3/org/eclipse/rdf4j/rio/RDFFormat.html
application/rdf+xml
application/n-triples
application/x-turtle
application/trix
application/trig
In order to configure the response format, use an additional Accept header in your call.
Using an HTTP REST client, such as Postman, the call would look like this:
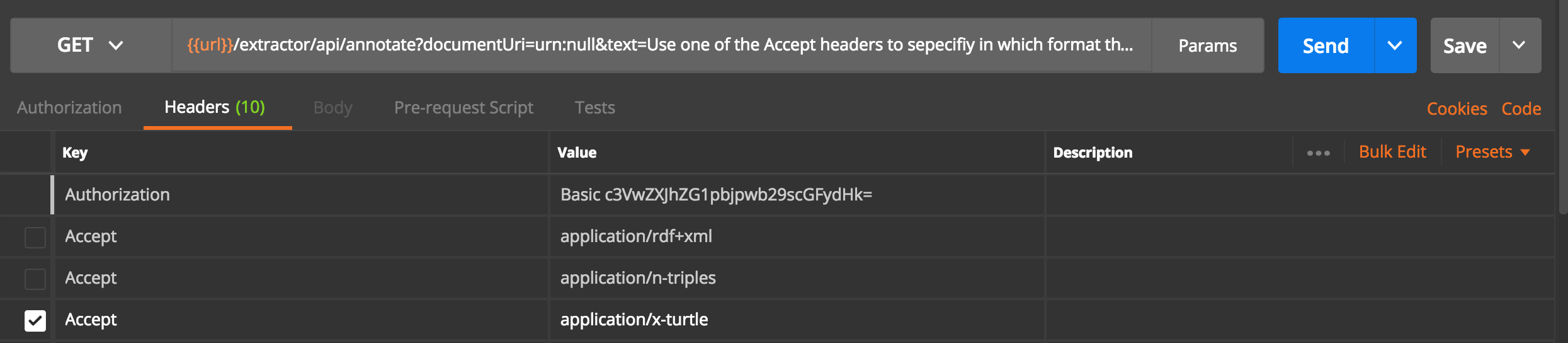 |
Get Extraction Results as RDF
Get Extraction Results as RDF
To obtain the extraction results as an RDF document use the PoolParty Extractor 'annotate' service. It expects the same parameters as the 'extract' services but returns the results as RDF/XML.
The only difference is that the parameter 'documentId' is required because it is part of the RDF results.
URL: /extractor/api/annotate
This API call accepts plain text, a web page referenced by a URL, and an uploaded file as input.
Supported Methods |
|---|
GET |
POST |
Parameter | Type | Required | Value range | Comment |
|---|---|---|---|---|
text | String | true | The text to be used for the extraction request. | |
title | String | false | The title of the document. |
Supported Methods |
|---|
GET |
POST |
Parameter | Type | Required | Value range | Comment |
|---|---|---|---|---|
url | String | true | The Url to the document be used for the extraction request. |
Supported Methods |
|---|
POST |
The Mimetype of request must be 'multipart/form-data'.
Parameter | Type | Required | Value range | Comment |
|---|---|---|---|---|
file | MultipartFile | true | The file to be uploaded for the extraction request. Supported input formats are Word, Excel, Powerpoint, Pdf, Open Document Format. |
The parameters are very similar to the /api/extract call (see Concept Extraction Service for more details).
