Train a Classifier
Train a Classifier
In order to use the classifiers you created, you first have to train them. This section explains how to do it.
The following has to be in place in order for you to be able to use the classifier:
A PoolParty Enterprise Server or Semantic Integrator license with Semantic Classifier add-on included.
An opened PoolParty thesaurus project you created.
PoolParty's default machine learning algorithms represent state-of-the-art calculation models. In order to use them to advantage you have to train them manually by checking classification results and tweaking settings.
We recommend to train the classifiers until the scoring for the mean f1, as well as for recall and precision are above 70 %.
How to Train a Classifier
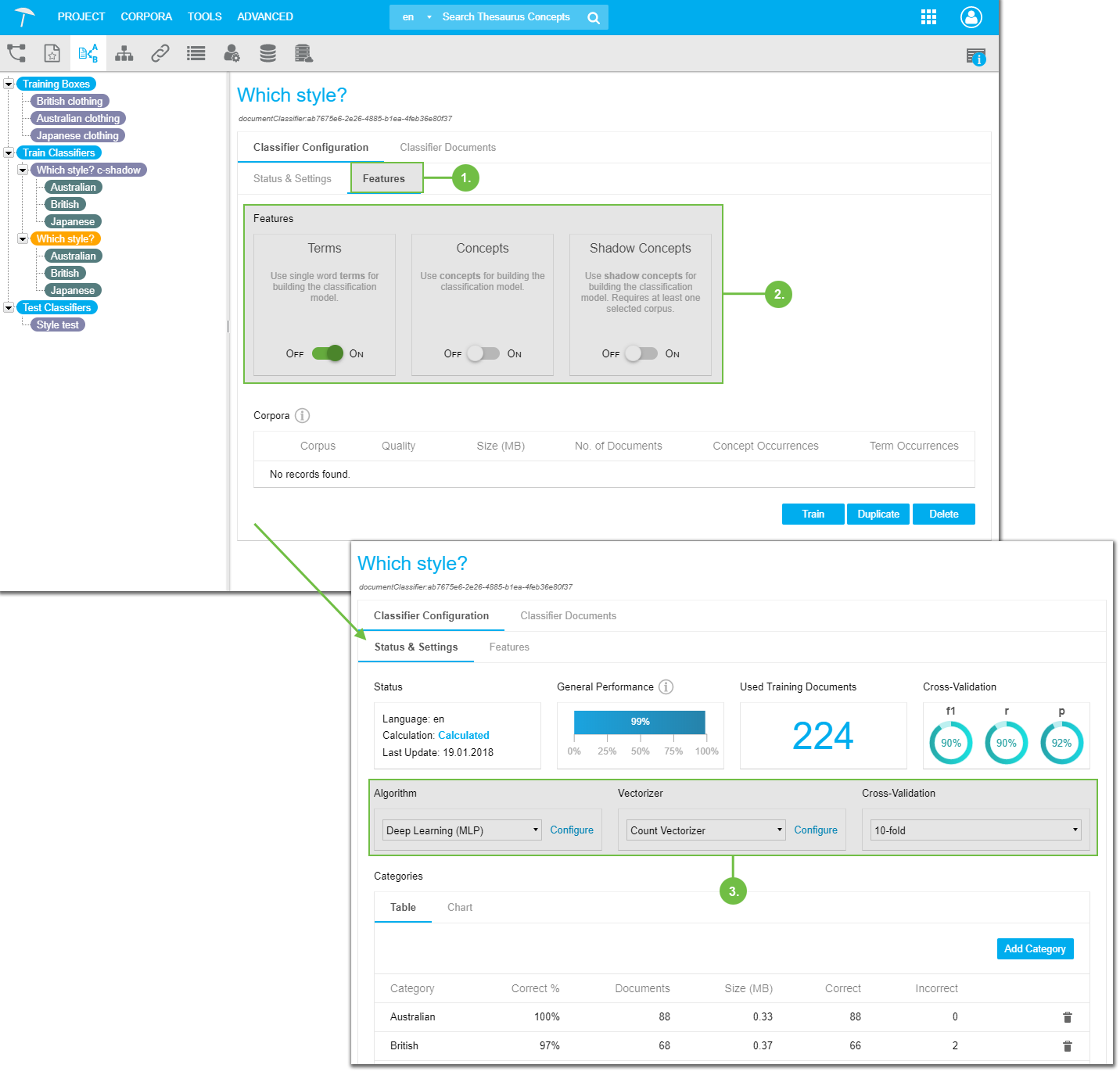
After you have created a classifier and added documents to it, choose settings in the Features tab.
You can choose which of the additional functions you want to use: include Shadow Conceptsin the calculation, the project's thesaurus as well as just single word terms.
In the Status & Settings tab select the algorithm of your choice, configure the Vectorizer and select the Cross-Validation level.
These settings, their values and their effects find explained in detail in a separate topic.
 |
For details on the training of a classifier, please refer to: Train a Classifier - Best Practices
Train a Classifier - Best Practices
Train a Classifier - Best Practices
In this section we have summarized our recommendations for training classifiers in PoolParty to get the best possible results.
You should not use more than 50 categories per classifier and an average of 50-150 documents per category. Otherwise, performance will be impeded considerably.
Create categories that fit your training documents on the one hand and your use case for this particular classifier well.
In the Features tab, Concepts and Shadow Concepts should be set active in case you want to refine your results, but you have to test each time if the results make sense for your use case.
For Cross-Validation at least use 5-fold, depending on the bulk of training material, 10-fold is recommended for statistical soundness.
More documents will slow down the validation process for higher values.
For the Vocablulary Size in the Vectorizer settings, set a default value of 1000-5000, depending on the concepts to be taken from the thesaurus and number of documents.
Note
We strongly recommend that you do not use the bulk of all existing training documents for training the classifier!
Leave a rough estimate of about 10% for testing the trained classifiers, before you use them on new and unknown documents.
Use documents that fit your use case and that you know, as regards the category they belong into.
You will be able to evaluate the classifier's training results better, otherwise training may fail or be much more difficult.
The values in the Cross-Validation section are those of recall, precision and their mean, f1.
We strongly recommend aiming for a value of above 70% for all three.
In statistical machine learning procedures the concept of overfitting has been identified: it means that you would choose your training data so well fitted to the categories that the classifier will always reach the highest possible values for cross-validation. Yet, although high values may seem impressive, they could result in a classifier being trained too narrowly, thus predictions on future unknowns might not work well.
Train a Classifier - Algorithms and Settings Overview
Train a Classifier - Algorithms and Settings Overview
This section provides an overview of algorithms available for the PoolParty Semantic Classifier, their basic working and the settings and values you can use.
Use the Train a Classifier - Best Practices topic to get a short overview of what to aim at in setting up a Train Classifier.
Note
The algorithm information given here can only cover the bare minimum you need to know for a successful setup.
For a deeper understanding please refer to online resources and data scientist's knowledge bases.
For some details on the implementation in PoolParty, you may want to refer to Apache's Spark machine learning library documentation.