Parameter | Type | Required | Value range | Comment |
|---|---|---|---|---|
text | String | true | ||
language | String | true | ||
documentUri | String | true | The URI that will be used in the RDF output of the method. | |
projectId | String | false | ||
numberOfConcepts | Integer | false | ||
numberOfTerms | Integer | false | ||
useTransitiveBroaderConcepts | Boolean | false | ||
useTransitiveBroaderTopConcepts | Boolean | false | ||
useRelatedConcepts | Boolean | false |
A simple example with a text of just one word would look like this:
http://test.semantic-web.at/extractor/api/annotate?projectId=1DAB156D-F01F-0001-ABCE-16301D4023C0&language=en&text=Aspirin&documentUri=SWC:1
<rdf:RDF>
<rdf:Description rdf:about="SWC:1">
<ctag:tagged rdf:resource="ppx:98838d58-3650-4c10-8b60-896a663cdca8"/>
</rdf:Description>
<rdf:Description rdf:about="ppx:98838d58-3650-4c10-8b60-896a663cdca8">
<ctag:label xml:lang="en">Aspirin</ctag:label>
<ctag:means rdf:resource="http://www.nlm.nih.gov/mesh/D001241"/>
<rdf:type rdf:resource="http://commontag.org/ns#AutoTag"/>
</rdf:Description>
<rdf:Description rdf:about="http://www.nlm.nih.gov/mesh/D001241">
<ppx:score rdf:datatype="http://www.w3.org/2001/XMLSchema#long">100</ppx:score>
<skos:altLabel xml:lang="en">Micristin</skos:altLabel>
<skos:altLabel xml:lang="en">Polopirin</skos:altLabel>
<skos:altLabel xml:lang="en">Magnecyl</skos:altLabel>
<skos:altLabel xml:lang="en">Zorprin</skos:altLabel>
<skos:altLabel xml:lang="en">Ecotrin</skos:altLabel>
<skos:altLabel xml:lang="en">Solupsan</skos:altLabel>
<skos:altLabel xml:lang="en">Acetylsalicylic Acid</skos:altLabel>
<skos:altLabel xml:lang="en">Solprin</skos:altLabel>
<skos:altLabel xml:lang="en">Dispril</skos:altLabel>
<skos:altLabel xml:lang="en">Acid, Acetylsalicylic</skos:altLabel>
<skos:altLabel xml:lang="en">Aloxiprimum</skos:altLabel>
<skos:altLabel xml:lang="en">Endosprin</skos:altLabel>
<skos:altLabel xml:lang="en">2-(Acetyloxy)benzoic Acid</skos:altLabel>
<skos:altLabel xml:lang="en">Easprin</skos:altLabel>
<skos:altLabel xml:lang="en">Polopiryna</skos:altLabel>
<skos:altLabel xml:lang="en">Acetysal</skos:altLabel>
<skos:altLabel xml:lang="en">Colfarit</skos:altLabel>
<skos:altLabel xml:lang="en">Acylpyrin</skos:altLabel>
<skos:inScheme rdf:resource="http://www.nlm.nih.gov/mesh/Chemicals_and_Drugs"/>
</rdf:Description>
<rdf:Description rdf:about="ppx:98838d58-3650-4c10-8b60-896a663cdca8">
<ctag:taggingDate>Wed Nov 20 14:33:29 CET 2013</ctag:taggingDate>
</rdf:Description>
</rdf:RDF>The result contains 3 types of resources. The document, the tagging events, and the description of the annotated concepts. The document links to the tagging events (predicate 'ctag:tagged') that contain the label (the 'skos:prefLabel' of the concept) and link themselves to the information about the annotated concept (predicate 'ctag:means').
Web Service Method: Annotate from Text using JSON
Description |
|---|
[text] Returns the document annotated with extracted concepts and extracted terms in RDF/XML representation. |
URL: /extractor/api/annotate/text
Supported Methods |
|---|
POST |
Content-Type: application/json
Parameter | Type | Required | Description |
|---|---|---|---|
CASE_INSENSITIVE_ORDER | Comparator | false | |
hash | int | false | |
serialPersistentFields | Array of ObjectStreamField | false | |
serialVersionUID | long | false | |
value | Array of char | false | |
SC_ACCEPTED | int | false | |
SC_BAD_GATEWAY | int | false | |
SC_BAD_REQUEST | int | false | |
SC_CONFLICT | int | false | |
SC_CONTINUE | int | false | |
SC_CREATED | int | false | |
SC_EXPECTATION_FAILED | int | false | |
SC_FORBIDDEN | int | false | |
SC_FOUND | int | false | |
SC_GATEWAY_TIMEOUT | int | false | |
SC_GONE | int | false | |
SC_HTTP_VERSION_NOT_SUPPORTED | int | false | |
SC_INTERNAL_SERVER_ERROR | int | false | |
SC_LENGTH_REQUIRED | int | false | |
SC_METHOD_NOT_ALLOWED | int | false | |
SC_MOVED_PERMANENTLY | int | false | |
SC_MOVED_TEMPORARILY | int | false | |
SC_MULTIPLE_CHOICES | int | false | |
SC_NON_AUTHORITATIVE_INFORMATION | int | false | |
SC_NOT_ACCEPTABLE | int | false | |
SC_NOT_FOUND | int | false | |
SC_NOT_IMPLEMENTED | int | false | |
SC_NOT_MODIFIED | int | false | |
SC_NO_CONTENT | int | false | |
SC_OK | int | false | |
SC_PARTIAL_CONTENT | int | false | |
SC_PAYMENT_REQUIRED | int | false | |
SC_PRECONDITION_FAILED | int | false | |
SC_PROXY_AUTHENTICATION_REQUIRED | int | false | |
SC_REQUESTED_RANGE_NOT_SATISFIABLE | int | false | |
SC_REQUEST_ENTITY_TOO_LARGE | int | false | |
SC_REQUEST_TIMEOUT | int | false | |
SC_REQUEST_URI_TOO_LONG | int | false | |
SC_RESET_CONTENT | int | false | |
SC_SEE_OTHER | int | false | |
SC_SERVICE_UNAVAILABLE | int | false | |
SC_SWITCHING_PROTOCOLS | int | false | |
SC_TEMPORARY_REDIRECT | int | false | |
SC_UNAUTHORIZED | int | false | |
SC_UNSUPPORTED_MEDIA_TYPE | int | false | |
SC_USE_PROXY | int | false |
TextAnnotateRequest
Annotation request
Attribute | Type | Required | Comment |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptMinimumScore | Double | false | Minimum required score of concepts, default = 0 |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided. |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document, taken from documentUri |
documentUri | String | true | URI of annotated document, used as ID |
extractorVersion | String | false | Version of PPX Extractor used |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = true |
findPersonNames | boolean | false | Deprecated (use nerParameters) - extracts person names from the given text |
language | String | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Deprecated (use nerParameters) - extracts locations from the given text |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
phraseLength | Integer | false | Phrase length, default = 4 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Set to all to fetch all properties. |
regexFilename | String | false | File name for regex patterns |
resultFilterSparql | String | false | Specify an optional SPARQL query for filtering the RDF result |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided. |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
text | String | true | Text of the document |
tfidfScoring | boolean | false | Use TFIDF scoring, default = false |
title | String | false | Title of the document |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
A Comparator object.
Attribute | Type | Required | Comment |
|---|
Example
{ }
An ObjectStreamField object.
Attribute | Type | Required | Comment |
|---|---|---|---|
field | Field | false | |
name | String | false | |
offset | int | false | |
signature | String | false | |
type | Class | false | |
unshared | boolean | false |
Web Service Method: Annotate from Text in NIF Format
Web Service Method: Annotate from Text in NIF Format
Description |
|---|
[text] Returns the document annotated with extracted concepts and extracted terms in NIF format. |
URL: /extractor/api/annotate/nif
Supported Methods |
|---|
POST |
GET |
Content-Type: application/x-www-form-urlencoded
Parameter | Type | Required | Description |
|---|---|---|---|
includeConcepts | boolean | false | |
includeNamedEntities | boolean | false | |
includeTerms | boolean | false | |
informat | String | false | The format in which the input will be processed: text (default) |
input | String | true | The input to be processed by the service |
intype | String | false | Determines how input is accessed or retrieved: direct (default) | url |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition |
outformat | String | false | The format in which the output will be serialized: turtle (default) | text | json-ld | rdfxml | ntriples | rdfa |
phraseLength | Interger | false | Phrase length, default = 4 |
prefix | String | true | The prefix part of new URIs |
projectId | Array of String | true | Thesaurus projectId |
Named Entity Recognition configuration
Attribute | Type | Required | Comment |
|---|---|---|---|
method | Method | false | Method used for Named Entity Extraction. (default: MAXIMUM_ENTROPY) RULE_BASED | MAXIMUM_ENTROPY |
type | String | false | Type of Named Entity Model. Pre-defined models for MAXIMUM_ENTROPY: person, organization, location |
{
"method" : "RULE_BASED",
"type" : "https://semantic-web.com/api/type#28577"
}Content-type: text/plain
Status: 200 - Ok
You can now manipulate the response format to any RDF format, as also defined here: http://docs.rdf4j.org/javadoc/2.3/org/eclipse/rdf4j/rio/RDFFormat.html
application/rdf+xml
application/n-triples
application/x-turtle
application/trix
application/trig
In order to configure the response format, use an additional Accept header in your call.