Name | Description | Available Settings | Values |
|---|---|---|---|
Logistic Regression | A specially used regression calculation model, where a categorical variable is used together with constant values. It is useful if you need to make statements as to the probability of an occurrence based on a number of constant statistical factors. Simply put it means that values accumulated over a period of time in the past ('regression') are used as a base for calculating the probability of future similar events. The settings available here influence the outcome additionally since the regression is complemented with two kinds of regularization: simple and advanced regularization make sure that prediction errors are avoided. |
| Defaults:
|
Linear Support Vector Machine (recommended) | Linear Support Vector Machine (LSVMs) algorithms are considered to be the most effective for classification tasks. They work by dividing training as well as classification data for the respective categories into two distinctly separated hyperplanes. They have an underlying calculation model that is particularly well-suited for categorizing and they are known to work best when possibles are most unlike the categories they are actually building on. |
| Defaults:
|
Decision Tree | As in some business management models this algorithm also is based on a tree model that offers several ways of reaching a result goal. This kind of classifier is a good choice if you want to do a multi-category classification. | n.a. | Values set by default. |
Gradient Boosted Tree | Boosting is the technique in machine learning where so-called weak learners among algorithms are combined and optimized to create a strong learner. The Gradient Boosted Tree is a special variant of this kind of algorithm. It combines decision tree algorithms for prediction and regression classification tasks to make the results of each combined with others more reliable and apt. | Max. Number of Iterations | Default: 10 |
Deep Learning (MLP) | Deep Learning algorithms are based on representational or feature based learning data. They are particularly well suited for classification tasks such as machine translation, speech recognition and natural language processing. This particular algorithm, the Multilayer Perceptron (MLP) Deep Learning, consists of three-layer nodes to help distinguish data that is not linearly separable. |
| Defaults:
|
Naive Bayes | They are algorithms which have been used for classification for quite some time now and belong to the baseline methods. They distinguish between texts belonging to one category or another on the one hand. On the other, they also use word frequency as a feature. The fact that they use linearly connected variables, without taking correlations into account characterizes this family of algorithms further. | n.a. | Values set by default. |
Random Forest | These algorithms are based on decision trees but extend that kind of calculation by combining a multitude of decision trees at training time and then providing results that are the mode of a class/category and/or the mean of the prediction. The advantage of random forest algorithms is their ability to correct overfitting to their training data set typical for decision trees. | n.a. | Values set by default. |
Note
Make sure to train the classifier well but also take care to avoid overfitting: the expression for statistical data models that mirror the training data in almost every single particular so the prediction would not work well on future unknowns.