Using an HTTP REST client, such as Postman, the call would look like this:
|
Web Service Method: Annotate from Text in NIF Format in JSON
Web Service Method: Annotate from Text in NIF Format in JSON
Description |
|---|
[text] Returns the document annotated with extracted concepts and extracted terms in NIF format. |
URL: /extractor/api/annotate/nif
Supported Methods |
|---|
POST |
Content-Type: application/json
Attribute | Type | Required | Comment |
|---|---|---|---|
includeConcepts | boolean | false | |
includeNamedEntities | boolean | false | |
includeTerms | boolean | false | |
informat | String | false | The format in which the input will be processed: text (default) |
input | String | true | The input to be processed by the service |
intype | String | false | Determines how input is accessed or retrieved: direct (default) | url |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition |
outformat | String | false | The format in which the output will be serialized: turtle (default) | text | json-ld | rdfxml | ntriples | rdfa |
phraseLength | Integer | false | Phrase length, default = 4 |
prefix | String | true | The prefix part of new URIs |
projectId | Array of String | true | Thesaurus projectId |
Named Entity Recognition configuration
Attribute | Type | Required | Comment |
|---|---|---|---|
method | Method | false | Method used for Named Entity Extraction. (default: MAXIMUM_ENTROPY) RULE_BASED | MAXIMUM_ENTROPY |
type | String | false | Type of Named Entity Model. Pre-defined models for MAXIMUM_ENTROPY: person, organization, location |
{
"input" : "some input",
"nerParameters" : [ {
"method" : "MAXIMUM_ENTROPY",
"type" : "https://semantic-web.com/api/type#10113"
}, {
"method" : "RULE_BASED",
"type" : "https://semantic-web.com/api/type#491"
}, {
"method" : "MAXIMUM_ENTROPY",
"type" : "https://semantic-web.com/api/type#16327"
} ],
"informat" : "some informat",
"prefix" : "some prefix",
"includeTerms" : false,
"includeNamedEntities" : true,
"includeConcepts" : false,
"outformat" : "some outformat",
"projectId" : [ "some projectId", "some projectId" ],
"intype" : "some intype"
}Content-type: text/plain
Status: 200 - Ok
You can now manipulate the response format to any RDF format, as also defined here: http://docs.rdf4j.org/javadoc/2.3/org/eclipse/rdf4j/rio/RDFFormat.html
application/rdf+xml
application/n-triples
application/x-turtle
application/trix
application/trig
In order to configure the response format, use an additional Accept header in your call.
Using an HTTP REST client, such as Postman, the call would look like this:
|
Web Service Method: Annotate from File
Web Service Method: Annotate from File
Description |
|---|
[file] Returns the document annotated with extracted concepts and extracted terms in RDF/XML representation. |
URL: /extractor/api/annotate
Supported Methods |
|---|
POST |
Content-Type: multipart/form-data
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptMinimumScore | Double | false | Minimum required score of concepts, default = 0 |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided. |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document, taken from documentUri |
documentUri | String | true | URI of annotated document, used as ID |
extractorVersion | String | false | Version of PPX Extractor used |
file | MultipartFile | true | File to be annotated (word, excel, powerpoint, pdf, open document) - Mime type of request must be 'multipart/form-data' |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = true |
findPersonNames | boolean | false | Deprecated (use nerParameters) - extracts person names from the given text |
language | String | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Deprecated (use nerParameters) - extracts locations from the given text |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
phraseLength | Integer | false | Phrase length, default = 4 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Furthermore it supports http://www.w3.org/1999/02/22-rdf-syntax-ns#type. Set to all to fetch all properties. |
regexFilename | String | false | File name for regex patterns |
resultFilterSparql | String | false | Specify an optional SPARQL query for filtering the RDF result |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided. |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
tfidfScoring | boolean | false | Use TFIDF scoring, default = false |
title | String | false | Title of the document |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
Attribute | Type | Required | Comment |
|---|---|---|---|
property | String | false | Property |
value | String | false | Value |
{
"property" : "https://semantic-web.com/api/property#6376",
"value" : "some value"
}Attribute | Type | Required | Comment |
|---|---|---|---|
method | Method | false | Method used for Named Entity Extraction. (default: MAXIMUM_ENTROPY) RULE_BASED | MAXIMUM_ENTROPY |
type | String | false | Type of Named Entity Model. Pre-defined models for MAXIMUM_ENTROPY: person, organization, location |
{
"method" : "RULE_BASED",
"type" : "https://semantic-web.com/api/type#20383"
}Attribute | Type | Required | Comment |
|---|---|---|---|
field | Field | false | |
name | String | false | |
offset | int | false | |
signature | String | false | |
type | Class | false | |
unshared | boolean | false |
{
"field" : {
"genericInfo" : {
"factory" : null,
"tree" : null,
"genericType" : null
},
"declaredAnnotations" : { },
"overrideFieldAccessor" : { },
"signature" : "some signature",
"annotations" : [ 23 ],
"securityCheckCache" : { },
"slot" : 4350,
"fieldAccessor" : { },
"modifiers" : 27639,
"type" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 2479,
"enumConstantDirectory" : { },
"classRedefinedCount" : 17528,
"initted" : false,
"cachedConstructor" : null,
"useCaches" : true,
"SYNTHETIC" : 28542,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null, null ],
"serialVersionUID" : 19423,
"ANNOTATION" : 2206,
"enumConstants" : [ null, null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
},
"ACCESS_PERMISSION" : {
"serialVersionUID" : 23155,
"name" : "some name"
},
"root" : {
"genericInfo" : null,
"declaredAnnotations" : { },
"overrideFieldAccessor" : null,
"signature" : "some signature",
"annotations" : [ 87, 51 ],
"securityCheckCache" : null,
"slot" : 18207,
"fieldAccessor" : null,
"modifiers" : 24703,
"type" : null,
"ACCESS_PERMISSION" : null,
"root" : null,
"name" : "some name",
"override" : true,
"reflectionFactory" : null,
"clazz" : null
},
"name" : "some name",
"override" : true,
"reflectionFactory" : {
"inflationThreshold" : 28477,
"initted" : false,
"soleInstance" : null,
"reflectionFactoryAccessPerm" : null,
"langReflectAccess" : null,
"noInflation" : false
},
"clazz" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 30581,