Vectorization in a classifier is needed to make the results machine readable.
Parameter | Values |
|---|---|
Min. Document Frequency | Defines the value for the number of times a document occurs in validation. Default: 1.0 Recommended: 10 Allowed values: integer |
Min. Term Frequency | Defines the value for the number of times a term occurs in a document. Default: 1.0 Recommended: between 50-100 Allowed values: integer |
Vocabulary Size | Defines the amount of concepts taken from the thesaurus. Default value: 10000 Recommended values: 1000-5000, depending on the size of your thesaurus. |
Cross-validation is used to determine and predict the future results after training has completed. The parameters presented are those of recall and precision, their mean is f1.
We recommend to use a cross-validation level of at least 5-fold, an overall result for all three parameters of at least 70%.
Possible Levels |
|---|
10-fold |
5-fold |
3-fold |
No Validation |
Train Classifier - Available Features and Information
Train Classifier - Available Features and Information
After you have created a classifier, several options and information are available in the PoolParty interface. This section provides details about using them.
Train Classifiers have a number of tabs and functions special to them. Apart from being able to train a classifier you find its status information and the classifier documents here.
Classifier Configuration Tab
Status & Settings Tab
Features Tab
Classifier Documents Tab
Categories Section
Table Tab
Chart Tab
Train Classifier - Status & Settings Tab
Train Classifier - Status & Settings Tab
After you have accessed a train classifier using its node (1), you will first see the Status & Settings sub tab (2) inside the Classifier Configuration tab.
The following information and settings are available here:
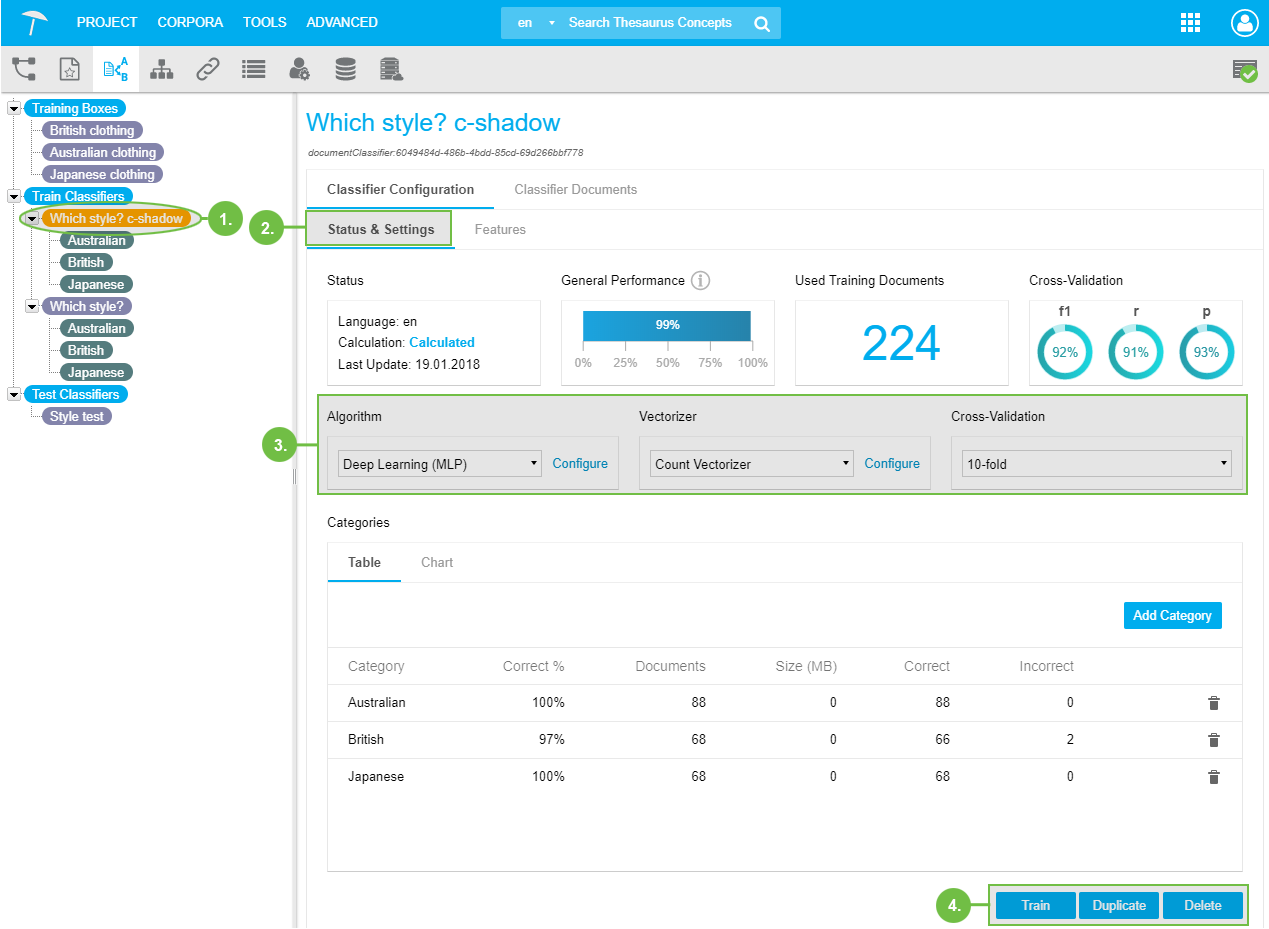 |
Status: displays status information on the classifier you have opened.
Language: language the classifier uses during calculation of results for the attached documents. Calculation: status information for the classifier, possible values are: New, Calculated, Outdated. Last Update: date of the classifier's last training run.
General Performance: indicates the usefulness of the training documents in general.
Used Training Documents: number of training documents attached to the classifier.
Cross-Validation: the three values for recall, precision and f1 (the first two's mean) are displayed for the opened classifier here.
Available settings for calculation of the Train Classifier (3).
Algorithm: select from the available algorithms, using Configure.
Vectorizer: set the parameters for the vectorizer, using Configure.
Cross-Validation: select the k-fold value for cross-validation from the drop down.
Set the algorithm, select the parameters, check on cross-validation values, set parameters for the vectorizer. Details find here: Train a Classifier and here: Train a Classifier - Algorithms and Settings Overview
The available functions here can be reached by clicking them (4):
Train: after having set the parameters, train the classifier.
Duplicate: create an exact copy of the train classifier currently opened.
Delete: delete the currently opened classifier.
PoolParty will ask you to confirm the deletion.
Train Classifier - Categories Section
Train Classifier - Categories Section
Inside the Status & Settings sub tab of a Train Classifier you find the Categories Section.
This contains the two tabs, Table and Chart. Find details on the available functions and information below.
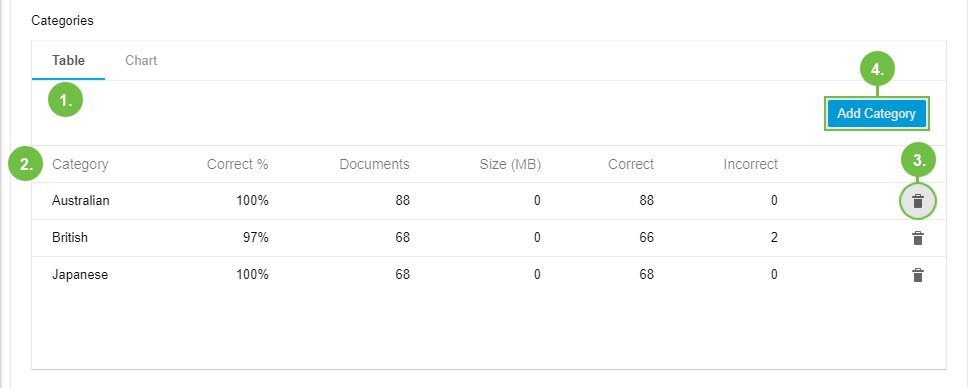
Inside the Table tab (1) you find the list of the classifier's categories. You can delete them from here, using the Delete icon (3), or add new ones using Add Category (4).
In the table itself (2) the following columns are available:
Category: categories' names
Correct %: the percentage of documents classified correctly in regard to the previous assignation you did.
Documents: number of documents assigned to that category.
Size (MB): size of assigned documents.
Correct: the number of documents classified correctly in regard to the previous assignation you did.
Incorrect: the number of documents classified differently in regard to the previous assignation you did.
In the columns shown below two documents in the 'British' category have been sorted into the 'Japanese' category by the classifier, differing from you previous assignation. Therefore they are displayed in 'British' as Incorrect.
 |
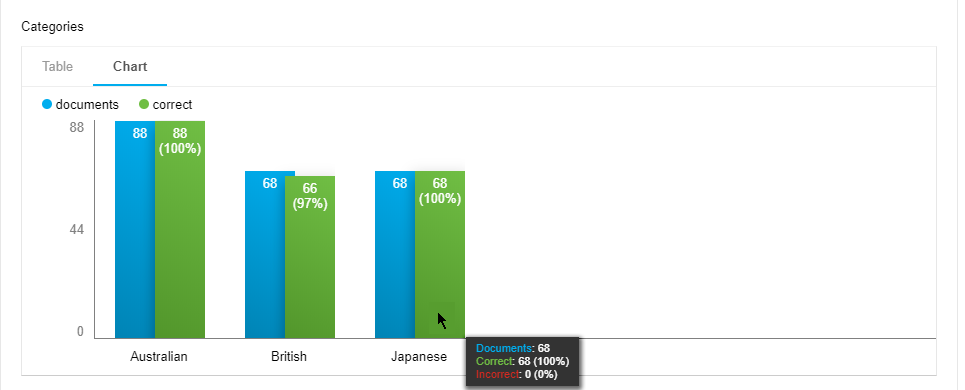
The Chart tab shows the table's values in a two-dimensional column chart image, the X-axis displaying the number of documents, the Y-axis displaying the categories.
The columns represent the total number of documents (blue) and the number of correctly assigned ones (green).
Hover your mouse over one of the chart's columns to display a context menu for additional details:
 |
Train Classifier - Features Tab
Train Classifier - Features Tab
The Features tab will be visible inside the Status & Settings tab and you can select it from there (1).