"enumConstantDirectory" : { },
"classRedefinedCount" : 12111,
"initted" : false,
"cachedConstructor" : null,
"useCaches" : true,
"SYNTHETIC" : 27304,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null ],
"serialVersionUID" : 24089,
"ANNOTATION" : 3326,
"enumConstants" : [ null, null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
}
},
"offset" : 11522,
"signature" : "some signature",
"unshared" : false,
"name" : "some name",
"type" : {
"annotationData" : {
"declaredAnnotations" : { },
"redefinedCount" : 11463,
"annotations" : { }
},
"genericInfo" : {
"factory" : null,
"superclass" : null,
"tree" : null,
"typeParams" : [ null, null, null ],
"NONE" : null,
"superInterfaces" : [ null, null ]
},
"ENUM" : 2206,
"enumConstantDirectory" : { },
"classRedefinedCount" : 8783,
"initted" : false,
"cachedConstructor" : {
"genericInfo" : null,
"declaredAnnotations" : { },
"hasRealParameterData" : false,
"parameterTypes" : [ null, null ],
"signature" : "some signature",
"annotations" : [ 30 ],
"securityCheckCache" : null,
"constructorAccessor" : null,
"slot" : 25006,
"modifiers" : 3408,
"ACCESS_PERMISSION" : null,
"exceptionTypes" : [ null ],
"root" : null,
"override" : false,
"parameterAnnotations" : [ 71, 121 ],
"reflectionFactory" : null,
"clazz" : null,
"parameters" : [ null ]
},
"useCaches" : true,
"SYNTHETIC" : 7276,
"annotationType" : {
"inherited" : true,
"members" : { },
"memberDefaults" : { },
"$assertionsDisabled" : false,
"memberTypes" : { },
"retention" : "RUNTIME"
},
"newInstanceCallerCache" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 30429,
"enumConstantDirectory" : { },
"classRedefinedCount" : 13473,
"initted" : true,
"cachedConstructor" : null,
"useCaches" : true,
"SYNTHETIC" : 5278,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null, null ],
"serialVersionUID" : 18766,
"ANNOTATION" : 3482,
"enumConstants" : [ null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
},
"reflectionData" : {
"next" : null,
"discovered" : null,
"referent" : null,
"pending" : null,
"lock" : null,
"clock" : 1663,
"queue" : null,
"timestamp" : 29342
},
"classValueMap" : { },
"serialPersistentFields" : [ {
"field" : null,
"offset" : 20136,
"signature" : "some signature",
"unshared" : true,
"name" : "some name",
"type" : null
} ],
"serialVersionUID" : 7837,
"ANNOTATION" : 12014,
"enumConstants" : [ { }, { } ],
"name" : "some name",
"reflectionFactory" : {
"inflationThreshold" : 192,
"initted" : false,
"soleInstance" : null,
"reflectionFactoryAccessPerm" : null,
"langReflectAccess" : null,
"noInflation" : false
},
"allPermDomain" : {
"staticPermissions" : false,
"debug" : null,
"hasAllPerm" : true,
"codesource" : null,
"permissions" : null,
"classloader" : null,
"principals" : [ null, null ],
"key" : null
}
}
}This method returns execution results in format application/rdf+xml
You can now manipulate the response format to any RDF format, as also defined here: http://docs.rdf4j.org/javadoc/2.3/org/eclipse/rdf4j/rio/RDFFormat.html
application/rdf+xml
application/n-triples
application/x-turtle
application/trix
application/trig
In order to configure the response format, use an additional Accept header in your call.
Using an HTTP REST client, such as Postman, the call would look like this:
|
Web Service Method: Annotate from URL
Web Service Method: Annotate from URL
Description |
|---|
[url] Returns the document annotated with extracted concepts and extracted terms in RDF/XML representation. |
URL: /extractor/api/annotate
Supported Methods |
|---|
POST |
GET |
application/x-www-form-urlencoded
Parameter | Type | Required | Description |
|---|---|---|---|
categorizationWithPpxBoost | boolean | false | Use Extractor boosting, default = false |
categorize | boolean | false | Categorization extraction, default = false |
conceptMinimumScore | Double | false | Minimum required score of concepts, default = 0 |
conceptSchemeFilters | Array of String | false | Concept scheme URI filters |
corpusScoring | Array of String | false | Corpus term scoring. Enabled if corpusIds (UUID) are provided. |
customAttributeFilters | Array of CustomProperty | false | Custom attribute (property uri and string value) filters |
customClassFilters | Array of String | false | Custom class URI filters |
disambiguate | boolean | false | Use thesaurus based disambiguation, default = false |
displayText | boolean | false | Include text extracted from url in response, default = false |
documentClassifierIds | Array of String | false | Enable document classification by giving the document classifier IDs as input |
documentId | String | false | Internal ID of the document, taken from documentUri |
documentUri | String | true | URI of annotated document, used as ID |
extractorVersion | String | false | Version of PPX Extractor used |
filterNestedConcepts | boolean | false | Remove concepts matches which are contained within other matches, default = true |
findPersonNames | boolean | false | Deprecated (use nerParameters) - extracts person names from the given text |
language | String | false | Extraction language (en|de|es|fr|...) |
lemmatization | boolean | false | Use lemmatization, default = true |
locationExtraction | boolean | false | Deprecated (use nerParameters) - extracts locations from the given text |
nerParameters | Array of NERConfig | false | Array of models that are used for Named Entity Recognition |
numberOfConcepts | Integer | false | Retrieve number of concepts, default = 25 |
numberOfTerms | Integer | false | Retrieve number of terms, default = 25 |
phraseLength | Integer | false | Phrase length, default = 4 |
projectId | Array of String | false | Thesaurus projectIds |
properties | Array of String | false | Array of custom class attributes and relations that will be fetched by providing their property URIs as input. Furthermore it supports http://www.w3.org/1999/02/22-rdf-syntax-ns#type. Set to all to fetch all properties. |
regexFilename | String | false | File name for regex patterns |
resultFilterSparql | String | false | Specify an optional SPARQL query for filtering the RDF result |
sentimentAnalysis | boolean | false | Sentiment analysis, default: false |
shadowConceptCorpusId | Array of String | false | Shadow concepts calculation. Enabled if corpusIds (UUID) are provided. |
showMatchingDetails | boolean | false | Shows which concept labels where found inside the text, default = false |
showMatchingPosition | boolean | false | Shows the position of the matched text. Only shown if showMatchingDetails = true. default = false |
tfidfScoring | boolean | false | Use TFIDF scoring, default = false |
title | String | false | Title of the document |
url | String | true | URL of a web document to be annotated |
useRelatedConcepts | boolean | false | Retrieve related concepts, default = false |
useTransitiveBroaderConcepts | boolean | false | Retrieve transitive broader concepts, default = false |
useTransitiveBroaderTopConcepts | boolean | false | Retrieve transitive broader top concepts, default = false |
useTypes | boolean | false | Retrieve custom types for concepts, default = false |
Attribute | Type | Required | Comment |
|---|---|---|---|
property | String | false | Property |
value | String | false | Value |
{
"property" : "https://semantic-web.com/api/property#6376",
"value" : "some value"
}Named Entity Recognition Configuration
Attribute | Type | Required | Comment |
|---|---|---|---|
method | Method | false | Method used for Named Entity Extraction. (default: MAXIMUM_ENTROPY) RULE_BASED | MAXIMUM_ENTROPY |
type | String | false | Type of Named Entity Model. Pre-defined models for MAXIMUM_ENTROPY: person, organization, location |
{
"method" : "RULE_BASED",
"type" : "https://semantic-web.com/api/type#20383"
}An ObjectStreamField object.
Attribute | Type | Required | Comment |
|---|---|---|---|
field | Field | false | |
name | String | false | |
offset | int | false | |
signature | String | false | |
type | Class | false | |
unshared | boolean | false |
Click here to expand...
{
"field" : {
"genericInfo" : {
"factory" : null,
"tree" : null,
"genericType" : null
},
"declaredAnnotations" : { },
"overrideFieldAccessor" : { },
"signature" : "some signature",
"annotations" : [ 23 ],
"securityCheckCache" : { },
"slot" : 4350,
"fieldAccessor" : { },
"modifiers" : 27639,
"type" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 2479,
"enumConstantDirectory" : { },
"classRedefinedCount" : 17528,
"initted" : false,
"cachedConstructor" : null,
"useCaches" : true,
"SYNTHETIC" : 28542,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null, null ],
"serialVersionUID" : 19423,