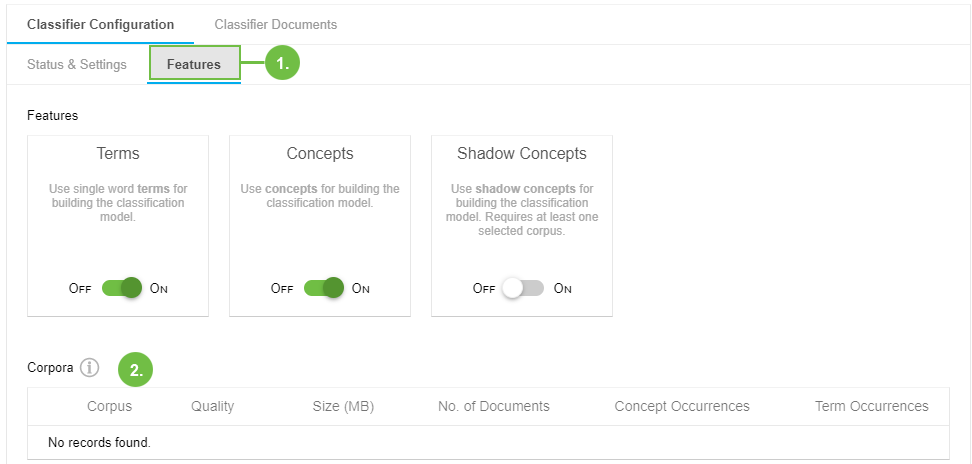 |
In its Features section you see the three options with sliders, Terms, Concepts and Shadow Concepts.
They determine details to be taken into account by the classifier once you added documents and selected an algorithm to use.
Terms is the default option turned on, as it refers to any terms occurring in your documents and related to your categories.
Concepts refers to the project's thesaurus. If you set this option to On, the concepts of your thesaurus will be taken into account during classification.
Shadow Concepts is the function PoolParty offers as a special feature, for the classifier too. It means that terms that frequently occur in the vicinity of your actual concepts are taken into special account as possible concepts, so-called 'shadow concepts'.
Note
Because of the machine learning algorithms' nature to learn and train as well as the complexity of possible results you have to find out in training your classifiers, which settings to use for best possible results.
The Corpora section (2) will display corpora and their quality if you have created any and also have let them be calculated in the Corpus Management.
The table columns refer to the values that relate to the corpus as such.
The corpora can be additionally part of the calculation as documents for training the classifier.
Train Classifier - Classifier Documents Tab
Train Classifier - Classifier Documents Tab
The Classifier Documents tab (1) is visible and can be accessed from the Status & Settings tab of a Train Classifier.
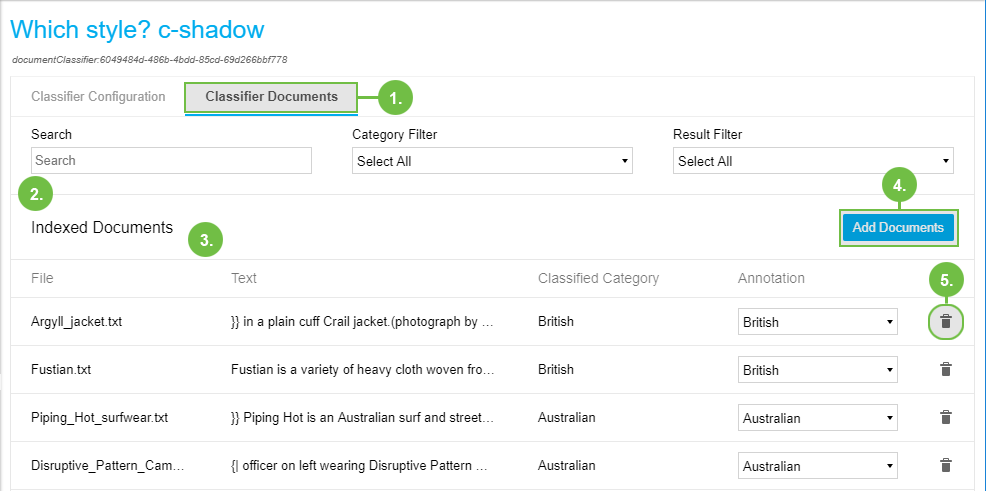 |
In the Search and Filter section (2) right below the tab you find these functions:
Search: enter a search term here to search for the name or string of documents. The list will be filtered by them.
Category Filter: from the drop down select from existing ones a category you want to filter for.
Result Filter: filter classified documents for Correct or Incorrect assigned categories.
In the table Indexed Documents (3) you see the documents attached to this classifier. Table columns here are:
File: file name of the respective document.
Text: the text the document contains.
Classified Category: the category the classifier assigned to the document.
Annotation: the category you assigned the document to originally.
You can use Add Documents (4) here to to open the Upload Documents dialogue.
Use the Delete icon (5) to delete individual documents.