"ANNOTATION" : 2206,
"enumConstants" : [ null, null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
},
"ACCESS_PERMISSION" : {
"serialVersionUID" : 23155,
"name" : "some name"
},
"root" : {
"genericInfo" : null,
"declaredAnnotations" : { },
"overrideFieldAccessor" : null,
"signature" : "some signature",
"annotations" : [ 87, 51 ],
"securityCheckCache" : null,
"slot" : 18207,
"fieldAccessor" : null,
"modifiers" : 24703,
"type" : null,
"ACCESS_PERMISSION" : null,
"root" : null,
"name" : "some name",
"override" : true,
"reflectionFactory" : null,
"clazz" : null
},
"name" : "some name",
"override" : true,
"reflectionFactory" : {
"inflationThreshold" : 28477,
"initted" : false,
"soleInstance" : null,
"reflectionFactoryAccessPerm" : null,
"langReflectAccess" : null,
"noInflation" : false
},
"clazz" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 30581,
"enumConstantDirectory" : { },
"classRedefinedCount" : 12111,
"initted" : false,
"cachedConstructor" : null,
"useCaches" : true,
"SYNTHETIC" : 27304,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null ],
"serialVersionUID" : 24089,
"ANNOTATION" : 3326,
"enumConstants" : [ null, null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
}
},
"offset" : 11522,
"signature" : "some signature",
"unshared" : false,
"name" : "some name",
"type" : {
"annotationData" : {
"declaredAnnotations" : { },
"redefinedCount" : 11463,
"annotations" : { }
},
"genericInfo" : {
"factory" : null,
"superclass" : null,
"tree" : null,
"typeParams" : [ null, null, null ],
"NONE" : null,
"superInterfaces" : [ null, null ]
},
"ENUM" : 2206,
"enumConstantDirectory" : { },
"classRedefinedCount" : 8783,
"initted" : false,
"cachedConstructor" : {
"genericInfo" : null,
"declaredAnnotations" : { },
"hasRealParameterData" : false,
"parameterTypes" : [ null, null ],
"signature" : "some signature",
"annotations" : [ 30 ],
"securityCheckCache" : null,
"constructorAccessor" : null,
"slot" : 25006,
"modifiers" : 3408,
"ACCESS_PERMISSION" : null,
"exceptionTypes" : [ null ],
"root" : null,
"override" : false,
"parameterAnnotations" : [ 71, 121 ],
"reflectionFactory" : null,
"clazz" : null,
"parameters" : [ null ]
},
"useCaches" : true,
"SYNTHETIC" : 7276,
"annotationType" : {
"inherited" : true,
"members" : { },
"memberDefaults" : { },
"$assertionsDisabled" : false,
"memberTypes" : { },
"retention" : "RUNTIME"
},
"newInstanceCallerCache" : {
"annotationData" : null,
"genericInfo" : null,
"ENUM" : 30429,
"enumConstantDirectory" : { },
"classRedefinedCount" : 13473,
"initted" : true,
"cachedConstructor" : null,
"useCaches" : true,
"SYNTHETIC" : 5278,
"annotationType" : null,
"newInstanceCallerCache" : null,
"reflectionData" : null,
"classValueMap" : { },
"serialPersistentFields" : [ null, null, null ],
"serialVersionUID" : 18766,
"ANNOTATION" : 3482,
"enumConstants" : [ null ],
"name" : "some name",
"reflectionFactory" : null,
"allPermDomain" : null
},
"reflectionData" : {
"next" : null,
"discovered" : null,
"referent" : null,
"pending" : null,
"lock" : null,
"clock" : 1663,
"queue" : null,
"timestamp" : 29342
},
"classValueMap" : { },
"serialPersistentFields" : [ {
"field" : null,
"offset" : 20136,
"signature" : "some signature",
"unshared" : true,
"name" : "some name",
"type" : null
} ],
"serialVersionUID" : 7837,
"ANNOTATION" : 12014,
"enumConstants" : [ { }, { } ],
"name" : "some name",
"reflectionFactory" : {
"inflationThreshold" : 192,
"initted" : false,
"soleInstance" : null,
"reflectionFactoryAccessPerm" : null,
"langReflectAccess" : null,
"noInflation" : false
},
"allPermDomain" : {
"staticPermissions" : false,
"debug" : null,
"hasAllPerm" : true,
"codesource" : null,
"permissions" : null,
"classloader" : null,
"principals" : [ null, null ],
"key" : null
}
}
}text/plain
Status: 200 - OK
This method returns execution results in format application/rdf+xml
You can now manipulate the response format to any RDF format, as also defined here: http://docs.rdf4j.org/javadoc/2.3/org/eclipse/rdf4j/rio/RDFFormat.html
application/rdf+xml
application/n-triples
application/x-turtle
application/trix
application/trig
In order to configure the response format, use an additional Accept header in your call.
Using an HTTP REST client, such as Postman, the call would look like this, according to the format you need to be returned:
|